Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


April 12, 2024
NTT Corporation
Realize LLM-based visual machine reading comprehension technology
~Towards "tsuzumi" that can read and understand visual documents~
Tokyo — April 11, 2024 — NTT Corporation (NTT) has realized LLM-based visual machine reading comprehension technology. Experimental results suggest the feasibility of artificial intelligence (AI) that can answer all kinds of questions based on document images, which is expected to be a core technology in digital transformation (DX).
These results have been adopted and introduced as an adapter technology for NTT's large language model "tsuzumi"1. The paper detailing these results was also presented at the 38th Annual AAAI Conference on Artificial Intelligence2 (AAAI-24, acceptance rate 23.8%), the top conference in the field of AI, held in Vancouver, Canada, from February 20 to 27, 2024. Additionally, the paper got the Outstanding Paper Award (top 2% of submitted papers) at the 30th Annual Conference of the Association for Natural Language Processing3 (NLP2024), held in Kobe, Japan, from March 11 to 15, 2024. Notably, this paper is the first to propose a specific methodology for LLM-based visual document understanding.
1. Background
Real-world documents contain text and visual elements (e.g., icons, diagrams, etc.), and come in various types and formats. To realize a technology that can read and understand the documents is one of the key challenges in the field of AI. On the other hand, the current AI, including large language models (LLMs), has made great progress, exceeding the ability of human reading comprehension, but it has a limitation that it only understands text information in documents. To solve this problem, NTT has proposed "Visual Machine Reading Comprehension Technology"4. As shown in Figure 1, we research and develop an AI technology that understands documents from visual information in the same way that humans do.
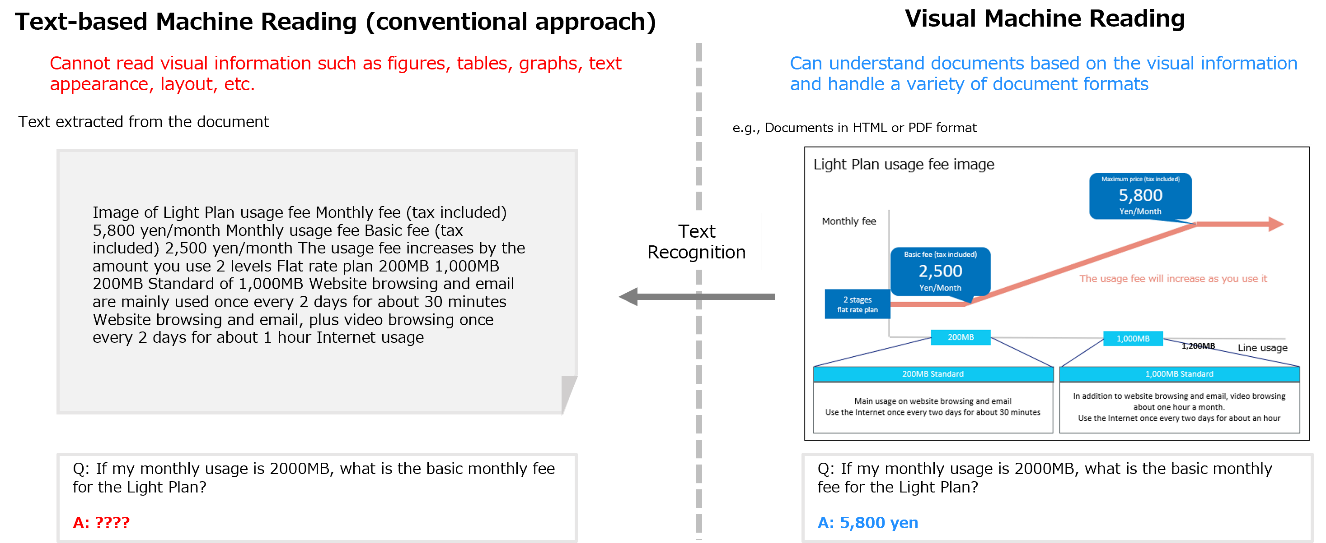 Figure 1 Comparison of Text-based and Visual Machine Reading Comprehension.
Figure 1 Comparison of Text-based and Visual Machine Reading Comprehension.
2. Research challenges
Previous visual machine reading comprehension techniques could not cope with arbitrary tasks (e.g., information extraction task on invoices). It was difficult to achieve high performance on a desired task without training on a certain number of samples. To this end, we aimed to realize a visual machine reading comprehension model that has high instruction-following ability as LLMs have. Specifically, a main challenge was how to endow LLMs with the ability of understanding visual information such as diagrams in document images as well as text.
3. Research results
We have developed a new visual machine reading comprehension technology that visually understands documents by utilizing the high reasoning ability of LLMs (Figure 2). To achieve this goal, (1) we developed a new adapter technology5 that can convert document images into LLM's representations, and (2) constructed the first large-scale visual instruction tuning datasets for diverse visual document understanding tasks. These enable LLMs to understand the content of documents by combining vision and language information and to perform arbitrary tasks without additional training. LLMs with our technology can be used for office works and daily life situations that require human cognition tasks, such as searching and screening documents, and assisting in reading specialized literature.
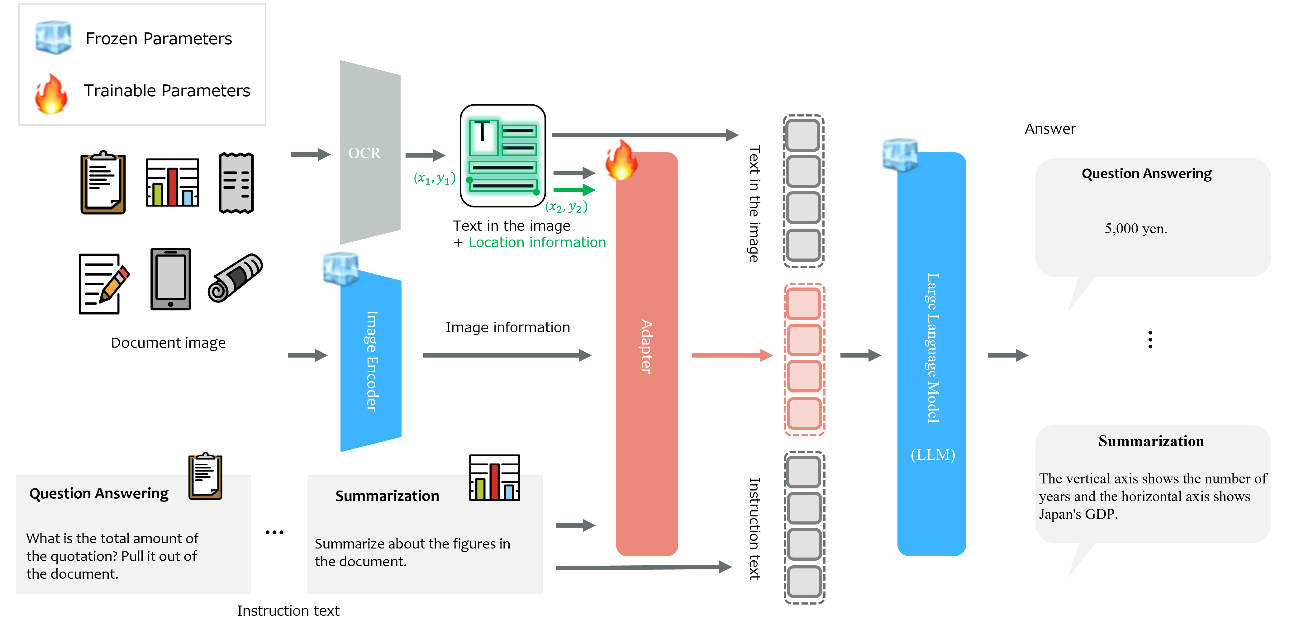 Figure 2 Overview of LLM-based Visual Machine Reading Comprehension Technology.
Figure 2 Overview of LLM-based Visual Machine Reading Comprehension Technology.
4. Key points of our technology
(1) Our adapter technology maps characters and their positions (coordinates) in images, image information that quantitatively expresses image features, and instruction text into the same space, and inputs them to an LLM. To train the model efficiently, we update only the parameters of the adapter, while keeping other large part of model parameters, including the LLM and image encoder. As shown in Figure 3, our adapter is a stack of Transformer6 architecture with a set of learnable tokens. These tokens interact with image features through cross-attention layers7 and with the input sequence (characters, location information, and instruction text) through self-attention layers7. This enables LLM to capture the multimodal features of document images as easily interpretable information.
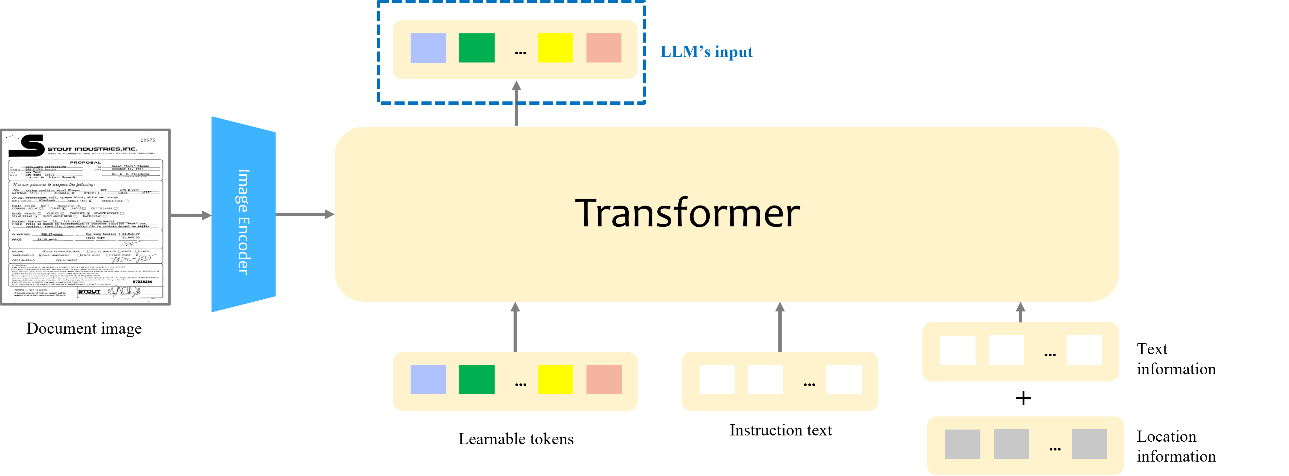 Figure 3 Details of Adapter Technology to Convert Document Images into LLM's Representations.
Figure 3 Details of Adapter Technology to Convert Document Images into LLM's Representations.
(2) We constructed the first large-scale visual instruction tuning dataset, which uses document images as a knowledge source. Our dataset spans 12 different visual document understanding tasks, including question answering, information extraction, and document classification based on human-written instructions. As shown in Figure 4, with these contributions, even without training target tasks8,9, our model matched or outperformed state-of-the-art models trained on the target task, open-sourced multimodal LLMs (e.g., LLaVA10), and powerful LLMs (e.g,, GPT-4 with text input).
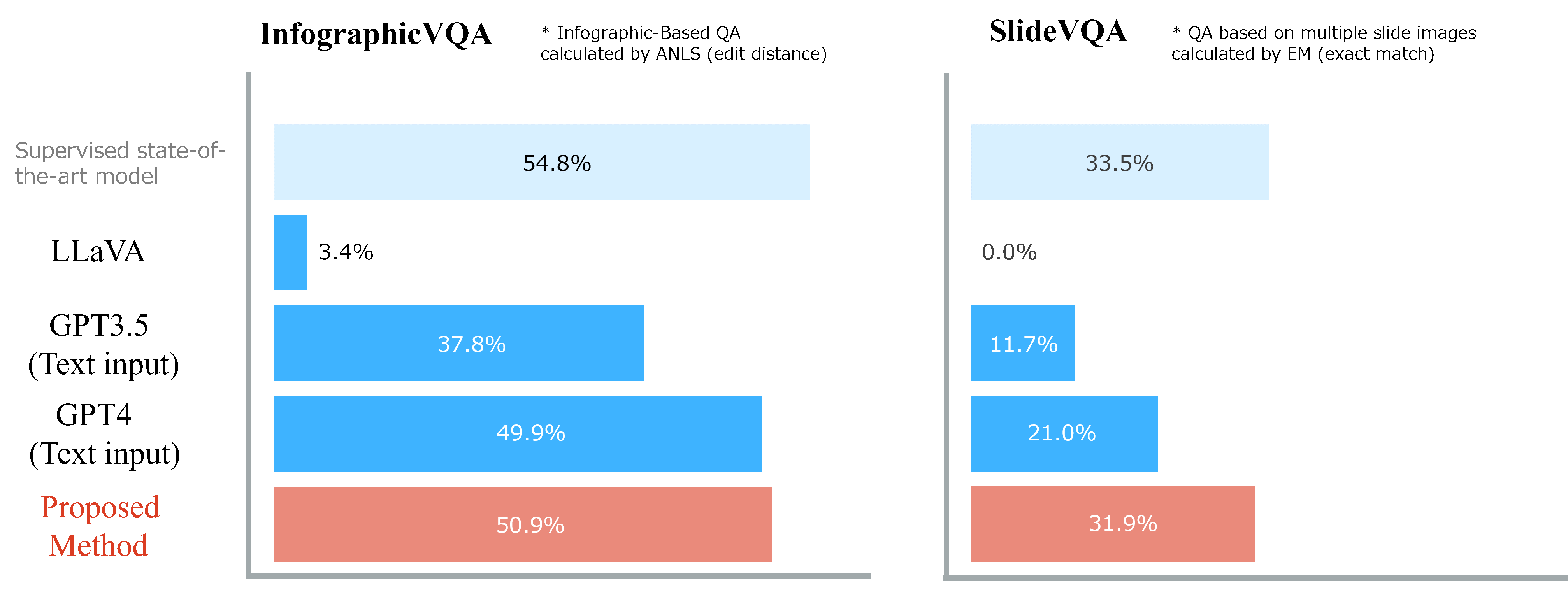 Figure 4 Benchmark Results of Visual Document Understanding in Unseen Tasks during Training.
Figure 4 Benchmark Results of Visual Document Understanding in Unseen Tasks during Training.
5. Status of research collaboration
This result is the outcome of joint research with Professor Jun Suzuki in Center for Data-driven Science and Artificial Intelligence Tohoku University in FY2023.
6. Future directions
This technology will contribute to the development of important industrial services such as web search and question answering based on real-world visual documents. We aim to establish the technology to realize AI that creates new values by collaborating with humans, including work automation.
1tsuzumi
NTT's large language model. A language model that enhances the ability of understanding and text generation in Japanese and is trained on a large amount of text data.
URL: https://www.rd.ntt/e/research/LLM_tsuzumi.html![]()
2AAAI
Top international conference on artificial intelligence
URL: https://aaai.org/aaai-conference/![]()
3Annual Conference of the Association for Natural Language Processing
The largest natural language processing conference in Japan
URL: https://www.anlp.jp/nlp2024/![]()
4Visual machine reading comprehension technology
A technology that captures a document as an image, understands and reads it from visual information.
5Adapter technology
A module that bridges image encoders and LLMs.
6Transformer
A type of neural network architecture that converts or modifies an input sequence into an output sequence.
7Cross-attention and self-attention
A mechanism for calculating where to pay attention to an input given two input sequences. If two given series are the same, it is called self-attention. Otherwise, it is called cross- attention.
8InfographicVQA
Question answering task for infographic (image that represents information, data, and knowledge).
URL: https://rrc.cvc.uab.es/?ch=17&com=evaluation&task=3![]()
9SlideVQA
Question answering task for multiple slide images.
URL: https://github.com/nttmdlab-nlp/SlideVQA![]()
10LLaVA
Large-scale model integrating visual and language.
URL: https://llava-vl.github.io/![]()
About NTT
NTT contributes to a sustainable society through the power of innovation. We are a leading global technology company providing services to consumers and businesses as a mobile operator, infrastructure, networks, applications, and consulting provider. Our offerings include digital business consulting, managed application services, workplace and cloud solutions, data center and edge computing, all supported by our deep global industry expertise. We are over $97B in revenue and 330,000 employees, with $3.6B in annual R&D investments. Our operations span across 80+ countries and regions, allowing us to serve clients in over 190 of them. We serve over 75% of Fortune Global 100 companies, thousands of other enterprise and government clients and millions of consumers.
Media contact
NTT Service Innovation Laboratory Group
Public Relations
nttrd-pr@ml.ntt.com
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






