Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


March 18, 2025
NTT Corporation
NTT Develops the World's First AI Algorithm for Deep Regression Models to Autonomously Adapt to Environmental Changes
Maintaining Deep Regression Models' Accuracy using only unlabeled data, such as sensor data, collected from test environments where AIs are deployed
TOKYO - March 18, 2025 - NTT Corporation (Headquarters: Chiyoda Ward, Tokyo; Representative Member of the Board and President: Akira Shimada; hereinafter "NTT") has developed a novel AI algorithm for deep regression models as a test-time adaptation technology. This technology enables the adaptation of deep regression models to environmental changes by updating a deep regression model to close the gap of feature distributions between the training and test environments. We expect that this contributes to reducing the costs of MLOps or AI data analytics and improving the performance of a variety of AI models, such as LLMs. The paper detailing these results will be presented at the International Conference on Learning Representations (ICLR) 20251, the top conference in the field of deep learning, to be held in Singapore from April 24 to 28, 2025.
Background
Regression, which predicts continual values from input data, is practically important since it has a broad range of applications in sensor data or time series analysis, and it is used in a variety of fields such as manufacturing, medical care, finance, and so on. Generally, deep learning models are put into practice in two phases: training in the training environment and inference on data collected from the test environment. Ordinary deep learning models assume that the training and test environments are identical; however, in practical use, the test environment changes over time, e.g., brightness or surrounding objects in image recognition or sensor degradation in sensing. Models degrade accuracy when data with different tendencies from training ones are fed. To retain the model's accuracy in the test environment, one could use data collected from the test environment for model training or construct a new dataset by annotating test data and re-training the models. However, these approaches are highly costly for annotation, and collecting test data in advance may be infeasible. We focused on the "test-time adaptation (TTA)" technology and addressed TTA for deep regression models.
Although TTA has been studied recently in classification, they assume models have classification-specific architecture. The primary approach of TTA for classification is to refine prediction confidence. Specifically, models must output prediction probability for each class (e.g., cat: 80%, dog: 10%, bird: 5%, etc.) for computing the confidence. On the other hand, ordinary regression models have no classes and output only single scalar values. Thus, we cannot apply existing TTA methods designed for classification to regression models since the confidence cannot be computed.
Research Results
We analyzed regression models' behaviors and found that intermediate feature vectors of a deep regression model tend to be concentrated only in a small subspace of the entire feature space. This behavior is different from that of classification models. Based on this finding, we developed a novel TTA method for regression that aligns the feature distribution of an unseen test environment to that of the pre-computed training one. We also showed that focusing on the subspace in which the features are distributed significantly improved the adaptation performance of regression models.
We compared our method with other adaptation methods on various regression benchmarks and demonstrated that our method constantly had higher adaptation performance. Figure 1 compares the adaptation performance on (1) the head pose estimation task from webcam person images and (2) the age estimation task from person face images. Our method consistently improved performance and is even competitive to ideal re-training using labeled data in some cases, while the baselines failed to recover the performance or even worsened the performance. Figure 2 depicts examples of the age estimation. The regression model without adaptation can accurately estimate the ages on clean images; however, it outputs inaccurate estimations on noisy images. On the other hand, the regression model adapted using our method recovers the age estimation performance.
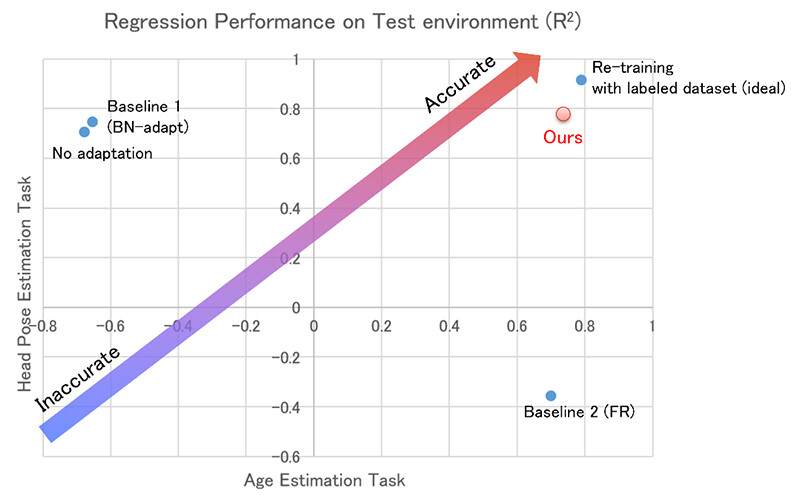 Figure 1 Performance Comparison on Adaptation Methods in the R2 Score
Figure 1 Performance Comparison on Adaptation Methods in the R2 Score
Note. A higher score indicates better performance.
 Figure 2 Examples of The Age Prediction Before and After Adaptation.
Figure 2 Examples of The Age Prediction Before and After Adaptation.
Note. Images are sampled from the UTKFace dataset2.
Technical Key Points
- Test-time adaptation by feature distribution alignment
A deep learning model's intermediate feature distribution will change from the training distribution when data is collected from a test environment that is different from the training one. We precompute the feature statistics using the training dataset and update the model to align the feature statistics of the test environment with those of the training environment. Our method can be used for regression models because it does not rely on the model's output form. - Leveraging "the valid feature subspace"
We found that many of the feature space dimensions remain unused (having no effect on the output), and naively adapting all the dimensions results in performance degradation. We detect "the valid feature subspace" and accurately align the feature distribution within the subspace. Our method significantly improves adaptation performance by prioritizing the important feature subspace.
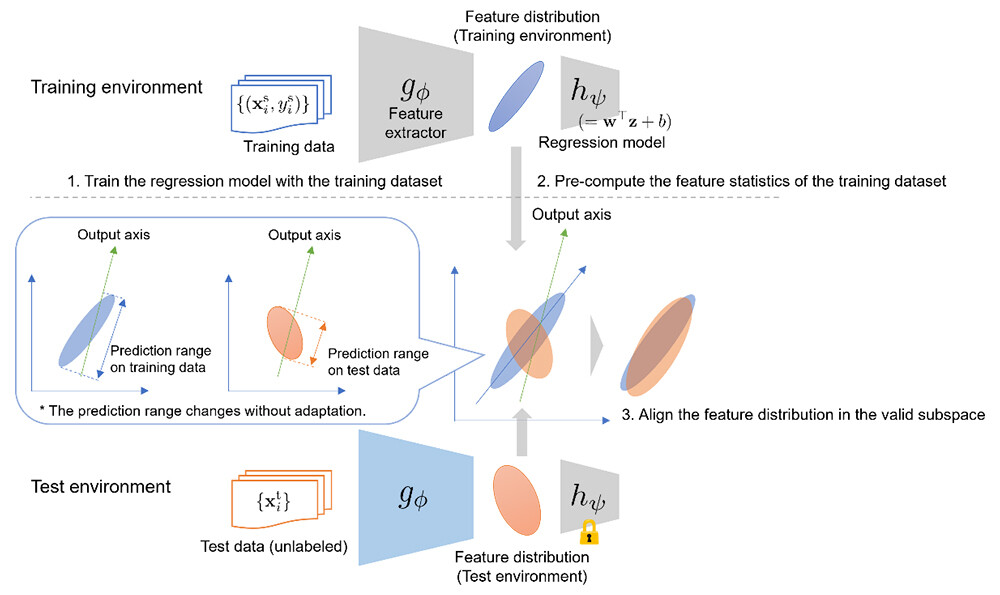 Figure 3 Overview of Our Method
Figure 3 Overview of Our Method
Outlook
This research has enabled TTA for regression, which is unexplored and practically important. We can apply our method to data analysis AIs in various fields, such as manufacturing, medical care, finance, etc., to alleviate performance degradation caused by environmental changes since it does not rely on output forms of deep learning models, which can significantly reduce costs in MLOps. We will contribute to expanding the field of AI application, not limiting it to regression, such as changes in weather and sensor degradation in multimodal foundation models.
Presentation
This research will be presented at the International Conference on Learning Representations (ICLR) 2025, the top conference in the field of deep learning, to be held in Singapore from April 24 to 28, 2025.
Title: Test-time Adaptation for Regression by Subspace Alignment
Authors: Kazuki Adachi, Shin'ya Yamaguchi, Atsutoshi Kumagai (NTT Computer and Data Science Laboratories), and Tomoki Hamagami (Yokohama National University)
URL: https://openreview.net/forum?id=SXtl7NRyE5![]()
1ICLR 2025
One of the top conferences on deep learning.
URL: https://iclr.cc/Conferences/2025![]()
2UTKFace dataset
A public dataset for training and evaluating age estimation from face images.
URL: https://susanqq.github.io/UTKFace/![]()
About NTT
NTT contributes to a sustainable society through the power of innovation. We are a leading global technology company providing services to consumers and businesses as a mobile operator, infrastructure, networks, applications, and consulting provider. Our offerings include digital business consulting, managed application services, workplace and cloud solutions, data center and edge computing, all supported by our deep global industry expertise. We are over $97B in revenue and 330,000 employees, with $3.6B in annual R&D investments. Our operations span across 80+ countries and regions, allowing us to serve clients in over 190 of them. We serve over 75% of Fortune Global 100 companies, thousands of other enterprise and government clients and millions of consumers.
Media contact
NTT Service Innovation Laboratory Group
Public Relations
Inquiry form![]()
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






