Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


July 7, 2025
NTT, Inc.
NTT Develops "Plausible Token Amplification" a Technique to Improve Accuracy of LLM Responses While Safeguarding Sensitive Data
—Leveraging structured data to improve the accuracy of LLM responses in template-based automation, while mitigating the risk of data leakage from those responses—
News Highlights:
- We have developed a new method that improves the accuracy of LLM responses by leveraging the structured data such as inquiry logs while mitigating the potential leakage risks that their use in prompts could be inferred from LLM responses.
- We theoretically revealed how added noise to mitigate the leakage risks degrades the accuracy and, based on the theoretical findings, introduced a technique that improves the accuracy of LLM by highlighting important words.
- This technique is expected to promote the use of LLMs in fields such as healthcare, government, and finance, where careful handling of user-related data is essential by addressing the potential data leakage risks.
TOKYO - July 7, 2025 - NTT has proposed a method that improves the accuracy of LLM responses to new input by leveraging past user input-response pairs while mitigating their leakage risks, particularly suited for templated-based automation handling inquiries from general public. In automated responses using Large Language Models (LLMs), adding noise1 based on differential privacy2 is gaining attention as a way to mitigate leakage risks; however, this approach often degrades the accuracy of LLM responses. In this research, NTT is the first to theoretically reveal how the noise degrades the accuracy. On the basis of these theoretical insights, we developed a new method called Plausible Token Amplification (PTA), which generates new input-response pairs that improve rule inference while preserving differential privacy. By guiding the LLM focus on the important words through generated pairs, PTA achieves a better balance between accuracy and security. This achievement is expected to promote the practical and safe use of LLMs in fields such as healthcare, government, and finance, where handling user-related data requires both security and usability, by addressing the potential leakage risks.
This result will be presented at the highly competitive International Conference on Machine Learning (ICML) 20253, held in Canada from July 13 to 19, 2025.
Background
In-Context Learning (ICL) is a method that guides the responses of LLMs based on provided example sentences and is expected to be effective for automating structured inquiry responses. For instance, in LLM-based chatbots, providing past user input-response pairs (called demonstrations) like "Earphones not delivered → Shipping Request" as context allows the LLM to accurately classify new inquiries based on the response patterns among provided demonstrations and automatically generate appropriate template-based response. However, using past data as the context raises the privacy risks. In particular, by intentionally repeating an inquiry similar to a provided demonstration, a malicious user could statistically infer whether that demonstration was used as the context. As shown in Figure 1a, this kind of statistical leakage can occur even without directly disclosing confidential information itself, raising concerns for future LLM applications in multi-user environment.
To mitigate such statistical leakage risks in a structured data, a method called Differentially Private ICL (DP-ICL)4 has been studied, which adds word-level noise to demonstrations to ensure privacy (see Figure 1b). However, DP-ICL faces the challenge that this noise makes it difficult for LLMs to correctly capture common response patterns underlying the original demonstrations, resulting in a degraded response accuracy. To recover the degraded accuracy, a previous work empirically excludes irrelevant words from the candidate set used to generate noise-added demonstrations5, but its effectiveness remains theoretically unexplored.
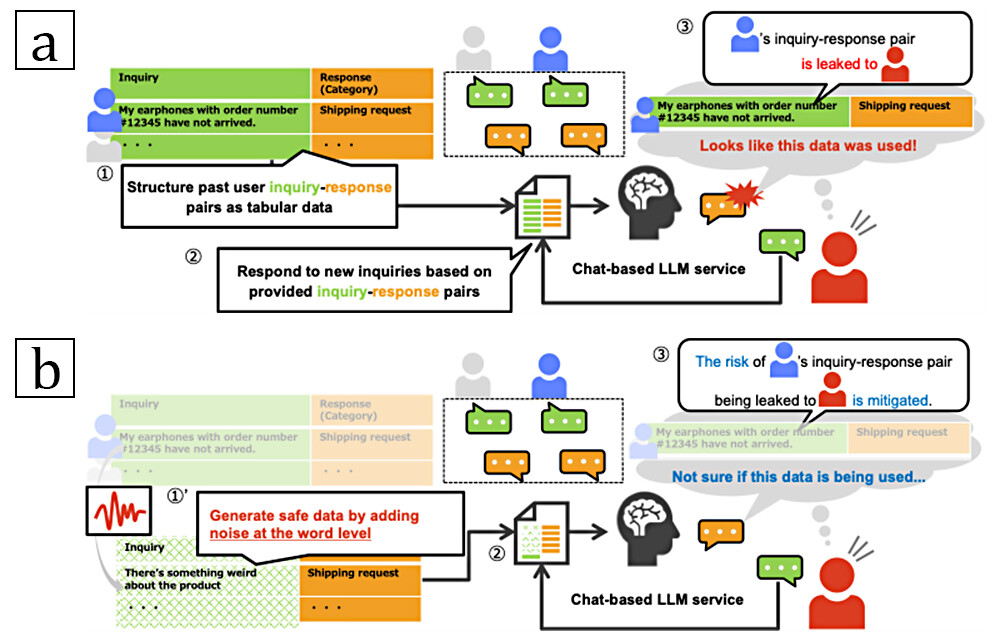 Figure 1 Leakage risks in In-Context Learning and Approaches to Mitigation.
Figure 1 Leakage risks in In-Context Learning and Approaches to Mitigation.
Note. a: Example of a service using in-context learning and the associated risk of sensitive information leakage
b: Illustration of how adding noise can reduce the risk of information leakage
Technical Highlights
In this research, we theoretically analyzed how the noise degrades the accuracy of LLM's responses in DP-ICL and proposed a new method to generate noise-added demonstrations that recover the degraded accuracy while preserving privacy. ICL can be viewed as a mechanism in which LLMs infer response patterns — latent rule that links inputs and their responses — based on demonstrations6. We investigated how noise affects this rule inference within a Bayesian framework, and identified two key techniques that improve accuracy:
- Technique 1: We theoretically revealed that limiting the candidate words for generation can mitigate the negative impact of noise on the rule inference. This provides a theoretical foundation for prior empirical remedy that improved accuracy by excluding irrelevant word candidates.
- Technique 2: We showed that increasing the generation probability of words that characterize the rule allows LLMs to infer correct rules more accurately—even from noise-added demonstrations. This finding suggests a new direction for improving response accuracy in DP-ICL, which had been overlooked in prior work.
For example, in response to the input "My earphones with order number #12345 haven't arrived," the correct classification would be "Shipping Request." However, if noise is added to the demonstration, it may be transformed into an ambiguous sentence like "There's something weird about the product → Shipping Request." Although this sounds natural, words like "product" or "something" provide little information for classification, and informative words like "earphones" and "not arrived" become obscured. As a result, when the user later inputs "The product arrived damaged," the model may mistakenly classify it as "Shipping Request" instead of "Return Request," due to incorrect rule inference.
To address this, Technique 1 ensures stable rule inference by excluding uninformative words such as "something" from the generation candidates in advance. Furthermore, Technique 2 increases the generation probability of informative words like "not arrived" or "broken," enabling the LLM to more accurately infer rules such as "Shipping Request" or "Return Request," even when noise is applied.
Based on these theoretical insights, we proposed a new differentially private demonstration generation method called Plausible Token Amplification (PTA). PTA suppresses the generation of irrelevant terms while amplifying the generation probability of rule-relevant words, and then applies noise to generate privacy-preserving demonstrations. PTA enables the LLM to infer correct rules with high accuracy even from noise-added demonstrations, thereby achieving both privacy protection and response accuracy.
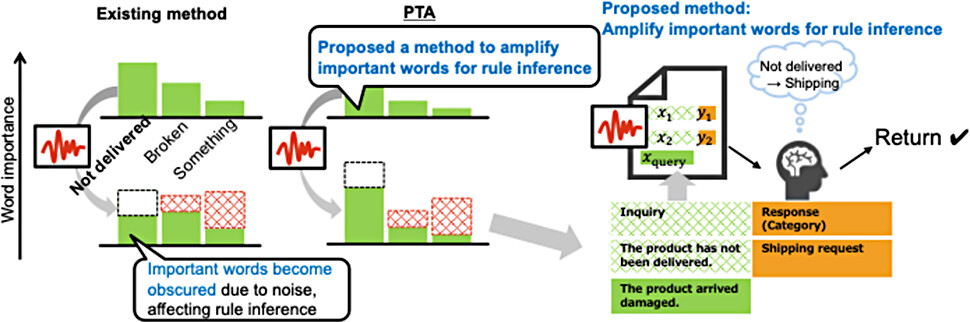 Figure 2 Overview of the Proposed Method: PTA.
Figure 2 Overview of the Proposed Method: PTA.
Note. Left: Emphasis on important tokens
Right: Accurate rule inference leading to improved response accuracy
To validate the effectiveness of PTA, we conducted a benchmark task in which news articles were classified into topic categories such as sports and world affairs. Compared with existing DP-ICL methods, PTA demonstrated improved accuracy, and we also confirmed that it achieved performance comparable to ICL without noise (Figure 3).
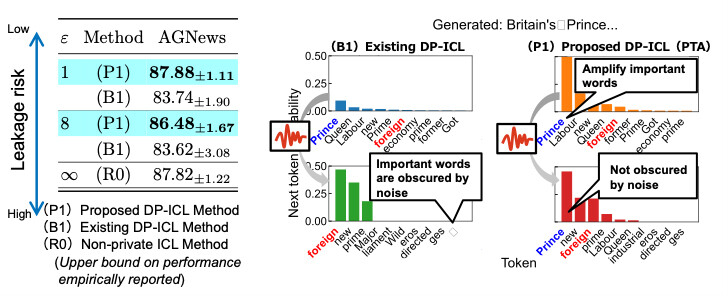 Figure 3 Evaluation Results on a Text Classification Task.
Figure 3 Evaluation Results on a Text Classification Task.
Note. Left: Comparison of benchmark accuracy across methods under varying levels of privacy strength ε7, as defined by differential privacy (lower ε indicates stronger privacy and lower leakage risk).
Right: Example of a news article introduction generated by PTA, for the "World Affairs" category.
The proposed PTA method is designed to mitigate statistical leakage where new users infer whether specific demonstrations—such as inquiry histories—were used as context. This statistical leakage can raise serious privacy concerns, in multi-user environments such as LLM-based automated response services, even if the LLM's response does not directly disclose sensitive information. By mitigating the risk of being inferred, PTA helps enable safer data utilization by obscuring the presence of individual demonstrations.
It should be noted that PTA does not deterministically guarantee that the LLM's response contains no confidential information. Instead, its primary focus is to make it statistically difficult to infer whether a specific inquiry was used.
Future Outlook
Moving forward, we aim to enhance the word amplification mechanism used during generation, enabling the generation of demonstration that maintains high response accuracy while mitigating potential future risks of statistical leakage. This will pave the way for broader application of LLMs in fields such as healthcare, government, and finance, where handling user-related data requires both security and usability.
Currently, PTA assumes a fixed structured format for input-response pairs (e.g., inquiry and category). In the future, we plan to extend the method to tasks involving more flexible input structures. This includes real-world use cases such as free-form inquiries and multi-label classification. By doing so, we aim to support the development of LLM applications that are privacy-aware and adaptable to a wider range of practical domains while anticipating future risks of data leakage.
About the Presentation
This research will be presented at the Forty-Second International Conference on Machine Learning (ICML 2025), one of the most prestigious conferences in the field of machine learning, to be held from July 13 to 19, 2025.
Title: Plausible Token Amplification for Improving Accuracy Differentially Private In-Context Learning Based on Implicit Bayesian Inference
Authors: Yusuke Yamasaki (Social Informatics Laboratories), Kenta Niwa (NTT Communication Science Laboratories), Daiki Chijiwa (Computer and Data Science Laboratories), Takumi Fukami, and Takayuki Miura (Social Informatics Laboratories)
[Glossary]
1Adding Noise
A common method that satisfies (ε,δ)-Differential Privacy (DP) by adding noise to the output of statistical processing on a database, thereby limiting the influence of individual records on the results.
2Differential Privacy
A quantitative privacy framework based on the idea of indistinguishability—that is, the output of statistical analysis should not significantly change whether a particular record is present or absent in a structured database.
This indistinguishability is quantified by the parameters (ε,δ); smaller values indicate stronger protection, meaning that it is statistically more difficult to infer whether a particular record is included. Statistical processing that satisfies (ε,δ)-DP can therefore be seen as a method for mitigatinglimiting the leakage risk of data leakage.
3ICML 2025
One of the top international conferences in the field of machine learning.
URL: https://icml.cc/Conferences/2025![]()
4DP-ICL
DP-ICL is a method that satisfies Differential Privacy to In-Context Learning (ICL) using a structured database of example input-output pairs (e.g., inquiries and category labels).
It ensures that the output of ICL satisfies (ε,δ)-DP by addinginjecting noise into the output distribution when sampling and using examples from the database as context for the LLM. This makes it statistically difficult for third parties to determine whether a specific inquiry-category pair was used in the context.
5Prior Work on Empirical Accuracy Improvements in DP-ICL
Reference: Tang et al., "Privacy-preserving In-Context Learning with Differentially Private Few-shot Generation," ICLR, 2024.
URL: https://openreview.net/forum?id=oZtt0pRnOl![]()
6Prior Work on Theoretical Bayesian Analysis of ICL
Reference: Xie et al., "An Explanation of In-Context Learning as Implicit Bayesian Inference," ICLR, 2022.
URL: https://openreview.net/forum?id=RdJVFCHjUMI![]()
7Strength of Privacy (ε) Quantified by Differential Privacy
For example, Apple's iOS features such as predictive typing and dictionary learning guarantee ε=1~8.
URL: https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf![]()
About NTT
NTT contributes to a sustainable society through the power of innovation. We are a leading global technology company providing services to consumers and businesses as a mobile operator, infrastructure, networks, applications, and consulting provider. Our offerings include digital business consulting, managed application services, workplace and cloud solutions, data center and edge computing, all supported by our deep global industry expertise. We are over $90B in revenue and 340,000 employees, with $3B in annual R&D investments. Our operations span across 80+ countries and regions, allowing us to serve clients in over 190 of them. We serve over 75% of Fortune Global 100 companies, thousands of other enterprise and government clients and millions of consumers.
Media contact
NTT, Inc.
Service Innovation Laboratory Group
Inquiry Form![]()
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






