Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


December 14, 2015
NTT achieved top performance in a noisy speech recognition international challenge
-Advances in distortionless speech enhancement and deep-learning speech recognition techniques-
Nippon Telegraph and Telephone Corporation (NTT; head office: Chiyoda-ku, Tokyo, Japan; President and CEO: Hiroo Unoura) has achieved the highest recognition accuracy at CHiME-3, which is an international speech recognition challenge1. The challenge featured speech recognition in public noisy environments, including cafés, street intersections, public transport (buses) and pedestrian areas, recorded using a 6-channel tablet-based microphone array. The top score was achieved by distortionless speech enhancement2 and deep-learning speech recognition techniques.
NTT will present the details of its achievement at the 2015 IEEE Automatic Speech Recognition and Understanding Workshop3 (ASRU 2015) on December 13-17, 2015 in Scottsdale, Arizona, USA.
Background
In recent years, rapid advances in speech recognition techniques have been fueled by the progress of deep learning and widely used for voice-operable devices, including smartphones. Current speech recognition techniques are mainly used in relatively quiet environments. If we can use them even in public noisy environments, the usability of voice-operable devices will be largely extended. For this purpose, speech recognition techniques must be advanced.
To accelerate such advancement, the 3rd CHiME Speech Separation and Recognition Challenge (CHiME-3) has been organized this year. CHiME-3 addressed speech recognition in public noisy environments, including cafés, street junctions, public transport (buses) and pedestrian areas, recorded using a 6-channel tablet-based microphone array. This task was so challenging that the speech recognition accuracy with the current deep-learning speech recognition technique was only 66.6%. CHiME-3 gathered a great deal of attention; 25 worldwide research institutes participated.
Overview of achievement
Among the 25 submitted systems to CHiME-3, NTT's developed speech recognition system (Fig. 1) achieved the highest recognition accuracy: 94.2% (Fig. 2). NTT, which has been aware of the importance of noisy speech recognition for more useful voice services for many years, has established many advanced techniques for it. In addition to them, NTT newly developed distortionless speech enhancement and deep-learning speech recognition techniques and achieved the best performance system in CHiME-3.
Technical points
(1) Speech recognition unit
- Convolutional neural network and network in network4 (CNN-NIN) (Fig. 3), which has been effective for image processing. NTT employed CNN-NIN for speech recognition applications for the first time in the world and confirmed its effectiveness.
- Weighted finite state transducer-based recurrent neural network language model5 (WFST-RNN-LM) (Fig. 4), which considers the long context of a word sequence to achieve highly accurate speech recognition in a computationally efficient way.
With just this speech recognition unit, NTT achieved speech recognition accuracy of 84.4% (Fig. 2).
(2) Distortionless speech enhancement unit
The speech enhancement unit suppresses the noise and reverberant components, which are the main causes of the recognition performance degradation in noisy environments. A deep-learning speech recognition system is very sensitive to speech distortion, which is induced by speech enhancement pre-processing. To handle this issue, NTT has also successfully developed a distortionless speech enhancement technique, which can, in principle, suppress the noise and reverberant components without distorting the speech components in a recording (Fig. 5). By combining distortionless speech enhancement and the above speech recognition units, NTT improved its system's speech recognition accuracy to 94.2% for the CHiME-3 task.
Future plans
NTT will keep brushing up the newly developed technologies, aiming of introducing them into our speech recognition services around 2018. Future plans include performance assessment with fewer microphones and real-time implementation of the above techniques.
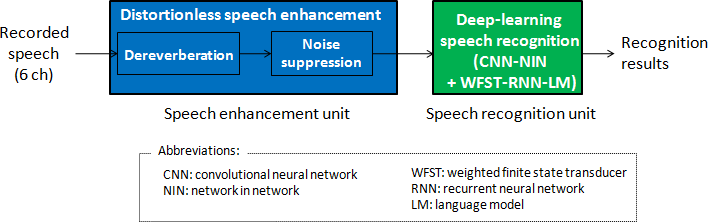 Fig. 1 Speech recognition system configuration
Fig. 1 Speech recognition system configuration
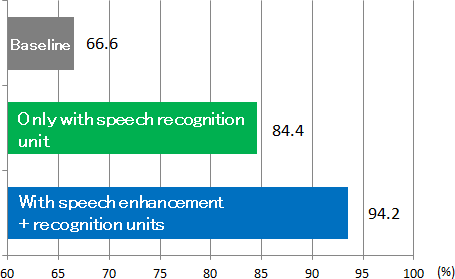 Fig. 2 Speech recognition results
Fig. 2 Speech recognition results
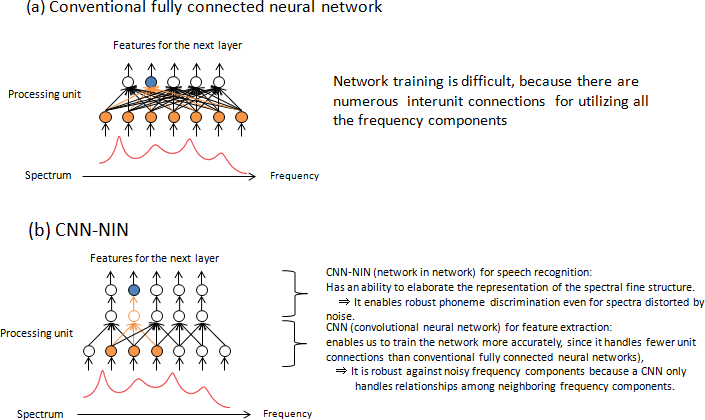 Fig. 3 CNN-NIN for speech recognition
Fig. 3 CNN-NIN for speech recognition
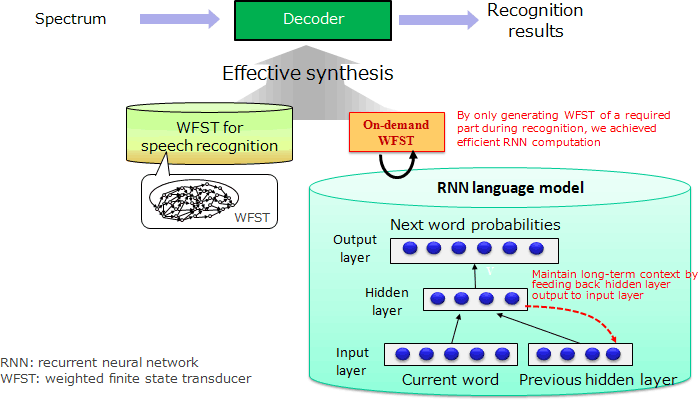 Fig. 4 WFST-RNN-LM
Fig. 4 WFST-RNN-LM
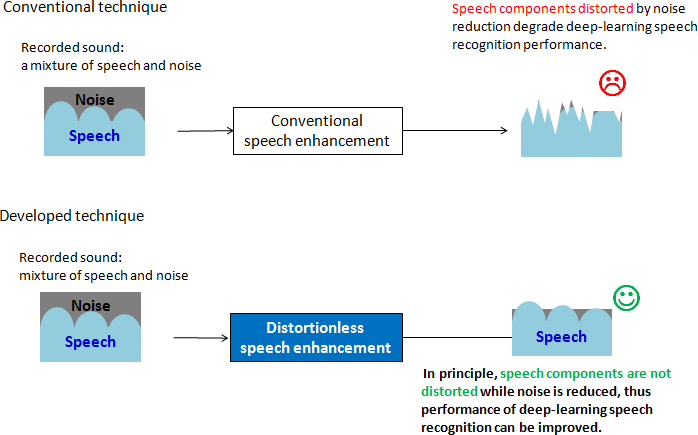 Fig. 5 Distortionless speech enhancement technique
Fig. 5 Distortionless speech enhancement technique
Notes
1The 3rd CHiME Speech Separation and Recognition Challenge (CHiME-3) is an international event whose goal is to accelerate the development of speech recognition techniques for noisy conditions. To foster research and development, it designs challenging speech recognition tasks that require epoch-making technologies. As suggested by its name, CHiME-3 is the third event in the CHiME challenge series, and it focused on speech recognition in public noisy environments using a 6-channel microphone array on a tablet. Many leading research institutes, universities, and companies have participated in CHiME-3 challenge. This task was so challenging that the speech recognition accuracy with the existing deep-learning speech recognition technique was only 66.6% (URL: http://spandh.dcs.shef.ac.uk/chime_challenge/index.html![]() ).
).
2This technique (Fig. 5) suppresses the noise and reverberant components and extracts speech signals under a distortionless constraint for speech components. The constraint is given by a mathematical model of sound propagation. In principle, if the model fits the sound propagation in a recorded situation, the technique does not cause speech distortion.
3At ASRU workshops, which are organized every two years by IEEE, leading researchers from many research institutes and companies discuss such state-of-the-art techniques as automatic speech recognition and spoken language understanding (URL: http://www.asru2015.org/default.asp![]() ).
).
4As part of CNN-NIN (Fig. 3), CNN is a neural network technique that extracts features by focusing on each local input region (Fig. 3(b). Since CNN handles fewer unit connections than conventional fully connected neural networks (Fig. 3(a)), it enables us to train CNNs more accurately. Moreover, because a CNN only handles relationships among neighboring frequency components, it is robust against noisy frequency components. CNN-NIN extracts features using a network stacked with a CNN. It enables robust phoneme discrimination even for spectra distorted by noise due to its ability to elaborate the representation of the spectral fine structure.
5This technique (Fig. 4) realizes computationally efficient and highly accurate speech recognition by considering a long-term word sequence context. Accurate word prediction based on RNN language model can be realized in a computationally efficient manner by a weighted finite state transducer (WFST).
Contact information
Nippon Telegraph and Telephone Corporation
Science and Core Technology Laboratory Group, Public Relations
a-info@lab.ntt.co.jp

Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






