Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


July 10, 2019
Nippon Telegraph and Telephone Corporation
A deep neural network trained for sound recognition acquires sound representation similar to that in mammalian brains.
- Brains may have acquired properties beneficial for sound recognition in the course of evolution -
Nippon Telegraph and Telephone Corporation (NTT, Head office: Chiyoda-ku Tokyo; President & CEO: Jun Sawada) discovered that a deep neural network (DNN) *1 trained for sound recognition acquires sound representation similar to that in a mammalian brain.
Years of neurophysiological studies have examined how neurons represent sound information in the brains of a variety of animal species. This study answers why a brain acquires such neural properties observed in these studies. We trained a DNN for natural sound recognition, and examined the properties of the units in the DNN by applying a method that is comparable to conventional techniques that neurophysiologists use to study animal neurons in experiments. As a result, we discovered that properties similar to the brain emerge in the DNN.
Our discovery suggests that a brain has acquired neural representation beneficial for the process of sound recognition in the course of its evolution. This study will further push the cooperation forward of the brain research and artificial intelligence. This has been published in Journal of Neuroscience. The publication was on July 10th.
Background
The brains of animals (mammals), including humans recognize a sound reaching the ear by processing and analyzing sound features at multiple stages from the brain stem to the cerebral cortex. Among sound features, amplitude modulation (AM) *2, a slow fluctuation of the amplitude waveform, is an important cue for sound recognition. Years of neurophysiological studies have revealed "how" neurons represent AM in multiple brain regions in the auditory nervous system (ANS) *3. However, the answer to "why" neurons represent AM in such a way has yet to be answered because it is difficult, in principle, to examine experimentally the relationship between neural properties and the process of evolution.
Simulation with a computational model can complement experimental approaches. However, conventional approaches with computational models can reproduce detailed properties of neural circuits for processing specific sound features only; they cannot explain how those properties are related to the whole process of natural sound recognition, which is an important function of the ANS.
Achievements
Recently, artificial neural networks (ANNs) have attained the ability to recognize natural and complex sounds. Our study exploited this ability to explore the answer to the "why" question (Figure 1). A deep neural network (DNN), a type of ANN, has a structure similar to the ANS in the sense that it consists of multiple cascading layers each consisting of numerous units. However, other than that cascading structure, our DNN is not intentionally designed to resemble any specific neural circuit in the ANS. (Connections between the cascading layers are initially random and modified by training for our tasks.)
If a DNN could acquire properties similar to those in animal brains as a result of training for animal-level natural sound recognition, this would suggest the possibility that such properties in animal brains are a consequence of their adapting for sound recognition in the course of evolution.
In the present study, we trained a DNN for natural sound classification and analyzed it with methods used to examine animal brains in neurophysiological experiments. Specifically, we fed sounds with various AM rates (i.e., speed of modulation cycles) to the trained DNN and examined outputs from the units in it (Figure 1). We found that properties comparable to those reported in previous studies on the animal ANS emerged in the DNN: Many units selectively responded to specific AM rates and the response characteristics changed systematically along the processing stages. We also found that properties similar to the brain gradually developed in the DNN in the course of the training and that DNNs with higher sound recognition accuracy exhibited higher similarity to the brain. In addition, we did not observe similarity to the brain in an ANN not trained for natural sound recognition.
These results suggest that animal brains have acquired the current form of neural representation of AM through adaptation for sound recognition in the course of evolution.
Future plans
There are various types of features for sound recognition other than AM. In the future, we would like to examine them and compare the sound representations acquired by trained DNNs with those in the brain. This will broaden our knowledge of the evolution of animal brains.
Publication information
Cascaded Tuning to Amplitude Modulation for Natural Sound Recognition Takuya Koumura, Hiroki Terashima,, Shigeto Furukawa Journal of Neuroscience 10 July 2019, 39 (28) 5517-5533; DOI: 10.1523/JNEUROSCI.2914-18.2019
Technical features
(1) Meta-analysis of previous neurophysiological studies
AM is an important cue for animals, including humans, to recognize sound (Figure 2), which is why a large number of physiological studies have investigated AM representation in neurons.
It is well known that most neurons respond by neural spikes (Figure 1, left) synchronously with AM waveforms of sound stimuli. Since the temporal patterns of spike firing represent AM, this coding scheme is called "temporal coding". There is an upper limit in the AM rate to which spikes can synchronize, which is called the upper cutoff frequency (UCF). Furthermore, some neurons strongly synchronize only to a specific AM rate. This property is called AM tuning, and the AM rate at the maximum synchrony is called the best modulation frequency (BMF). Generally, UCFs and BMFs tend to decrease along the axis from the peripheral brain regions to the central brain regions.
Regardless of neurons' synchrony to AM waveforms, the average response strength (firing rate) in some neurons changes depending on the AM rate. Such representation of AM with the firing rate is called "rate coding". Rate coding is a more abstract coding scheme than temporal coding in the sense that it does not transmit the shapes of AM waveforms directly. As seen in temporal coding, rate-coding neurons have their AM tuning and upper limits of the AM rate to which they fire. Rate-coding neurons exist only in the brain regions higher than a certain processing stage.
By meta-analyzing previous studies on neural activities, we visualized these properties in neurons, which enabled us to quantitatively compare these properties with AM representations in DNNs (Figure 3).
(2) DNN as a model of the ANS
Sound recognition is conducted in the ANS. The ANS of mammals, including humans, contains cascaded brain regions consisting of numerous neurons. In this sense, the ANS is analogous to a DNN because a DNN recognizes sounds with cascaded layers consisting of numerous units. The present study hypothesized that the ANS could be modeled by a DNN.
To maximize recognition accuracy, DNNs used for practical tasks such as sound recognition often take as inputs features derived by preprocessing sound waveforms. In addition, in scientific studies with auditory models, standard approaches use preprocessed signals that simulate outputs of the inner ear as inputs to the model. However, the hypothesis pre-determined by researchers dictates the choice of specific methods and the details of such preprocesses, which can affect the interpretation of the results.
The present study employed a DNN that takes as inputs raw waveforms without preprocessing and conducts generic sound classification tasks. In this way, we could simulate the all the stages of the ANS from the periphery to the central region in a unified model, with as little pre-determined hypothesis as possible. Specifically, the present study used a dilated convolutional network in which the temporal resolution of the signals is not degraded as they are processed in the layers.
We trained the DNN for natural sound classification. Natural sound classification is a suitable task for examining the general relationship between neural properties and animal evolution since it can be considered to be important for the survival for any animal species. After training, the ANN could classify natural sounds with good accuracy.
(3) Neurophysiological experiments in a DNN
To compare the AM representation in the trained DNN directly with the results of previous neurophysiological studies, we analyzed AM representations in the DNN with neurophysiological methods. Sounds with sinusoidal AM were fed to the DNN, and the response of each unit was measured, from which synchrony to the AM and the average activity were calculated (corresponding to temporal and rate coding, respectively). As a result, we found that properties similar to the ANS described above emerged in the DNN. These included the existence of units with AM tuning, the emergence of rate-coding units in the higher layers, and systematic changes in the BMFs and UCFs along the axis from the input to the output layers (Figure 4). Next, we quantified the similarity between regions in the ANS and layers in the DNN, and found that the entire cascade of the DNN layers were similar to the entire cascade of ANS from the periphery to the central region (Figure 5). This finding of sound representation in the entire cascade in the DNN in relation to that in the entire cascade of the ANS is the first of its kind.
We also found that DNNs with higher recognition accuracy tended to be more similar to the brain. These results suggest that properties in the ANS are effective for sound recognition.
From the perspective of machine learning, this study also implies the effectiveness of employing neurophysiological methods for analyzing DNNs. Although DNNs have the ability to recognize signals (such as sounds and images) with high accuracy, what representations they utilize to recognize them is still unclear. A variety of methods for analyzing data representation in ANNs have been proposed. Our study presents the possibility that methods that have been applied to examine sound and image representation in brains are applicable to DNNs.
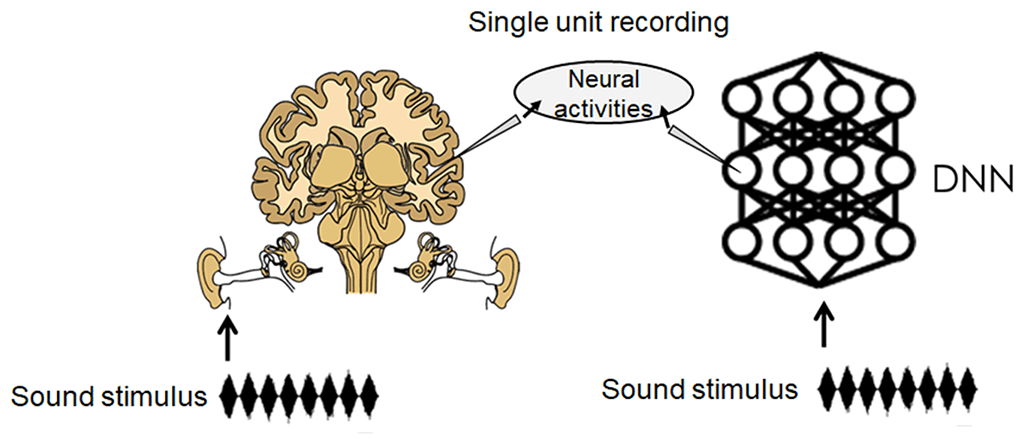 Figure 1: Illustration of our approach. Neurophysiological studies record activities in a single neuron in a brain (left). This study employed a DNN as a model of the ANS (right), and recorded activities in a single unit in response to a sound stimulus in a DNN trained for natural sound recognition.
Figure 1: Illustration of our approach. Neurophysiological studies record activities in a single neuron in a brain (left). This study employed a DNN as a model of the ANS (right), and recorded activities in a single unit in response to a sound stimulus in a DNN trained for natural sound recognition.
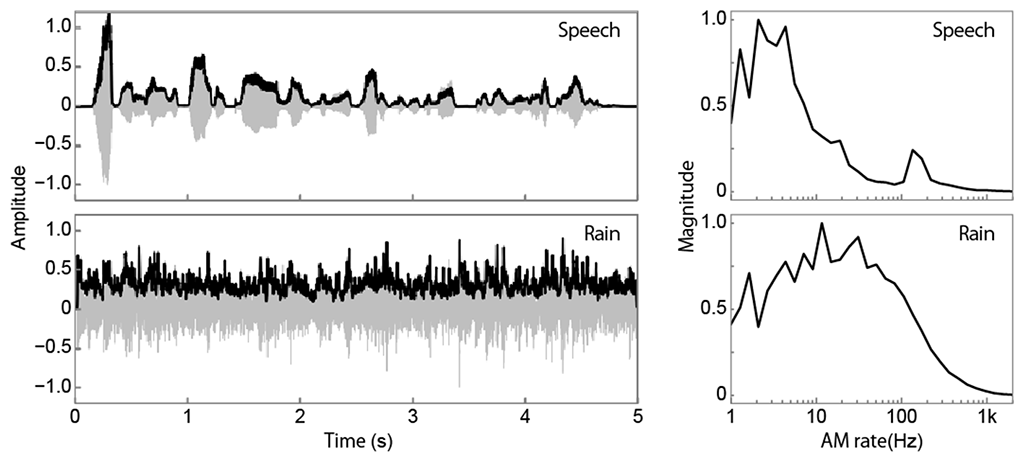 Figure 2: Examples of sound waveforms of speech and rain (left) and their AM spectra (right). Grey and black lines indicate sound amplitudes and their envelopes, respectively. Fluctuation of an amplitude envelope is called AM. An AM spectrum represents frequency components included in the AM.
Figure 2: Examples of sound waveforms of speech and rain (left) and their AM spectra (right). Grey and black lines indicate sound amplitudes and their envelopes, respectively. Fluctuation of an amplitude envelope is called AM. An AM spectrum represents frequency components included in the AM.
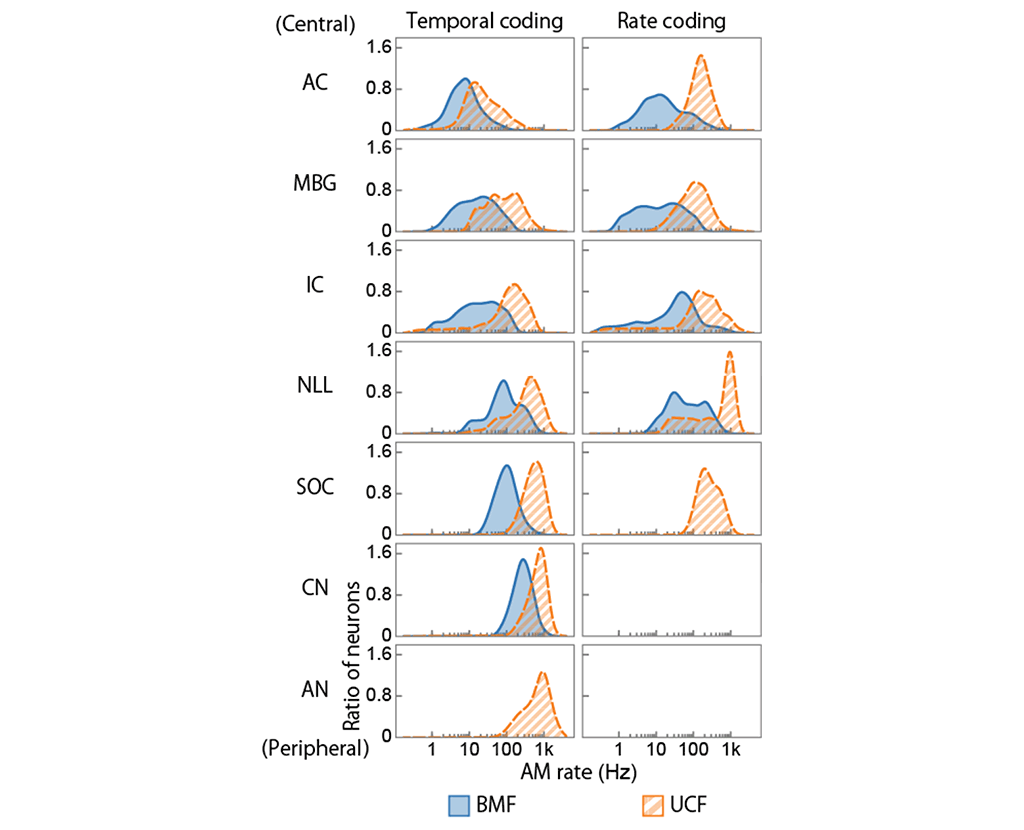 Figure 3: Distributions of BMFs and UCFs in the ANS visualized by meta-analysis of previous neurophysiological studies. For temporal coding, BMFs and UCFs gradually decrease from the periphery to the central region. For rate coding, neurons in SOC, NLL, and above represent AM rates with their average firing rate. ANS: auditory nerves. CN: cochlear nucleus. SOC: superior olivary complex. NLL: nuclei of the lateral lemniscus. IC: inferior colliculus. AC: auditory cortex.
Figure 3: Distributions of BMFs and UCFs in the ANS visualized by meta-analysis of previous neurophysiological studies. For temporal coding, BMFs and UCFs gradually decrease from the periphery to the central region. For rate coding, neurons in SOC, NLL, and above represent AM rates with their average firing rate. ANS: auditory nerves. CN: cochlear nucleus. SOC: superior olivary complex. NLL: nuclei of the lateral lemniscus. IC: inferior colliculus. AC: auditory cortex.
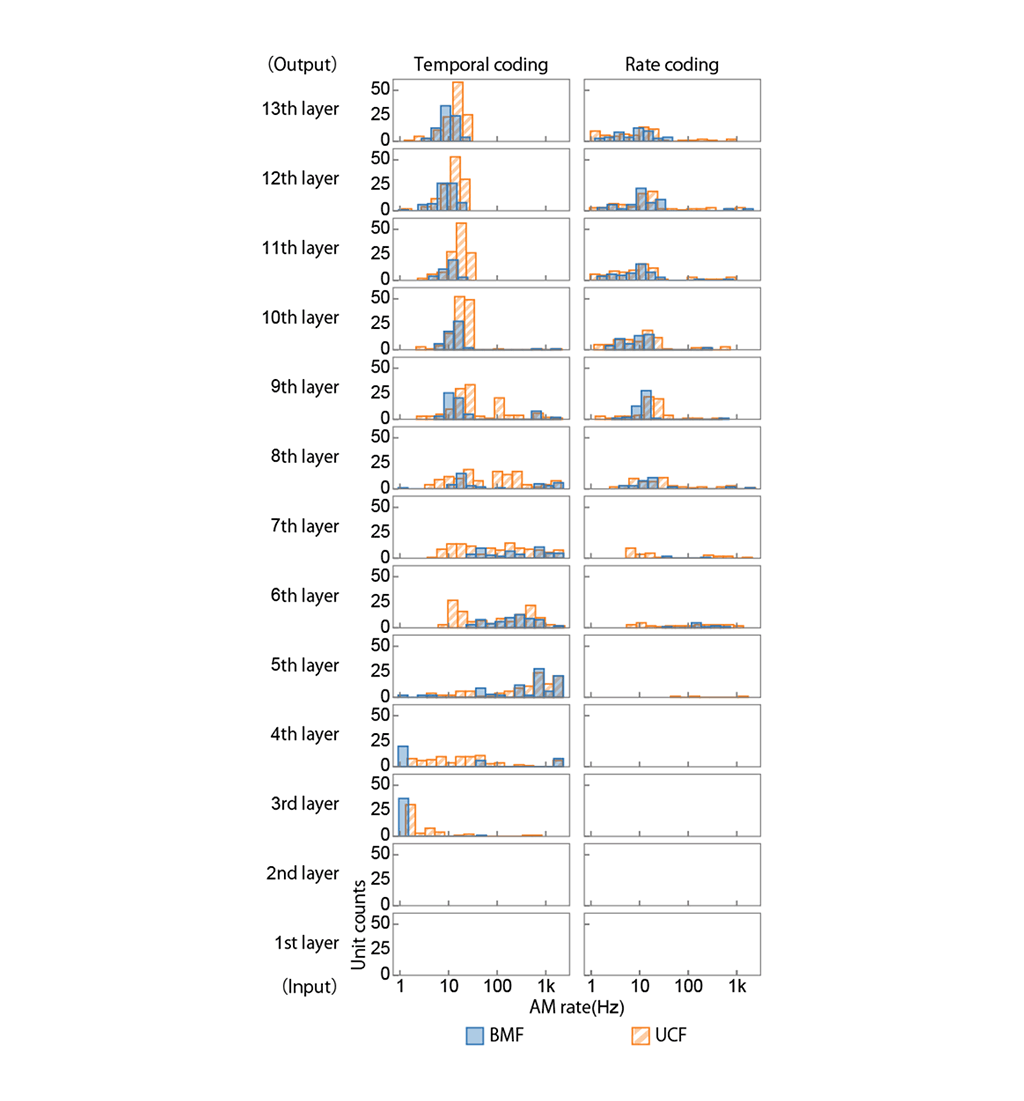 Figure 4: Distributions of BMFs and UCFs in the ANN. For temporal coding, BMFs and UCFs gradually decrease from the middle to the higher layers. For rate coding, units in the middle and higher layers represent AM rates with their average activities.
Figure 4: Distributions of BMFs and UCFs in the ANN. For temporal coding, BMFs and UCFs gradually decrease from the middle to the higher layers. For rate coding, units in the middle and higher layers represent AM rates with their average activities.
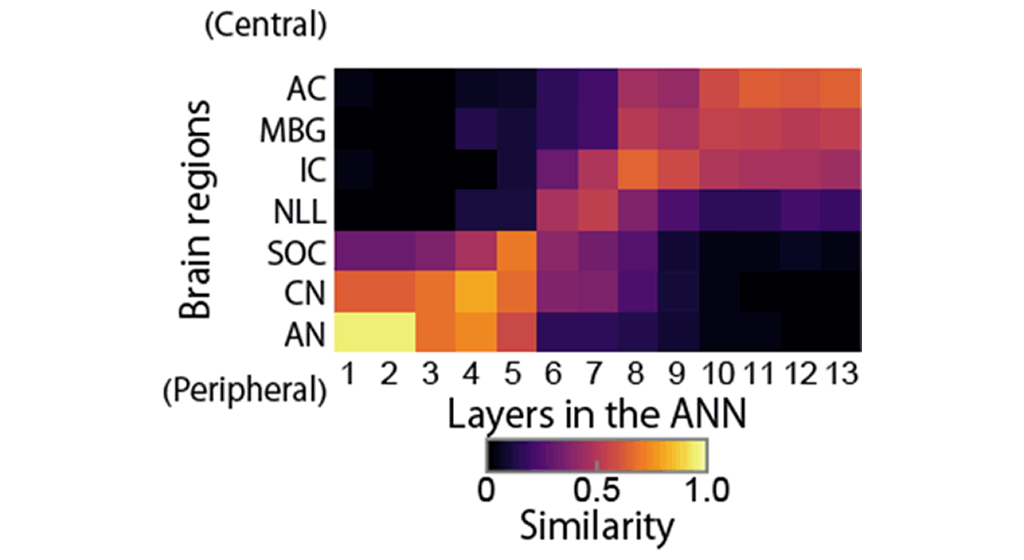 Figure 5: Similarity between brain regions and layers in the ANN. Lower layers in the ANN were similar to the peripheral brain regions, middle layers to the middle brain regions, and higher layers to the central brain regions.
Figure 5: Similarity between brain regions and layers in the ANN. Lower layers in the ANN were similar to the peripheral brain regions, middle layers to the middle brain regions, and higher layers to the central brain regions.
Glossary
- *1 Deep neural network (DNN)
- AN ANN is one of the machine learning models, and a DNN is a type of ANN. A DNN processes data with its cascaded layers consisting of numerous units. A unit in a layer takes as inputs activations of units in the layer beneath it, conducts simple operations, and transmits its output to the units in the next layer. This architecture was originally inspired by neural circuits in the brain. A DNN is suitable for simulating the ANS since the architecture and functions of the ANS are similar to those in the DNN. In this study, we analyzed each unit, assuming it to be a simulated neuron.
- *2 Amplitude modulation (AM)
- AM is a slow fluctuation of amplitude. It is often represented by the magnitude distribution (AM spectrum) for each AM rate, that is, the speed of the AM. AM is an important feature for sound recognition. For example, as long as the AM patterns are maintained, humans can recognize a sound to a certain degree even if the its fine structure is degraded. A common assumption among auditory scientists is that certain mechanisms in the ANS work to decompose the frequency of AM waveforms as the inner ear decomposes the frequency of a sound.
- *3 Auditory nervous system (ANS)
- The ANS is the neural circuit responsible for auditory perception. Sound vibrations are transformed into neural activities in the inner ear and transmitted to auditory nerves. Signals are processed in the cascaded brain regions and transmitted to the auditory cortex. It is considered that the auditory cortex further processes the signal in more complex ways to recognize the sound. Regions closer to the ear and cortex are called the "periphery" and "central" region, respectively. Each brain region consists of numerous neurons. This study divided brain regions from the periphery to the central region into the seven regions as shown in Figure 3.
- *4 Acknowledgements
- This study was conducted solely by NTT. This work was supported by JSPS KAKENHI Grant Number JP15H05915 (Grant-in-Aid for Scientific Research on Innovative Areas "Innovative SHITSUKSAN Science and Technology").
Contact Information
Nippon Telegraph and Telephone Corporation
Science and Core Technology Laboratory Group, Public Relations
science_coretech-pr-ml@hco.ntt.co.jp
TEL:+81-46-240-5157
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






