Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


September 2, 2019
Nippon Telegraph and Telephone Corporation
Secure computation for a typical training algorithm of a deep neural network - Enhancing AI with cryptography -
Nippon Telegraph and Telephone Corporation (NTT, Head office: Chiyoda-ku Tokyo; President & CEO: Jun Sawada) has developed a secure computation technology that enables model training with a deep neural network while training data is kept secret. The technique trains a model with encrypted data of data holders by using a typical training algorithm, including the softmax function *1 and the adaptive moment estimation (Adam) *2.
Usually, gathered data from data holders are encrypted on the network and a server; however, the data have to be decrypted when used as training data. This means that the server can easily access the data, so the data risks being disclosed. Therefore, careful data holders are disinclined to provide their secret data, such as confidential company data and data concerning personal privacy.
By using our secure computation technology, we can make use of such data through a deep neural network while the data is encrypted. In other words, the server can conduct all the four steps, (1) gathering, (2) storing, (3) training and (4) prediction, on encrypted data. Our technology provides a sense of security for data holders as well as data security and accelerates data sharing for machine learning. Therefore, we can use a large amount of data for model training and obtain an accurate prediction.
This result was published in the Forum on Information Technology (FIT) on September 3-5 and will be published in Computer Security Symposium (CSS) on October 21-24.*3
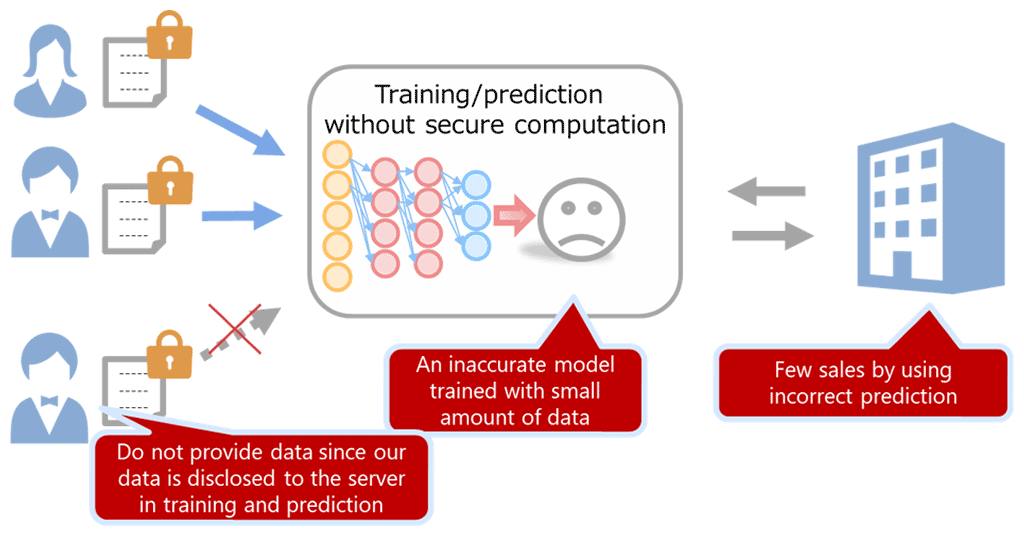 Training and prediction without secure computation
Training and prediction without secure computation
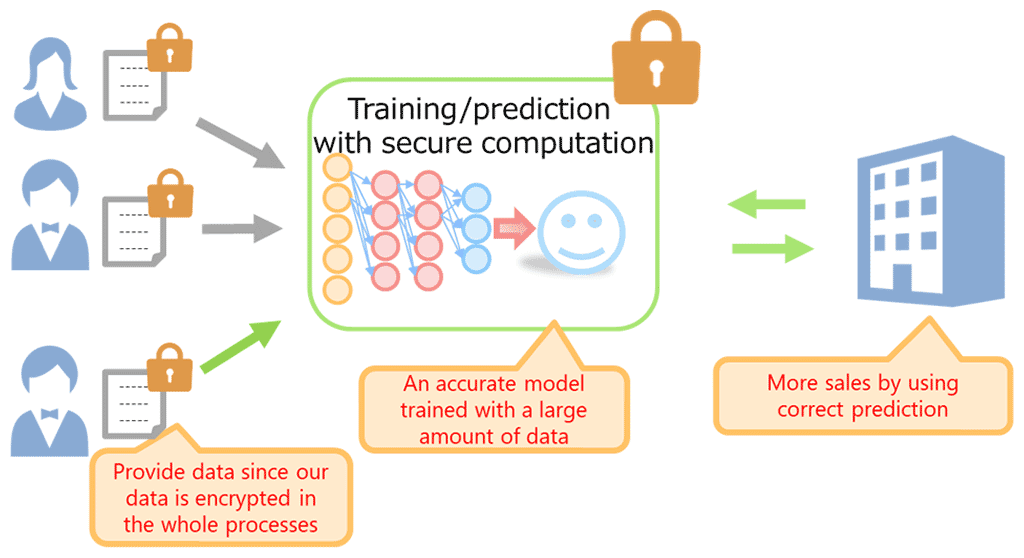 Training and prediction with secure computation
Training and prediction with secure computation
Background:
The accumulation, use, and application of cross-sector data in sophisticated data analysis, such as by artificial intelligence (AI), is expected to foster innovation and promote development and economic growth in diverse fields. However, the concern about security breaches and privacy risks has been emphasized, and this often becomes an obstacle for the usage of secret data.
NTT has researched and developed secure computation technology that can remove this barrier. Our secure computation technology enables data processing while keeping the data encrypted by secret sharing technology standardized by ISO/IEC.*4 By using this technology, the original data is never disclosed; therefore, secure computation technology allows the safe use of confidential data.
Here, we developed the first secure computation technology for a typical training algorithm of the deep neural network, a kind of AI algorithm used in practice. It encourages new applications by training of deep neural network with the secret data while maintaining data confidentiality. For example, a restaurant owner can optimize his stock and staff assignment in accordance with a model trained by using individual information, such as location and schedule, and public information, such as weather and surrounding events. We further expect that a doctor can rapidly and accurately diagnose malignancies in accordance with a model trained by X-ray radiography, CT scanning, MRI, and micrograph.
Technical Key Points:
Secure computation is a technology to compute a function on encrypted data; therefore, its procedure is quite different from that of a typical computer. Several functions are quick and easy to calculate for a regular machine but are time-consuming and difficult for secure computation. We refer to these functions as intractable functions. If you want to perform an analysis that includes those, a novel technique to handle that task is required.
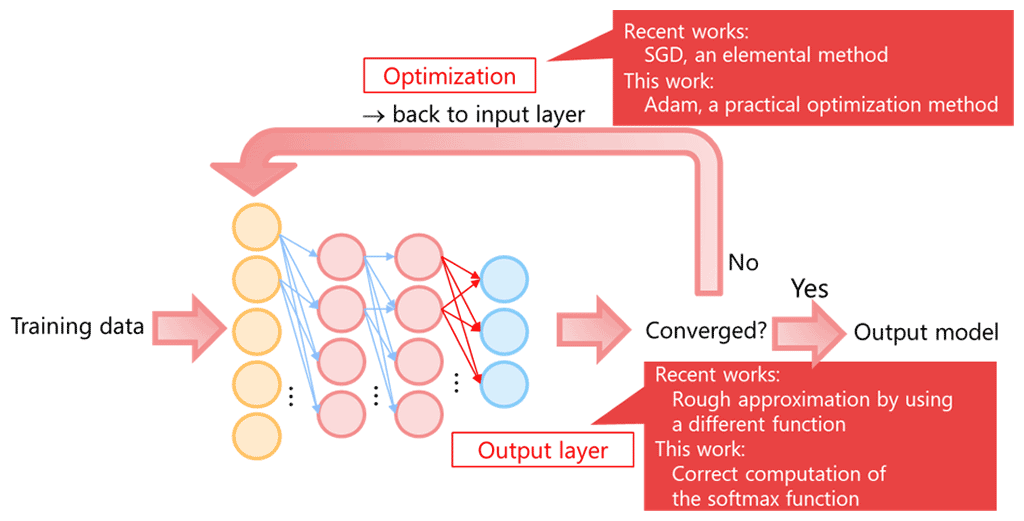
In general, training of a deep neural network proceeds as follows. The system has several layers, and some functions are sequentially computed on training data layer-by-layer. Then, a tentative output, which is parameters of the layers continues to the convergence test. If the tentative output is not converged, the parameters are updated by an optimization method, and the above processes will be repeated. The softmax function is a common function computed in the last layer. Adam is an optimization method improved from the stochastic gradient descent (SGD), which tends to incur many repetitions. Both the softmax function and Adam consist of division, exponent, reciprocal, and square root.
For secure computation, those four operations were intractable functions. Therefore, most recent works have focused on the prediction, which is lightweight compared to the training. Even in recent literature handling the training, the complex functions are roughly approximated by different functions, and SGD is used that is an elemental optimization method.
NTT invented novel techniques to rapidly and accurately compute those intractable functions, division, exponent, reciprocal, and square root, on the encrypted data. By using these techniques, we can calculate the softmax function and use Adam as an optimization.
We have two approaches to compute those four functions on encrypted data. One is using secure mapping. We first prepare many pairs of input and output of an intractable function in the clear. On an encrypted input, we can obtain the corresponding (encrypted) output while keeping the input secret. The other is proposing novel techniques that separately compute division, exponent, reciprocal, and square root.
We will present the former approach in FIT2019 and the latter one in CCS2019.
By using these inventions, we can train a model with encrypted data by a capital training algorithm of the deep neural network. For example, in our microbenchmark with the latter approach, training with 60,000 examples of handwritten digit *5 costs about five minutes per epoch.*6
Future direction:
NTT will try to substantiate the impact of this technology through experiments with AI experts. Finally, we will contribute to providing an environment in which anyone can safely supply and analyze both public and private data.
- *1Softmax function:
- A function computed in the output layer for classification. On input x, the function outputs y that in 0-1.
*1Softmax function:
A function computed in the output layer for classification. On input x, the function outputs y that in 0-1.
*2Adaptive moment estimation (Adam):
An optimization algorithm that is an improvement of an elemental optimization algorithm. Adam tends to output an accurate model [Ruder16], and is, therefore, used in several machine learning framework. You can find precise information in the literature [KB15].
[Ruder16] Sebastian Ruder, An overview of gradient descent optimization algorithms. arXiv:1609.04747, 2016.
[KB15] Diederik P. Kingma, Jimmy Ba, Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 2015.
*3Both publications are written and presented in Japanese.
*4ISO/IEC 19592-2 Information technology-Security techniques-Secret sharing-Part 2: Fundamental mechanisms.
*5MNIST database, http://yann.lecun.com/exdb/mnist/.![]()
*6In general, a training algorithm uses training data many times. One epoch means a processing unit that uses the training data once.
Inquiries regarding this press release
Nippon Telegraph and Telephone Corporation
Service Innovation Laboratory Group
Public Relations
Email: randd-ml@hco.ntt.co.jp
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






