Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


August 24, 2020
NTT Corporation
Asynchronous distributed deep learning technology for edge computing
~Model training technology even when vast amounts of data are held on distributed servers~
NTT Corporation (NTT) has achieved asynchronous distributed deep learning technology, which we call edge-consensus learning, for machine learning on edge computing. Recent machine learning, especially deep learning, generally involves training models, such as image/speech recognition, by aggregating data at a fixed location such as a cloud data center. However, in the IoT era, where everything is connected to networks, aggregating vast amounts of data on the cloud is complicated. More and more people are demanding that data be held on a local server/device due to privacy issues. Legal regulations have also been enacted to guarantee data privacy, including the EU's General Data Protection Regulation (GDPR). In current era, excitement is growing in edge computing that decentralizes data processing/storing servers for processing load and response time reductions on cloud/communication networks and for data privacy protection.
Our research is investigating a training algorithm to obtain a global model as if it is trained by aggregating data in a single server, even when the data are placed in distributed servers, such as in edge computing. Our proposed technology, which has both academic and practical interest, enables us to obtain a global model (a trained model that uses all the data at a single place) even when (1) statistically nonhomogeneous data subsets are placed on multiple servers, and (2) the servers only asynchronously exchange variables related to the model.
Details are presented from August 23 at KDD 2020 (Knowledge Discovery and Data Mining), an international conference sponsored by the Association for Computing Machinery (ACM) (16.9% acceptance rate). We also published the code associated with our achievement on Github for verification of our method effectiveness.
1. Background
In recent machine learning, especially deep learning, data are aggregated in a single place and a model is trained in the single place. However, due to the drastic increase in the amount of data as well as data privacy concerns, data will be collected in a distributed manner in the near future. For example, edge computing initiatives identify the decentralization of data collection/processing loads, and provisions in the EU's GDPR restrict the transfer of data across countries or require minimal data collection. A world in which we can benefit from machine learning without having to sacrifice data privacy is more desirable. One technical challenge for this goal is to make data aggregation/model training/processing decentralized manner (Fig. 1).
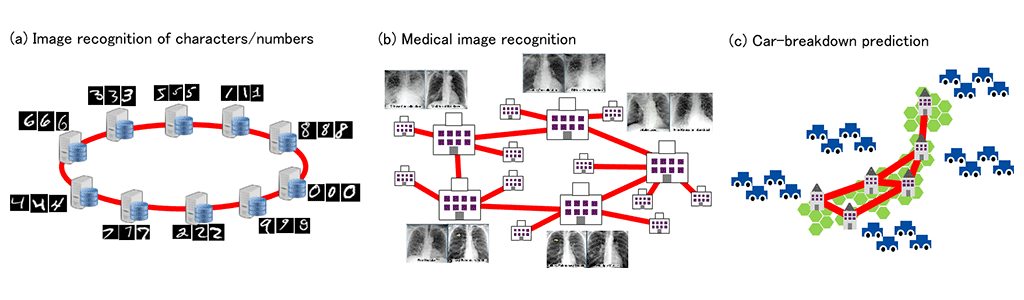 Fig. 1 Example applications and distributed data storage for edge computing
Fig. 1 Example applications and distributed data storage for edge computing
2. Key point
Our proposed training algorithm can obtain a global model even in situations where different/nonhomogeneous data subsets are placed on multiple servers and their communication is asynchronous. Instead of aggregating/exchanging data (e.g., image or speech) between servers, variables associated with each model trained on servers are asynchronously exchanged between servers and result in a global model. As shown in Fig. 2, the training algorithm is composed of two processes: a procedure that updates the variables inside each server (U) and a variable exchange between servers (X).
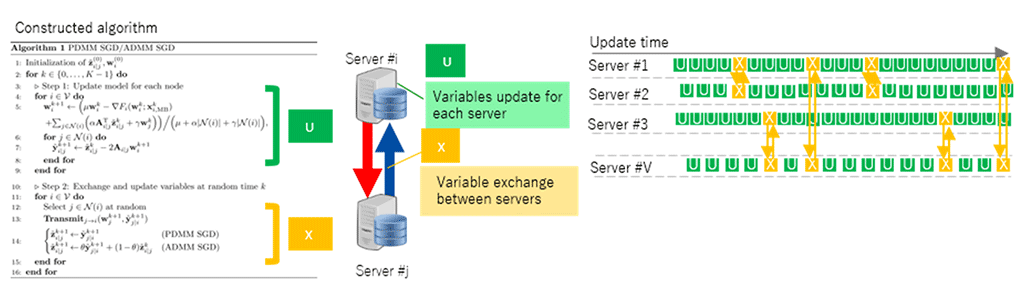 Fig. 2 proposed asynchronous distributed learning algorithm: edge-consensus learning
Fig. 2 proposed asynchronous distributed learning algorithm: edge-consensus learning
A part of our experiments is shown in Fig. 3. We used a ring network composed of eight servers. For each server, we used image data sets (CIFAR-10), where this is composed of ten classes of objects (e.g., plane, car, bird, cat). This image data set was divided into eight subsets, each of which was given to each server with statistical nonhomogeneous. Specifically, only five out of ten classes are placed for each server. When data subsets in eight servers are aggregated, a complete training data set with ten classes is recovered. The results of our simulation experiments show that a global model can be obtained even when using nonhomogeneous data subsets on asynchronous server communication.
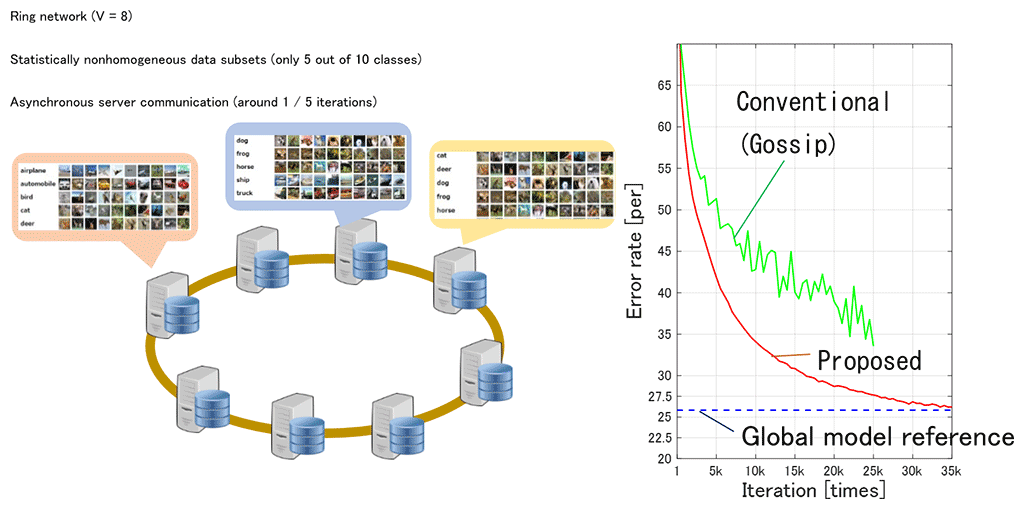 Fig. 3 Experimental results
Fig. 3 Experimental results
Fig. 3 Experimental results: To verify the effectiveness of our proposed method, we compared the following performances: the conventional gossip SGD method (green), our proposed method (red), and a global model where all the training data were used in a single place (blue). With the conventional gossip SGD method, the convergence behavior was unstable and failed to reach a global model reference score. In contrast, our proposed method eventually achieved a global model reference score.
3. Future work
We will continue research and development for commercialization. We will release the source code to promote further development of this technology as well as collaboration on applications.
Paper/source code publication
This research achievement is presented from August 23 at KDD 2020 (Knowledge Discovery and Data Mining), an international conference sponsored by the Association for Computing Machinery (ACM).
| Title: | Edge-consensus Learning: Deep Learning on P2P Networks with Nonhomogeneous Data |
|---|---|
| Authors | Kenta Niwa (NTT), Noboru Harada (NTT), Guoqiang Zhang (University Technology of Sydney), Bastiaan Kleijn (Victoria University of Wellington) |
We also published the source code associated with our achievement on following cite for verification of our method effectiveness.
For media inquiries,contact
■NTT Corporation
Science and Core Technology Laboratory Group, Public Relations
TEL: +81-46-240-5157
E-mail: science_coretech-pr-ml@hco.ntt.co.jp
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






