Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


May 7, 2024
NTT Corporation
NTT Data Mathematical System, Inc.
Development of a method to learn AI models with high accuracy even when some clients are anomalous or malicious in Federated Learning
Toward practical application to LLM tsuzumi training and IOWN functionality
Tokyo - May 7, 2024 - NTT Corporation (NTT) and NTT Data Mathematics System, Inc. (NTT Data Mathematics System) have developed a learning method that enables AI models to be learned with high accuracy even when some clients are anomalous or malicious, in which data is distributed among multiple clients (individuals or organizations) while maintaining the data. This is the most fault tolerant algorithm when there is statistical data bias among clients. When multiple participants learn using sensitive data such as personal information, federated learning that can safely learn while keeping the data at hand is attracting attention. However, it is known that when participants behave abnormally, the accuracy of the model obtained by federated learning deteriorates.
Momentum Screening Technology1 makes it possible to construct highly accurate AI models without assuming that all participants are normal, enabling safe and stable learning. This technology has been accepted at the International Conference on Learning Representation 2024 (ICLR 2024: May 7 - 11, 2024), one of the three top conferences in the field of machine learning, and will be presented in Vienna, Austria.
1. Background
In recent years, there have been great expectations to create new value by leveraging data across organizations and sectors. Examples include business DX using internal documents and building AI models to support medical diagnosis of rare diseases.
However, the data handled may contain personal or sensitive information, and data sharing between organizations has not progressed due to the risk of information leakage. Therefore, federated learning is attracting attention as a technology to create a single model that reflects the characteristics of each data by sharing the AI model learned using each data without sharing the data.
As shown in Figure 1, in federated learning, multiple clients learn a local model using their data, and the central server learns the AI model by repeating the process of creating a single global model (called a round) by averaging multiple local models and other processes.
![Figure 1 Comparison of Conventional Machine Learning (Left) and Federated Learning (Right) [Image source] What is federated learning? An easy-to-understand introduction to the basics of federated learning2](img/240507aa.jpg) Figure 1 Comparison of Conventional Machine Learning (Left) and Federated Learning (Right)
Figure 1 Comparison of Conventional Machine Learning (Left) and Federated Learning (Right)
[Image source] What is federated learning? An easy-to-understand introduction to the basics of federated learning2
One of the challenges of federated learning is that federated learning itself becomes difficult when some of the clients participating in the learning have abnormal or malicious intent share a learning model that is very different from the normal client. Just as in the absence of malicious clients, and the algorithm that achieves this is said to be Byzantine-tolerant. Byzantine fault tolerance is effective against degradation of training data quality due to mislabeling or measurement errors. It is also effective when an unspecified number of people participate in federated learning and malicious clients, such as client hijacking, are anticipated among them.
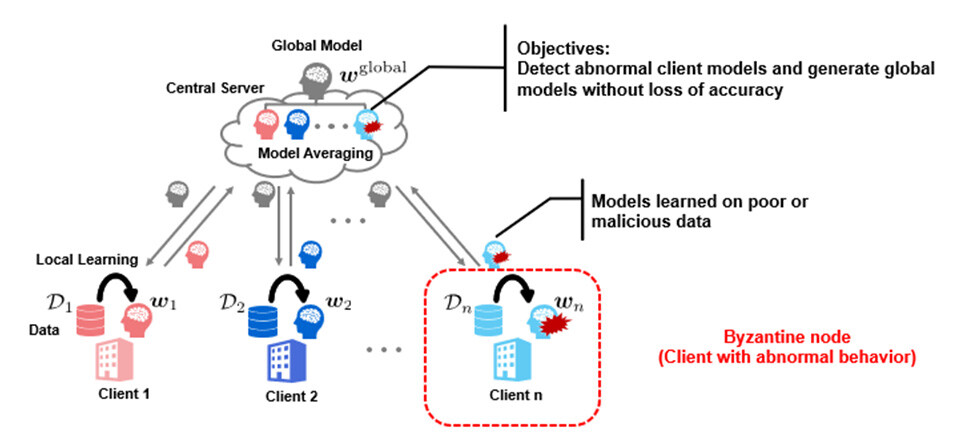 Figure 2 Image of Byzantine-Tolerant Federated Learning
Figure 2 Image of Byzantine-Tolerant Federated Learning
2. Results of the research
Byzantine-tolerant federation learning methods can reduce the accuracy of their methods to a small degree, regardless of what malicious clients do, as long as less than 50% of all clients engage in malicious behavior (e.g., sharing a learning model that is different from the actual one).
CClip3 is an existing Byzantine fault tolerant conventional method for federated learning. In each round of federated learning, this method uses an average estimate of normal client gradients (the direction of model updates) and compensates (clipping) it so that the effect of the gradient on all clients is reduced. This reduces the impact of malicious clients on the overall learning and gives them Byzantine fault tolerance. However, when the statistical nature of the data held by each client was very different, the learning of a normal client was affected by the correction as well as a malicious client, and the accuracy of the learned model is reduced.
This technology does not use the learning information from each round, but uses the learning information from previous rounds appropriately to determine normal and malicious clients, so that no correction is applied to the learning of normal clients and the accuracy of the overall learned model is not reduced. This allows for better models to be generated without reducing the accuracy of the overall learned model.
3. Key points of the technology
The key points of the momentum screening technology are as follows.
- Momentum: Learned using exponential averages of past gradients rather than gradients per learning
- Screening: Momentum of each client is compared with each other, and the ratio of close momentum is judged as normal if it is above a threshold value, otherwise it is judged as abnormal.
Momentum is to be used instead of gradient by adding the exponential average of past gradients and gradients as shown in Figure 3. Screening compares the momentum of each client as shown in Figure 4, and if the momentum is close to or above the threshold, it is judged as normal; otherwise, it is judged as abnormal. If not, the entire model is updated without using the information of the momentum that is judged as abnormal.
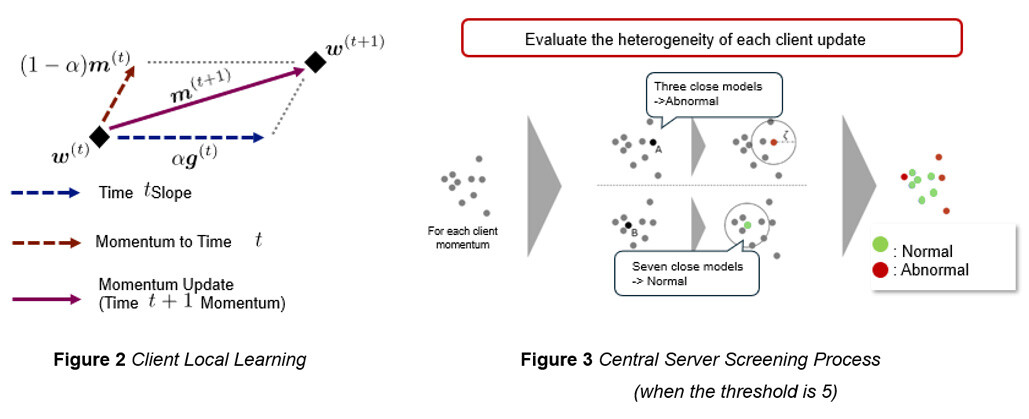
In this way, screening can be applied to momentum to learn models with high accuracy. In addition, mathematical proofs have confirmed that the proposed method can reduce the learning error compared to CClip in an objective function that assumes a statistical bias of data between common clients, and that there is no method that outperforms the proposed method4. In addition, as shown in Figure 5, through benchmark tests of image recognition, we have experimentally confirmed that in the presence of Byzantine nodes, the proposed method can learn models with higher test recognition rates than several conventional methods (including CClip) in worst-case comparisons for anomalous behavior.
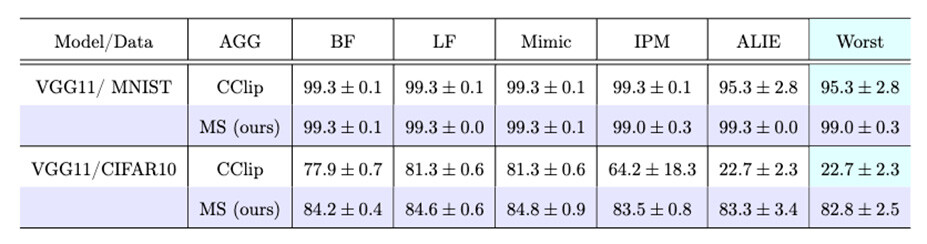 Figure 5 Measurement results of learning accuracy for each of five abnormal behaviors (columns) of each learning algorithm (rows)
Figure 5 Measurement results of learning accuracy for each of five abnormal behaviors (columns) of each learning algorithm (rows)
The Worst column shows the lowest learning accuracy among the five abnormal behaviors
4. Roles of each company
NTT: Devising Byzantine-tolerant algorithms
NTT Data Mathematical System: Verify the mathematical and simulation accuracy of the devised methods
5. Outlook
NTT and NTT Data Mathematical Systems will contribute to the promotion of the use of AI and other technologies using data that is distributed and accumulated across organizations through the development of federated learning technologies that are expected to provide both protection and utilization of information, and promote research on federated learning technologies through joint experiments and other means, We aim to apply this technology to LLM tsuzumi learning and to put it to practical use as a function of IOWN PETs5.
1T. Murata, K. Niwa, T. Fukami, and I. Tyou, "Simple Minimax Optimal Byzantine Robust Algorithm for Nonconvex Objectives with Uniform Gradient Heterogeneity," ICLR 2024.
[url] https://openreview.net/forum?id=1ii8idH4tH![]()
2What is federated learning? An easy-to-understand introduction to the basics of federated learning
[url] https://www.msiism.jp/article/federated-learning.html![]()
3S. P. Karimireddy, L. He, and M. Jaggi, "Byzantine-Robust Learning on Heterogeneous Datasets via Bucketing," ICLR 2022. [url] https://openreview.net/forum?id=jXKKDEi5vJt![]()
4Proof that the proposed method satisfies minimax optimality in the assumed class of objective functions. See Note *1
5IOWN PETs: [url] https://www.rd.ntt/sil/project/iown-pets/iown-pets.html![]()
About NTT
NTT contributes to a sustainable society through the power of innovation. We are a leading global technology company providing services to consumers and businesses as a mobile operator, infrastructure, networks, applications, and consulting provider. Our offerings include digital business consulting, managed application services, workplace and cloud solutions, data center and edge computing, all supported by our deep global industry expertise. We are over $97B in revenue and 330,000 employees, with $3.6B in annual R&D investments. Our operations span across 80+ countries and regions, allowing us to serve clients in over 190 of them. We serve over 75% of Fortune Global 100 companies, thousands of other enterprise and government clients and millions of consumers.
Media Contacts
NTT Service Innovation Laboratory Group
Public Relations
nttrd-pr@ml.ntt.com
NTT Data Mathematical System, Inc.
Public Relations
pr-info@ml.msi.co.jp
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






