Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


June 17, 2024
NTT Corporation
A generative AI that can instantly change your voice and speaking style
High-quality and low-latency real-time voice conversion
News Highlights:
- We developed a real-time voice conversion technology based on deep learning that achieves both high sound quality and low latency
- A newly devised voice feature extraction process with low speaker dependency ensures high sound quality, and unlike conventional methods, the model does not require a buffer for future speech signals, resulting in low latency
- This technology enables voice conversion in a variety of voice communications, whether face-to-face or remotely, and contributes to the realization of communication that is free from physical, intellectual, and psychological constraints, for example, converting the intonation and voice quality of a speaker into easy-to-understand speech at a call center
Tokyo - June 17, 2024 - NTT Corporation (Headquarters: Chiyoda Ward, Tokyo; Representative Member of the Board and President: Akira Shimada; hereinafter "NTT") has devised a technology to convert a speaker's voice into high-quality, low-latency speech as a voice and utterance from a different speaker (Figure 1). This makes it possible to utilize voice conversion technology for web conferencing and live streaming, which were previously difficult. In the future, it is expected to be used in various situations, such as on smartphones and VR devices.
This result will be exhibited at the NTT Science and Core Technology Laboratory Group Open House 2024 which will be held from June 24.
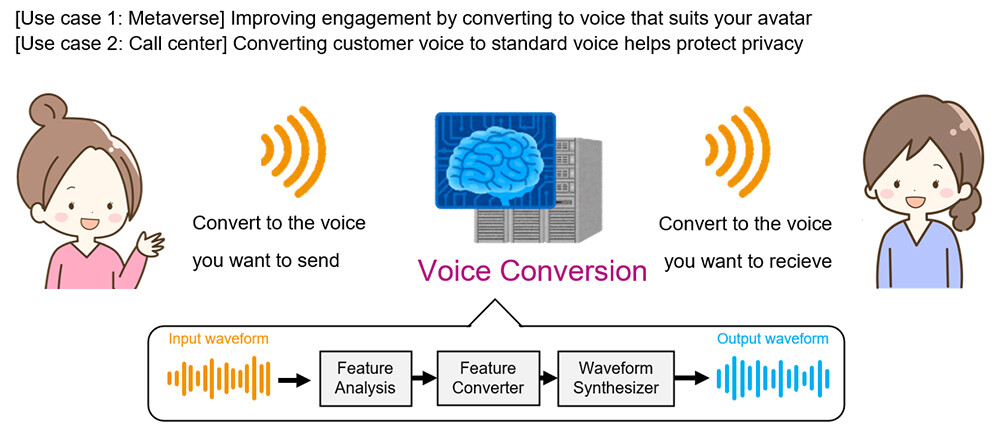 Figure 1 Communication Enhancement through Voice Conversion
Figure 1 Communication Enhancement through Voice Conversion
1. Background
Voice is a particularly convenient communication medium because it can convey not only verbal information but also non-verbal information, such as the speaker's intonation and vocal habits. We talk and listen frequently, and people often wish to speak and listen in a more ideal voice but there has been limited technology that can easily realize it until now. Voice conversion contributes to the realization of communication free from physical, intellectual, and psychological constraints by changing the characteristics of the voice (voice quality, intonation, rhythm, etc.) while maintaining the language content, resulting in fluent English pronunciation close to native speakers, persuasive speech, and removing nervousness-induced voice tremors, etc. The application areas include privacy, entertainment, healthcare, education, and business (Figure 1).
Depending on these use cases, various prerequisites can be assumed, such as the amount of data to be converted, the amount of data to be used to train conversion models, and the requirements for real-time conversion processing. NTT has been working on a technology that can flexibly convert not only voice quality but also intonation and rhythm using paired data of the same utterance of the source and target speakers, and a pair-data-free learning method that does not require paired utterances of the source and target speaker which is costly to collect.
This time, we have developed a low-latency real-time voice conversion technology that can be used in a variety of voice communications, including web conferencing, by combining the research results of these voice feature conversion technologies with the research results of our proprietary waveform synthesis technology, which generates voice waveforms from voice features.
2. Key points of the technology
(1) Low-latency conversion processing
When we speak, people are speaking while listening to their own voices. This is called feedback speech, and if this feedback speech is greatly delayed, it makes it very difficult to speak, caused by a phenomenon called delayed auditory feedback. Therefore, in a situation where the speaker hears the converted speech that has passed through the voice conversion system, it is necessary to reduce the delay caused by voice conversion to several tens of milliseconds for smooth speech.
In general voice conversion, when a converted speech at a certain time is generated, it is converted using a non-causal model that uses not only the input speech frame at that time but also future input speech frames at the same time, achieving high conversion performance (Figure 2). On the other hand, waiting for future frames causes a large delay, which is a problem. Therefore, in this voice conversion, we have minimized the delay time and achieved low-delay voice conversion by adopting a (causal) model that generates converted speech only from the current time and past speech frames without using any future speech frames.
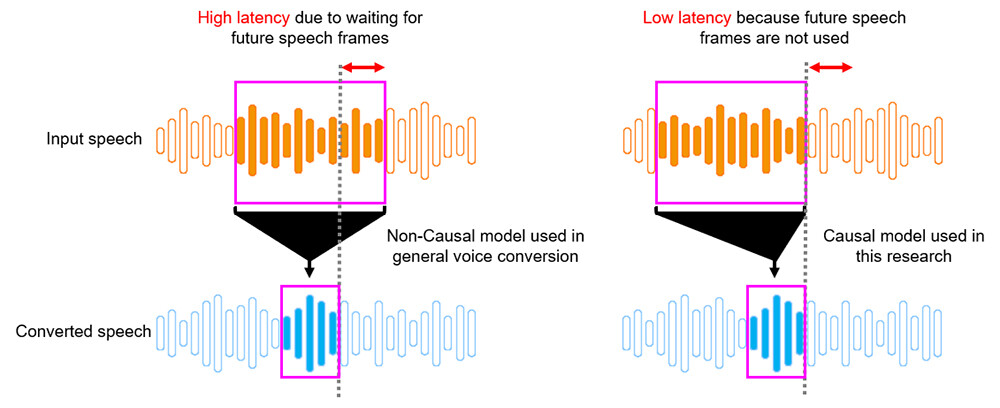 Figure 2 Low-Latency Model
Figure 2 Low-Latency Model
(2) High conversion performance
The feature converter consists of an encoder that plays the role of speech recognition and a decoder that plays the role of text-to-speech synthesis. The encoder extracts intermediate features from input speech. In this case, the intermediate feature is expected to contain text-equivalent information with the speaker information of the input speaker removed. The decoder then generates the features of the converted speech by adding information about the target speaker to the extracted intermediate features. This time, we have newly discovered that the speaker information remains in the intermediate features in the conventional voice conversion, causing degradation in conversion performance. Therefore, a constraint was explicitly introduced to generate a pseudo voice with the same input speech and the same utterance but different speaker information (for example, a voice processed to lower only the pitch of the voice), and to bring the intermediate feature values of the input speech closer to the intermediate feature values of the pseudo voice (Figure 3). This greatly reduces the residual speaker information in the intermediate features compared with the conventional method. As a result, high-quality feature conversion has been achieved by acquiring speech expressions with low speaker dependency. The waveform of the final converted speech can be obtained by inputting the speech features converted by this technology into a lightweight and high-speed waveform synthesizer developed by NTT.
 Figure 3 Feature Conversion Method
Figure 3 Feature Conversion Method
3. Outline of the experiment
Listening experiments were conducted to evaluate the quality of speech converted using the conventional method and the proposed method on a 5-scaled evaluation for sound quality (1: bad, 2: poor, 3: fair, 4: good, 5: excellent) and a 4-scaled evaluation for speaker similarity with the target speaker (1: different, 2: probably different, 3: probably the same, 4: same). The result of the feature converter greatly outperformed the conventional method in terms of sound quality and speaker similarity, indicating that the proposed method is effective in explicitly reducing differences caused by differences in speakers (Figure 4).
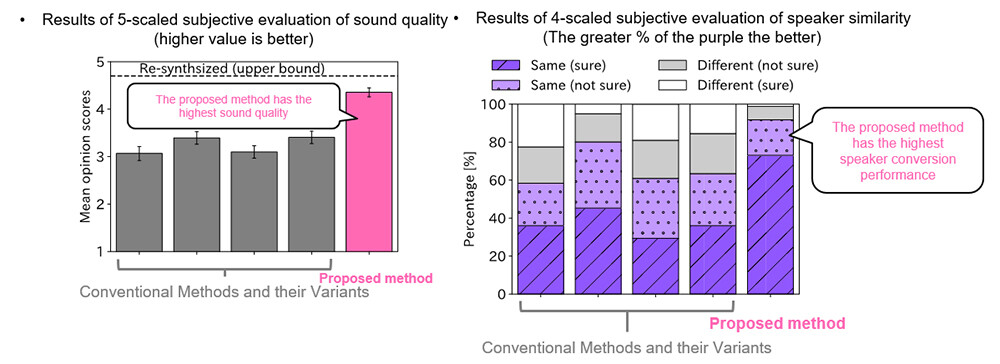 Figure 4 Experimental Result
Figure 4 Experimental Result
4. Outlook
This technology is expected to enrich speech communication in various business and real-life situations, whether face-to-face or remote, such as the use of this technology for dysphonia, fluent English pronunciation close to native English, persuasive speech, and removing of nervousness-induced voice tremors, etc.
In the future, we will work to improve noise-resistance and stability in real environments, as well as countermeasures against impersonation, with the aim of creating a future in which users can communicate with their favorite voices more securely.
About NTT
NTT contributes to a sustainable society through the power of innovation. We are a leading global technology company providing services to consumers and businesses as a mobile operator, infrastructure, networks, applications, and consulting provider. Our offerings include digital business consulting, managed application services, workplace and cloud solutions, data center and edge computing, all supported by our deep global industry expertise. We are over $97B in revenue and 330,000 employees, with $3.6B in annual R&D investments. Our operations span across 80+ countries and regions, allowing us to serve clients in over 190 of them. We serve over 75% of Fortune Global 100 companies, thousands of other enterprise and government clients and millions of consumers.
Media contact
NTT Science and Core Technology Laboratory Group
Public Relations
nttrd-pr@ml.ntt.com
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






