Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


November 17, 2025
NTT, Inc.
NTT Develops Mind Captioning: A Brain-Decoding Technology That Converts Recalled Visual Content into Words
~Exploring new ways in nonverbal, thought-based communication~
News Highlights:
- NTT has developed “Mind Captioning”, a technology that combines brain-decoding techniques with a language AI model to generate descriptive texts of visual content that a person sees or even recalls, directly from brain activity.
- NTT demonstrated that accurate text generation is possible without relying on language-related brain regions, opening up new possibilities for decoding nonverbal thought and translating it into language.
- This achievement sheds light on how the brain represents complex and structured semantic information related to visual content. In the future, by extending this technology as a general framework for translating diverse nonverbal thoughts, including non-visual sensory imagery, emotions, and conceptual thought, into language, it is expected to contribute to communication support for individuals who have difficulty speaking.
TOKYO - November 17, 2025 - NTT, Inc. (Headquarters: Chiyoda-ku, Tokyo; President and CEO: Akira Shimada; hereinafter "NTT") has developed a new technology called Mind Captioning that generates descriptive text of what a person is seeing based solely on their brain activity. By applying this technology to brain activity recorded while a person recalls previously viewed video clips, NTT has become the first in the world to generate text descriptions of the visual content of recalled videos directly from brain activity (Figure 1).
This technology builds on the “brain–AI integrated decoding”1 approach, which combines brain decoding2 with artificial intelligence, and extends it through the incorporation of a language AI model. By leveraging the strong representational and generative capabilities of language AI models, the technology enables the generation of text that closely aligns with the semantic information represented in the brain. NTT further demonstrated that the technology can translate nonverbal information about what a person sees or recalls into language without relying on activity in the brain's language regions. This indicates that the approach does not reconstruct linguistic thought but instead translates nonverbal thought into language, opening a new direction for brain decoding technology.
These results advances scientific understanding of how the brain represents complex visual semantic information. They are also expected to contribute to future applications, including communication support for individuals who have difficulty speaking and new methods of communication that convey emotions or intentions without spoken language.
The results of this research were published online in Science Advances on November 5, 2025 (U.S. Eastern Time). Part of this work will be exhibited at NTT R&D FORUM 2025 IOWN ∴Quantum Leap3, held from November 19 to 26, 2025.
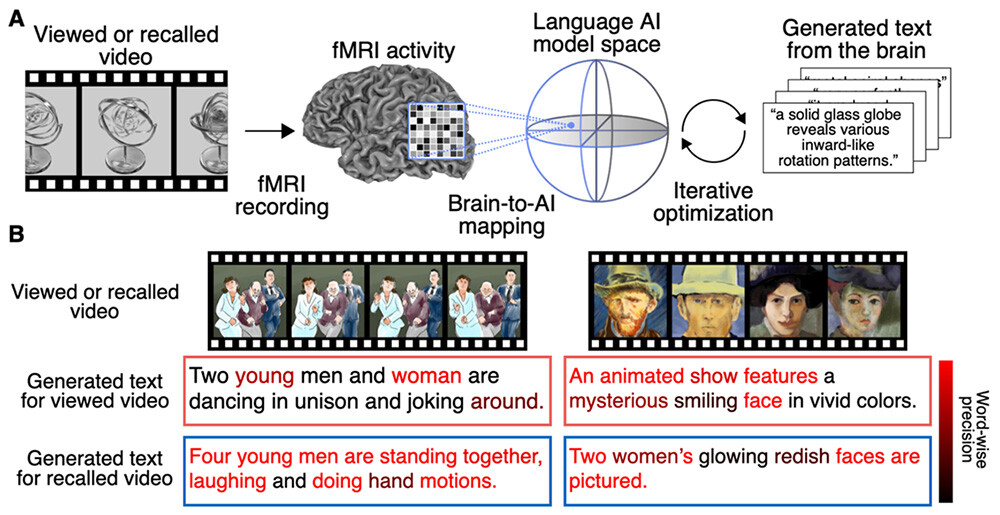 Figure 1 Overview and key results of this study.
Figure 1 Overview and key results of this study.
(A) Overview of the proposed Mind Captioning technology. fMRI brain activity signals4 measured while a person views or recalls a video are mapped onto the feature space of a language AI model (a deep language model)5 using machine-learning methods. Text is then generated through iterative optimization, during which the system searches for candidate text whose features more closely match those predicted from the observed brain activity. This process enables the generation of sentences that reflect the semantic content of the viewed or recalled video directly from brain activity.
(B) Examples of the video stimuli used in the experiment (top) and the text generated from brain activity recorded during perception or recall of those videos (bottom). In the generated text, tokens (referred to as “words” in the figure and below) that are semantically similar to words in human-created reference descriptions of the video content are shown in deeper red. For both the perception and recall conditions, the generated text captures the content of the viewed or recalled videos and is structured, containing words that are semantically similar to those in the reference descriptions. These results demonstrate that the viewed or recalled video can be identified using only the text generated from brain activity.
Background
Humans perceive and remember the world through vision and are able to express that information in words. In recent years, technologies that directly decode “linguistic information” from the brain have advanced, but decoding “nonverbal thought content,” such as visual imagery, into sentences remains a significant challenge. If diverse brain information related to nonverbal thought could be translated from brain activity into text, it would allow for more flexible interpretation of mental states and open new possibilities for both neuroscience and applied research.
In this study, a language AI model (a deep language model5) was incorporated into the “brain–AI integrated decoding” approach, which combines brain decoding with artificial intelligence. This enabled the development of a technology, referred to as Mind Captioning, that generates descriptive text of visually perceived or imagined content directly from human brain activity (Figure 1).
Research Results
In this study, NTT developed Mind Captioning, a technology that generates descriptive text of visually perceived or imagined content from human brain activity. The method consists of two stages: (1) training a decoding model (decoder) that predicts semantic features of a deep language model from brain activity, and (2) iteratively optimizing text based on the features predicted by the trained decoder. Through this two-stage process, the system successfully generated descriptive text of perceived or imagined visual content from human brain activity measured using functional magnetic resonance imaging (fMRI)4 (Figure 2).
The method produces text from brain activity through this two-stage procedure. In Stage 1, fMRI data recorded while participants viewed videos were collected, along with text descriptions of the visual content of each video created through crowdsourcing. Semantic features were then extracted from each description using a language AI model (a deep language model, DeBERTa-large), and a decoder was trained to predict these features from the brain activity recorded while the corresponding video was viewed. In Stage 2, brain activity recorded while participants viewed or recalled new videos was converted into semantic features using the trained decoder. These decoded features served as targets for word-level iterative optimization to generate text. The optimization began with arbitrary initial text (in this study, the token <unk>). Portions of the text were randomly replaced or augmented by masked tokens ([MASK]) to create candidate sentences, which were then completed using a masked language model (RoBERTa-large)6. Among the generated candidates, those with higher similarity to the decoded features were selected, and this process was repeated to progressively generate text that aligns with the brain information.
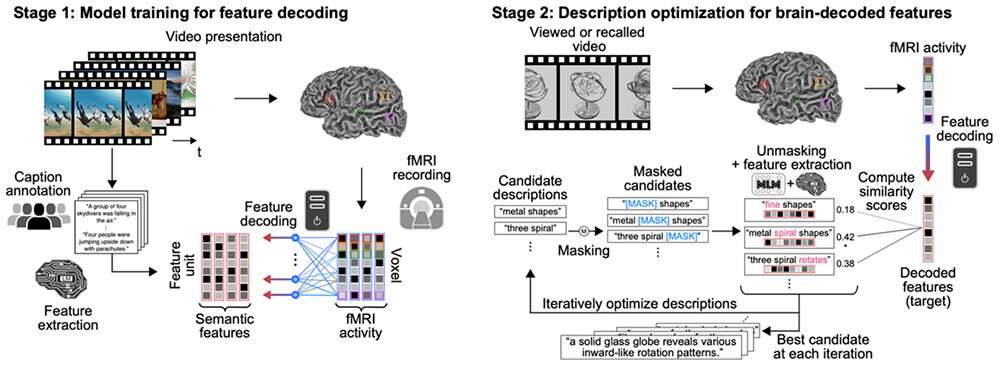 Figure 2 Text generation from brain activity using Mind Captioning.
Figure 2 Text generation from brain activity using Mind Captioning.
To examine the effectiveness of the method, text was first generated from brain activity recorded while participants viewed videos. Even when starting from the token <unk>, which contains no prior information, the iterative optimization process progressively produced words that reflected the content of the video. After 100 iterations, the system generated a description that accurately captured the content of the entire video (Figure 3A). Applying the same procedure to brain activity recorded during recall of previously viewed videos also enabled the successful generation of descriptions of the recalled content (Figure 1B, bottom).
To evaluate the accuracy of the generated text, similarity scores were computed between the generated text for each video and human-written reference descriptions. The analysis examined whether these similarity scores were higher than those for unrelated videos, that is, whether the perceived or recalled video could be correctly identified from among multiple candidate videos, based solely on the generated text. Using whole-brain activity, the correct video was identified with approximately 50 percent accuracy during perception and approximately 30 percent accuracy during recall, even when selecting from 100 candidate videos (chance level7 = 1 percent, averaged across six participants) (Figure 3B).
A particularly noteworthy finding is that high-quality text generation and high-accuracy video identification remained possible even when activity in language-related brain regions (the language network spanning the frontal to temporal cortices, shown in red in Figure 3B) was excluded from the analysis. This result suggests that the method does not reconstruct linguistic information from the brain but instead interprets nonverbal information by translating it into language.
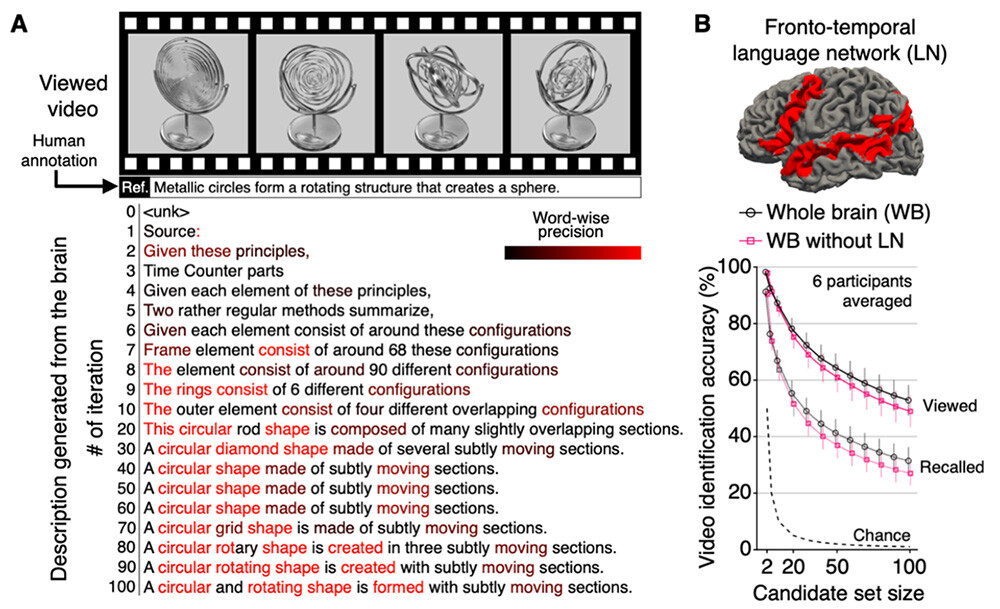 Figure 3 Text generation results from brain activity related to perceived and recalled content.
Figure 3 Text generation results from brain activity related to perceived and recalled content.
(A) Examples of text generated from brain activity during the iterative optimization process under the perception condition.
(B) Video identification performance when language-related brain regions (language network; LN) were included or excluded from the analysis. Identification accuracy was evaluated by varying the number of candidate videos from 2 to 100, based on similarity scores (correlation of semantic features) between the generated text and the human-written reference descriptions for each video.
Future Outlook
In this study, complex and structured visual semantic information was successfully decoded from brain activity. This achievement suggests that the proposed method may serve as a new tool for exploring how complex visual meaning is represented in the brain. However, because the experiment used natural video clips collected from the web, the method's ability to generalize to atypical scenes, such as “a person bites a dog,” has not yet been evaluated. Future work will require careful examination of biases inherent in the models and training data, as well as more detailed assessment of how accurately the technology captures information that truly exists in the brain. With continued validation, the method may eventually be applied to understanding the investigations of how structured thought develops in populations that cannot speak, such as infants or animals.
At the same time, the ability to generate text describing internally imagined content raises concerns about potential intrusion into mental privacy. In this research, extensive fMRI recordings totaling 17 hours per participant were conducted across multiple days with explicit informed consent. At present, large-scale and long-duration data collection is essential for precise analysis of brain information, and the technology only functions only with the active cooperation of participants. However, future advances in brain measurement and analysis may enable the decoding of an individual's thoughts from far less data. While such progress would represent a major scientific and technological advance, it would also introduce the risk that unspoken thoughts could be inferred without a person's consent. In addition, biases or noise inherent in models or data could distort the content of generated text, unintentionally altering interpretations or nuances and compromising the accuracy of information inferred from brain activity.
Given these challenges, it is essential to ensure both the responsible advancement of the field and the protection of individual mental autonomy. Going forward, it will be important to carefully determine the contexts in which the technology should be applied, evaluate the accuracy required in each case from both scientific and practical perspectives, and respect individuals' rights to choose which aspects of their thoughts they express as their own. At the same time, deeper technical and ethical discussions are needed to balance accuracy and reliability with the protection of mental privacy. To support this, transparent research practices and robust data-governance framework will continue to be promoted to foster public trust.
Through technological development grounded in a deep understanding of human information processing, NTT aims to advance the scientific exploration of human thought and the mind, while applying these insights to open pathways toward next-generation communication technologies.
Publication Information
Journal: Science Advances (Online edition: November 5)
Paper title: Mind Captioning: Evolving descriptive text of mental content from human brain activity
Author: Tomoyasu Horikawa
DOI: https://doi.org/10.1126/sciadv.adw1464![]()
URL: https://www.science.org/doi/10.1126/sciadv.adw1464![]()
[Glossary]
1Brain–AI Integrated Decoding: An approach that maps brain activity patterns into an AI feature space using machine-learning methods, enabling brain data analysis with AI technologies. In this study, fMRI brain activity recorded while participants watched videos was mapped into the semantic feature space of a language AI model (deep language model). Text was then iteratively optimized based on these mapped features to generate descriptions reflecting the meaning of the perceived or recalled videos.
2Brain Decoding: A technique that analyzes brain activity signals measured with fMRI and other methods using pattern analysis, such as machine learning, to predict or decode physical and mental states from brain activity.
3NTT R&D FORUM 2025 IOWN ∴Quantum Leap: Official website: https://www.rd.ntt/e/forum/2025/![]()
Exhibit information: Exhibit No. D14, Category: Generative AI

4Functional Magnetic Resonance Imaging (fMRI): A representative non-invasive method for measuring brain activity using MRI. Rather than directly capturing neural activity, fMRI detects BOLD (blood-oxygen-level dependent) signals, which reflect changes in blood flow and oxygenation associated with neural activity. fMRI provides relatively high spatiotemporal resolution for human brain measurement. In this study, whole-brain data were acquired at 2 mm isotropic resolution with a 1-second sampling intervals.
5Deep Language Model: A type of language AI model trained on large-scale text data. By embedding word meanings and contextual relationships into internal vector representations, these models achieve high performance across a wide range of natural language processing tasks. In this study, the internal representations, referred to as “semantic features,” were used both as prediction targets for fMRI-based decoding and as features for optimizing text generation.
6Masked Language Modeling (MLM) Model: A type of deep language model trained by replacing part of the input text with masked tokens ([MASK]) and predicting the masked words. A representative example is BERT (Bidirectional Encoder Representations from Transformers), which uses bidirectional attention mechanisms to capture meaning based on bonth preceding and following context.
7Chance Level: The probability of correctly identifying the target by random selection. For N candidate videos, the chance level is 1/N. In this study, the chance level varied depending on the number of candidate videos, ranging from 2 to 100 (e.g., 1% for 100 videos).
About NTT
NTT contributes to a sustainable society through the power of innovation. We are a leading global technology company providing services to consumers and businesses as a mobile operator, infrastructure, networks, applications, and consulting provider. Our offerings include digital business consulting, managed application services, workplace and cloud solutions, data center and edge computing, all supported by our deep global industry expertise. We are over $90B in revenue and 340,000 employees, with $3B in annual R&D investments. Our operations span across 80+ countries and regions, allowing us to serve clients in over 190 of them. We serve over 75% of Fortune Global 100 companies, thousands of other enterprise and government clients and millions of consumers.
Media contact
NTT, Inc.
NTT Science and Core Technology Laboratory Group
Public Relations
Inquiry Form![]()
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






