Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


April 22, 2026
NTT, Inc.
NTT Establishes World's First Framework for Lossless Vocabulary Reduction Across LLMs
-- Enables seamless cooperation and knowledge transfer across heterogeneous models --
News Highlights:
- Established the world's first theory and algorithm that enable flexible reduction of the token vocabulary, the input and output unit in large language model (LLM) inference, without loss of accuracy during inference
- Enables interoperability across arbitrary heterogeneous LLMs through a shared token vocabulary
- Applying this technology to coordination methods such as ensemble techniques and NTT's proprietary portable tuning enables knowledge integration and transfer across a wider range of heterogeneous LLMs
TOKYO — April 22, 2026 — NTT, Inc. (Headquarters: Chiyoda-ku, Tokyo; President and CEO: Akira Shimada; hereinafter "NTT") has established the world's first inference technology that reduces the token vocabulary, the input and output unit in large language models (LLMs), without degrading accuracy and enables a shared token vocabulary across heterogeneous LLMs. Previously, implementing inference-time coordination methods such as ensemble*1 using multiple LLMs required the models to share the same vocabulary. This technology removes that constraint, enabling inference-time coordination across arbitrary heterogeneous LLMs, including techniques that were previously difficult to achieve such as ensemble and NTT's proprietary portable tuning*2. This advancement enables improved accuracy through knowledge integration and transfer.
This research will be presented at ICLR 2026 (International Conference on Learning Representations)*3, the premier international conference in the field of deep learning, to be held in Rio de Janeiro, Brazil, from April 23–27, 2026.
Background
In recent years, large language models (LLMs) have rapidly gained adoption as AI systems capable of reasoning in natural language. Instead of generating text character by character, LLMs perform inference efficiently using units called tokens, which represent subwords. More specifically, inference proceeds by repeatedly performing next-token prediction, in which the model estimates probability distributions over candidate tokens and outputs tokens based on these predictions.
The set of candidate tokens is referred to as the token vocabulary, which typically consists of tens of thousands to hundreds of thousands of tokens. In practice, token vocabularies often differ across LLMs developed by different organizations or at different times. When token vocabularies differ between models, it becomes impossible to directly compare or share next-token prediction results during inference. This "vocabulary barrier" has made it difficult to apply token-level coordination techniques across heterogeneous LLMs, including the ensemble method that integrates predictions from multiple models to improve accuracy, and the portable tuning method that transfers specialized knowledge across models.
Overview of the Research Results
NTT has established an inference technology that enables flexible reduction of the original token vocabulary of a large language model (LLM) without degrading its performance (Figure 1). This technology does not require additional training and instead dynamically transforms next-token prediction results during inference so that it predicts only with a specified subset of the token vocabulary.
Specifically, a novel transformation algorithm was derived based on our theoretical framework that preserves the probability distribution of the final output text. This makes it possible to perform inference with any selected sub-vocabulary while maintaining the original inference performance.
By applying this technology, inference can be conducted across multiple LLMs with different vocabularies through a shared subset of tokens, referred to as the maximum common vocabulary. This enables heterogeneous LLMs to share next-token prediction results during inference (Figure 2).
Experimental validation confirmed that, in practical language models, inference with various sub-vocabularies can be performed without loss of accuracy, as predicted by the theory. As an application, ensemble across heterogeneous LLMs using the maximum common vocabulary was demonstrated, showing that combining different knowledge sources leads to improved inference performance.
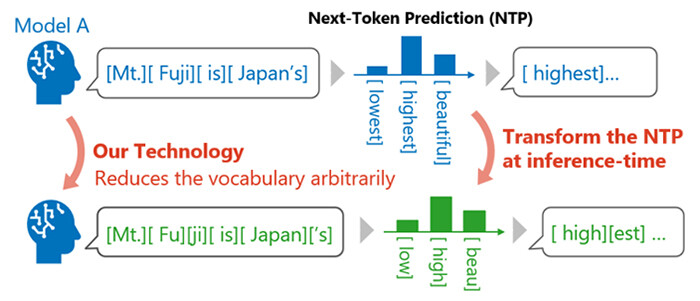 Figure 1. Establishment of an inference technology that enables flexible reduction of the token vocabulary while preserving LLM output characteristics
Figure 1. Establishment of an inference technology that enables flexible reduction of the token vocabulary while preserving LLM output characteristics
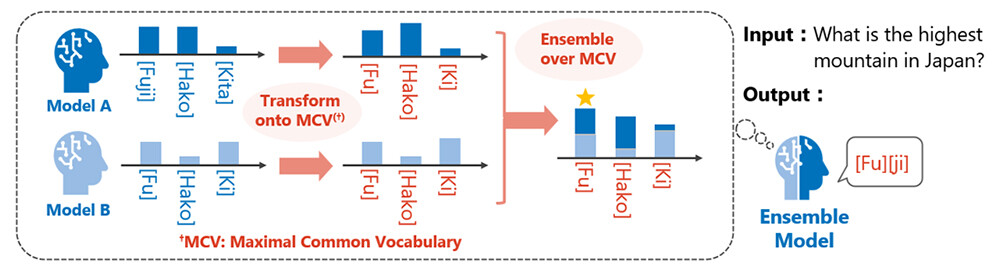 Figure 2. Ensemble across LLMs with different vocabularies enabled through a shared vocabulary
Figure 2. Ensemble across LLMs with different vocabularies enabled through a shared vocabulary
Key Technical Points
(1) New theory for flexible vocabulary reduction without loss
A world-first theoretical framework was established that enables next-token prediction using any reduced set of token candidates (sub-vocabulary) while preserving the quality of generated text from an LLM. Simply removing token candidates by ignoring their probabilities in next-token prediction would significantly alter the final generated text and lead to performance degradation.
This research introduces a unified theoretical framework that consistently handles token probabilities for both the original vocabulary and a sub-vocabulary. Based on this framework, a relationship was derived showing that probabilities over a sub-vocabulary can be expressed as a superposition of probabilities over the original vocabulary (Figure 3). By transforming next-token prediction results from the original vocabulary according to this relationship at each step of inference, next-token prediction over a sub-vocabulary can be computed without altering the characteristics of the generated text.
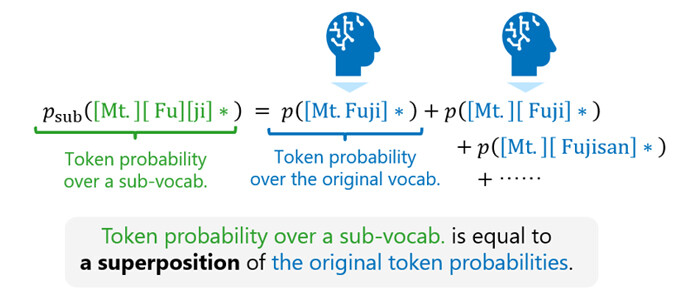 Figure 3. Derivation of a relationship between the original vocabulary and sub-vocabularies
Figure 3. Derivation of a relationship between the original vocabulary and sub-vocabularies
(2) Derivation of an efficient inference algorithm for sub-vocabularies
While the relationship described in (1) enables next-token prediction with any sub-vocabulary in principle, it requires multiple next-token predictions with the original vocabulary, introducing additional computational cost. To address this, the proposed method incorporates two key design strategies: reuse of previously computed predictions through caching, and omission of lower-ranked tokens whose probabilities are effectively negligible (Figure 4).
As a result, an efficient algorithm was achieved that operates with computational cost comparable to standard inference using the original vocabulary. Application of this algorithm to real-world LLMs experimentally confirmed that inference with various sub-vocabularies can be performed as predicted by the theory, without altering output characteristics (Figure 5).
 Figure 4. Development of an efficient algorithm to compute the relationship described in (1)
Figure 4. Development of an efficient algorithm to compute the relationship described in (1)
 Figure 5. Inference results using various sub-vocabularies in practical LLMs
Figure 5. Inference results using various sub-vocabularies in practical LLMs
(3) Knowledge integration across heterogeneous LLMs via a maximum common vocabulary
As an application of the proposed inference algorithm, knowledge integration across heterogeneous LLMs with different vocabularies was achieved by performing inference over a "maximum common vocabulary," defined as the set of all shared tokens across models. This enables sharing of next-token predictions across heterogeneous LLMs.
For example, in a combination of two publicly available models, one model may have approximately 150,000 tokens and the other 130,000 tokens, with a maximum common vocabulary of approximately 60,000 tokens. Performing inference over such a shared vocabulary enables inference-time coordination that requires sharing of next-token predictions, including ensemble-based knowledge integration and portable tuning-based knowledge transfer (Figure 2).
Experimental results further confirmed that applying ensemble over the shared tokens to LLMs with different vocabularies significantly improves inference accuracy compared to individual models, due to the integration of knowledge from diverse sources (Figure 6).
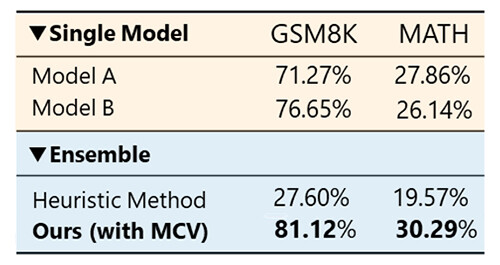 Figure 6. Example of improved accuracy on mathematical tasks
Figure 6. Example of improved accuracy on mathematical tasks
Future Outlook
This research enables flexible reduction of token vocabularies during LLM inference and, as an application, allows seamless coordination at the next-token prediction level even across heterogeneous LLMs with different token vocabularies. By combining this technology with various coordination methods such as ensemble techniques and portable tuning, knowledge integration and transfer across a wide range of heterogeneous LLMs becomes possible.
In particular, LLMs with proprietary vocabularies, including NTT's tsuzumi*4, are expected to more easily interoperate with publicly available LLMs through the application of this technology.
About the Announcement:
This research will be presented at ICLR 2026 (International Conference on Learning Representations), one of the most prestigious international conferences in the field of deep learning, to be held from April 23 to April 27, 2026.
(Computer & Data Science Research Institute)
Taku Hasegawa, Kyosuke Nishida
(Human Information Research Institute)
[Glossary]
*1Ensemble: A classical coordination technique that aggregates probability distributions over output candidates from multiple models to generate outputs based on consensus across models.
*2Portable Tuning: An NTT-developed technique that enables the effects of specialized training to be applied to new foundation models without additional retraining, by leveraging a pre-trained reward model in coordination with the base model.
- Video: NTT's Portable Tuning Drastically Reduces Customization Cost for Generative AIs
https://youtu.be/Xa2otAFqHgc![]()
- Press release (July 9, 2025):
https://group.ntt/en/newsrelease/2025/07/09/250709a.html
*3ICLR 2026: A top-tier international conference on deep learning.
https://iclr.cc/Conferences/2026![]()
*4tsuzumi: An NTT large language model, including "tsuzumi 2."
https://www.rd.ntt/e/research/LLM_tsuzumi.html![]()
About NTT
NTT is a leading global technology innovator, providing a broad range of services to both consumers and businesses. As a mobile operator and provider of infrastructure, networks, and services, NTT is dedicated to promoting a sustainable future through cutting-edge innovations. Our portfolio includes business consulting, AI-powered solutions, application services, global networks, cybersecurity, data center and edge computing, all supported by our deep global industry expertise. Generating over $90 billion in revenue and employing 340,000 professionals, we allocate 30% of our annual profits to fundamental research and development. With operations spanning more than 70 countries and regions, our clients include over 75% of Fortune Global 100 companies, alongside thousands of enterprises, government organizations, and millions of consumers.
Media Contact
NTT, Inc.
NTT Service Innovation Laboratory Group
Public Relations
Inquiry Form![]()
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






