Microsoft ends support for Internet Explorer on June 16, 2022.
We recommend using one of the browsers listed below.
- Microsoft Edge(Latest version)
- Mozilla Firefox(Latest version)
- Google Chrome(Latest version)
- Apple Safari(Latest version)
Please contact your browser provider for download and installation instructions.


May 28, 2018
World's first technology for extracting the speech of a target speaker based on the characteristics of his/her voice --New deep learning technology for extracting a target voice from a noisy environment--
Nippon Telegraph and Telephone Corporation (NTT; head office: Chiyoda-ku, Tokyo; president & CEO: Hiroo Unoura) has developed a new technology called SpeakerBeam*1 for extracting the voice of a target speaker (a speaker you want to listen to) from recordings of several people speaking at the same time based on the characteristics of the target speaker's voice.
Human beings can focus on speech spoken by a target speaker even in the presence of noise or other people speaking in the background. This ability is called selective auditory attention or selective hearing*2 (See figure 1). Selective hearing is realized by exploiting information about the characteristics of the voice and the position of the target speaker. Previously proposed computational selective hearing systems developed to mimic human selective hearing ability used information about the target speaker position*3. Unlike these approaches, SpeakerBeam is the first successful attempt to realize computational selective hearing based on the characteristics of the voice of the target speaker. This was made possible thanks to the novel deep learning technology developed at NTT*4.
SpeakerBeam enables the extraction of the voice of a target speaker without knowing his/her position, which opens new possibilities for the speech recognition of multi-party conversations or speech interfaces for assistant devices.
[Video]![]() https://www.youtube.com/watch?v=7FSHgKip6vI
https://www.youtube.com/watch?v=7FSHgKip6vI
The link points to an external website
Background
Recently, automatic speech recognition technology has progressed greatly, thus enabling the rapid adoption of speech interfaces in smartphones or smart speakers. However, the performance of current speech interfaces deteriorates severely when several people speak at the same time, which often happens in everyday life e.g. when we take part in a discussion or when a television is on in the background. The main reason for this problem arises from the inability of current speech recognition systems to focus solely on the voice of the target speaker (selective hearing) when several people are speaking.
Research achievement
NTT Communication Science Laboratories has developed*5 SpeakerBeam to make it possible to extract the voice of a target speaker from a recording containing a mixture of several people speaking simultaneously. SpeakerBeam distinguishes the target speaker from the other speakers by using another recording (about 10 seconds long) of the target speaker's voice as auxiliary information. This auxiliary information is employed to compute the characteristics of the voice of the target speaker. SpeakerBeam then extracts the speech from the mixture that matches these voice characteristics. SpeakerBeam can extract the target speaker's voice regardless of the sounds contained in the mixtures, which may include other speakers, music and background noise. It can work using a single microphone but the use of more microphones further improves the quality of the extracted speech.
In experiments, we used simulated mixtures of several speakers to prove that SpeakerBeam could successfully extract the voice of a target speaker (see left side of figure 3) and improve speech recognition accuracy by 60% (see right side of figure 3).
Features of the technology
(1)Computational selective hearing based on the voice characteristics of the target speaker
There are various elements that characterize a person's voice such as its pitch, timbre, rhythm, intonation, and accent. Human beings can use these characteristics to focus on the voice of a specific speaker, even when it is mixed with other sounds, and ignore all other sounds. By listening once to someone's voice, human beings are able to recognize the characteristics immediately and listen only to that voice. With SpeakerBeam we have realized a system that replicates this selective hearing ability.
Characterizing human voices may require the combination of the various elements described above. However, it is unclear as to which of these elements are important as regards realizing selective hearing. Instead of manually engineering features characterizing the target speaker's voice, we have developed a purely data-driven approach based on deep learning to automatically learn these features. We proposed combining a module to compute the voice characteristics using the auxiliary information and a module to extract the voice of the target speaker from the speech mixture. These two modules are trained jointly to optimize target speech extraction. As a result, we can obtain the voice characteristics of the target speaker from relatively short utterances that are optimized for extracting the target speaker's voice.
Audio speech separation is another approach for dealing with speech mixtures that has been intensively researched. Source separation separates a mixture of speech signals into each of its original components. It uses such characteristics of the sound mixture as the direction of arrival of the sounds to distinguish and separate the different sounds. Speech separation can separate all the sounds in the mixture, but for this purpose it must know or be able to estimate the number of speakers included in the mixture, the position of all the speakers, and the background noise statistics. These conditions often change dynamically making their estimation difficult thus limiting the actual usage of the separation methods. Moreover, to realize selective hearing, we still need to inform the separation system about the separated speech that corresponds to the target speaker.
In contrast, SpeakerBeam avoids the need to estimate the number of speakers, the position, or the noise statistics, by focusing on the simpler task of solely extracting speech that matches the voice characteristics of the target speaker.
(2)Deep learning technology behind SpeakerBeam
We have developed a novel neural network architecture with which to realize SpeakerBeam. This neural network consists of a main network and an auxiliary network as described below.
- The main network inputs the speech mixture and outputs the speech that corresponds to the target speaker. The main network is a regular multi-layer neural network with one of its hidden layers replaced by an adaptive layer. This adaptive layer can modify its parameters depending on the target speaker to be extracted, namely it can change its parameters depending on the characteristics of the voice of the target speaker provided by the auxiliary network.
- The auxiliary network is a multi-layer neural network that inputs a recording of only the voice of the target speaker that is different from that in the speech mixture. The auxiliary network outputs the characteristics of the voice of the target speaker.
These two networks are connected to each other and trained jointly to optimize the speech extraction performance. By training the network with a large amount of training data covering various speakers and background noise conditions, SpeakerBeam can learn to realize selective hearing even for speakers that were not included in the training data.
Future development
We intend to pursue research to improve speech extraction performance when speakers with similar voices converse. Moreover, we plan to investigate using SpeakerBeam to help realize AI systems that understand people's discussions in everyday life environments.
 Fig. 1 Human selective hearing ability
Fig. 1 Human selective hearing ability
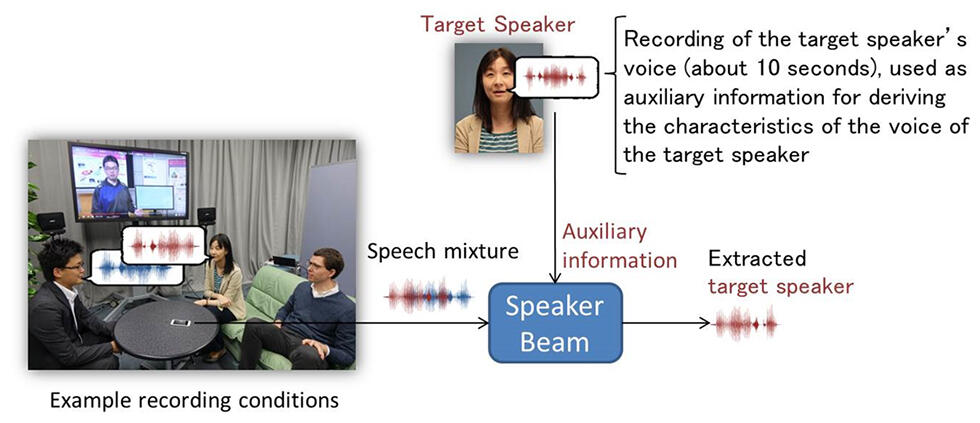 Fig. 2 SpeakerBeam's selective hearing
Fig. 2 SpeakerBeam's selective hearing
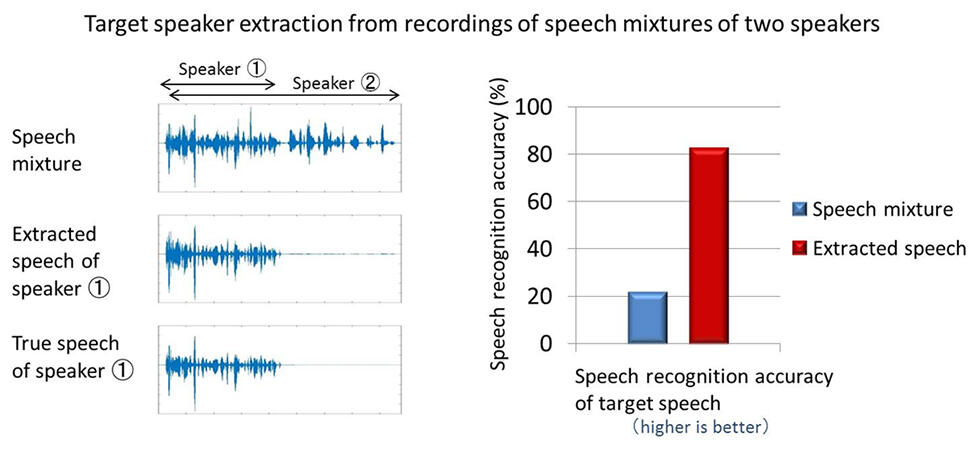 Fig. 3 Evalution of speech extraction performance and automatic speech recognition with SpeakerBeam
Fig. 3 Evalution of speech extraction performance and automatic speech recognition with SpeakerBeam
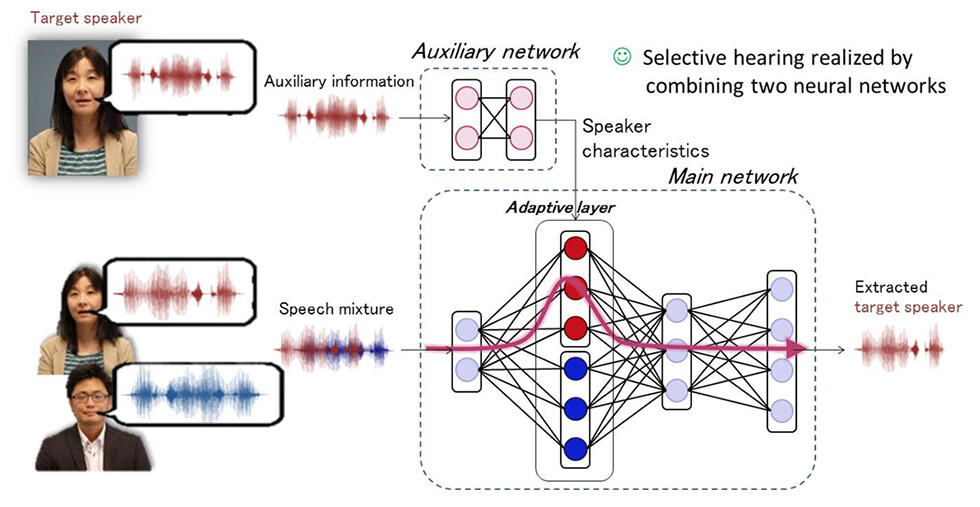 g. 4 Novel deep learning architecture developed for SpeakerBeam
g. 4 Novel deep learning architecture developed for SpeakerBeam
Notes
- SpeakerBeam
SpeakerBeam is an audio processing technology developed at NTT to extract the voice of a target speaker by focusing on the characteristics of his/her voice. The name SpeakerBeam was inspired by the widely used microphone array processing approach called beamformer, which steers a beam in a desired direction to extract sounds originating from that direction. In a conceptually similar fashion, SpeakerBeam extracts speech originating from the speaker whose voice characteristics match those of the target speaker. - Selective hearing
Selective hearing refers to the ability to focus on a desired sound and ignore other sounds in a mixture of various sounds. Human beings use this ability e.g. to follow a discussion with a particular speaker in a noisy environment. This is also referred to as the cocktail party effect. SpeakerBeam is a computational approach designed to realize a similar function, i.e. a technology that extracts the voice of a target speaker based on his/her voice characteristics regardless of background sounds. - Speech extraction based on the direction of arrival of sound
If we know the position of the target speaker relative to the microphones, it is possible to steer the directivity of the microphones in that direction and extract the target speech from a speech mixture. Even if the position of the target speaker is unknown, it is possible to separate different speakers and sound sources present in the mixture if we know the number of speakers and/or other sound sources included in the mixture. However, in many cases, the position of the target speaker is unknown or it is hard to estimate the total number of sound sources. Moreover, even if we were able to separate the signals, we would still need to inform the system as to which of the separated signals corresponded to the target speaker.
In contrast, SpeakerBeam does not need information about the position of the target speaker, or knowledge of the number of speakers or sounds in the mixture. Therefore, it becomes possible to extract the target speaker's voice even when his/her position is unknown or when another person starts speaking suddenly thus changing the number of speakers in the mixture during the recording. - Deep learning
Deep learning refers to machine learning approaches based on deep neural networks, i.e. multi-layer neural networks with several hidden layers. Deep neural networks trained with a large amount of training data can learn complex relationships or mapping functions between their inputs and outputs. Such networks have been widely used for media processing applications such as speech recognition, image recognition and machine translation. A conventional neural network is trained to realize a fixed mapping function from its input to its output. In contrast, the neural network that we have developed for SpeakerBeam can change its mapping function, i.e. some of its parameters, depending on the output of the auxiliary network. This enables SpeakerBeam to extract the target speaker from a mixture of speakers given the voice characteristics of the target speaker. - Part of this development was realized through research collaboration with Brno University of Technology.
Contact information
Nippon Telegraph and Telephone Corporation
Science and Core Technology Laboratory Group,
Public Relations
Email science_coretech-pr-ml@hco.ntt.co.jp
Information is current as of the date of issue of the individual press release.
Please be advised that information may be outdated after that point.




NTT STORY
WEB media that thinks about the future with NTT






