

2019年5月27日
日本電信電話株式会社
音を言葉で説明する技術を開発 ~人の話し声以外の音の書き取りが可能に~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田純、以下 NTT)は、様々な音に対して、それがどんな音かを説明するテキスト(擬音語や説明文)を生成する技術を開発しました。
本技術は、マイクロホンで収録した音や録音物に対して、その音を描写した擬音語や説明文を自動生成します。これまでは、音声認識システムを用いても、人の話し声以外の音を的確にテキストに変換することは困難でした。本技術によれば、様々な音を文字にすることができ、見ただけでどのような音かを把握できるようになります。
これにより、効果音や異常音など音に基づいたメディアコンテンツの検索がこれまで以上に便利になると期待されます。また、今後、AIが人間に近い音の感覚を身につけることにも役立つと考えられます。
背景
近年、音声認識技術の研究が進み、人の話し声を高い精度で認識し文字にすることが可能になってきています。しかし、これまでの音声認識システムでは、話し声以外の様々な音を文字にすることには限界がありました。また、ある音が「何の音か」を認識することを目的とした音響イベント認識の研究が近年盛んになってきていますが、それらの音が「どのような音」で、どのように変化しているかといった情報を擬音語や文章の形で書き出すことは出来ませんでした。
技術のポイント
NTTコミュニケーション科学基礎研究所は、多層ニューラルネットワーク※1に、音の特徴の時系列と文字列(擬音語)や単語列(説明文)との対応を学習させることで、音からテキストへの変換を実現しました。
研究の成果
(1)音響信号から文字列や単語列への変換
本技術は、学習段階と生成段階とから成ります。学習段階では、音響信号に対してどのような擬音語や説明文が当てはまるかのデータを教師データとして、多層ニューラルネットワークに学習させます。ニューラルネットワークは、音響信号特徴の時系列を潜在特徴と呼ばれる固定次元のベクトルに変換するエンコーダ※2と、その潜在特徴をテキストに変換するデコーダ※3の、2つの部分から構成されており、学習段階ではこれらの双方を学習させます。生成段階では、学習済みのエンコーダに音響信号特徴の時系列を入力して潜在特徴を得た後、その潜在特徴を学習済みのデコーダに入力すると、文字列を得ることが出来ます。
(2)人手による擬音語付与よりも受容度の高い擬音語を生成
所定の音響データセットに対してどの程度適切な擬音語生成ができるかを評価したところ、人手で付与した擬音語を正解とみなした客観評価実験において単語誤り率 7.2%、平均音素誤り率 2.8%となり、ほぼ妥当な擬音語が生成できることが分かりました。また、生成された擬音語が人間にとってどの程度受容できるかを主観評価実験で調べたところ、78.4%の受容率が得られました。これは、人手による擬音語を上回る値であり、所定の音響データに対して、本技術により概ね妥当な擬音語が生成されることが裏付けられました。
(3)適切な詳細度での説明文生成を実現
音に対する説明文生成では、説明の仕方(詳しさ)に絶対的な正解はありません。そこで、本技術では、どの程度の詳しさで説明するか指定することによって目的に適った文を生成できるようにする工夫を施しています。これを条件付き説明文生成法 (CSCG法: Conditional Sequence-to-sequence Caption Generation)と呼びます。本手法では、詳細度※4と呼ぶ数値をデコーダへの補助入力として導入します。学習段階では、詳細度の値と出力されるテキスト系列の双方の誤差が少なくなるように学習を行います。生成段階において、対象とする音響信号と望ましい詳細度の値とを入力すると、その詳細度に近いテキストが生成されます。このような方法をとることで、場面や用途に合うように、短く端的な説明や、長く詳しい説明を得ることができます。
(4)「聞こえ方」 の近さに基づく音の検索
本技術は様々な応用が可能と考えられます。その一つが音の検索です。従来、効果音などの音響データベースの検索では、対象となる音に対して事前にテキストのタグを付けておき、そのテキストに着目して検索する方法が一般的でした。しかし、事前にテキストのタグを付ける手間がかかったり、テキストのタグだけではどのような音かが分かりにくかったり、数多くの検索結果のうちどれが望みの音に近いかが音を聞かないと判断できなかったりといった問題がありました。これに対し、本技術を用いると、潜在空間における近傍探索によって、擬音語や説明文を問合せとして、音のデータベースを検索することが可能になります。この時、音響データベースに対して事前にテキストのタグを付ける必要は無く、任意の詳しさの説明文を問合せにすることができ、また、数多くの検索結果を潜在空間における近さの順に並べて出力することができるため、前述の問題点が緩和されます。本技術では、擬音語や説明文が近い音、つまり人間にとっての聞こえ方が近い音どうしが潜在空間において近くに位置付けられるため、主観的な「聞こえ方」の近さに基づく音の検索が実現されます。
今後の展開
上に挙げた音の検索の他に、動画中の音を文字で表現することで動画視聴の幅を拡大することや、AIが人間に近い音の感覚を身につけることでAIと人間との日常のコミュニケーションを円滑にすることなどが期待できます。これらの実現に向け、更に研究を進めていきます。
図1:本技術の仕組み
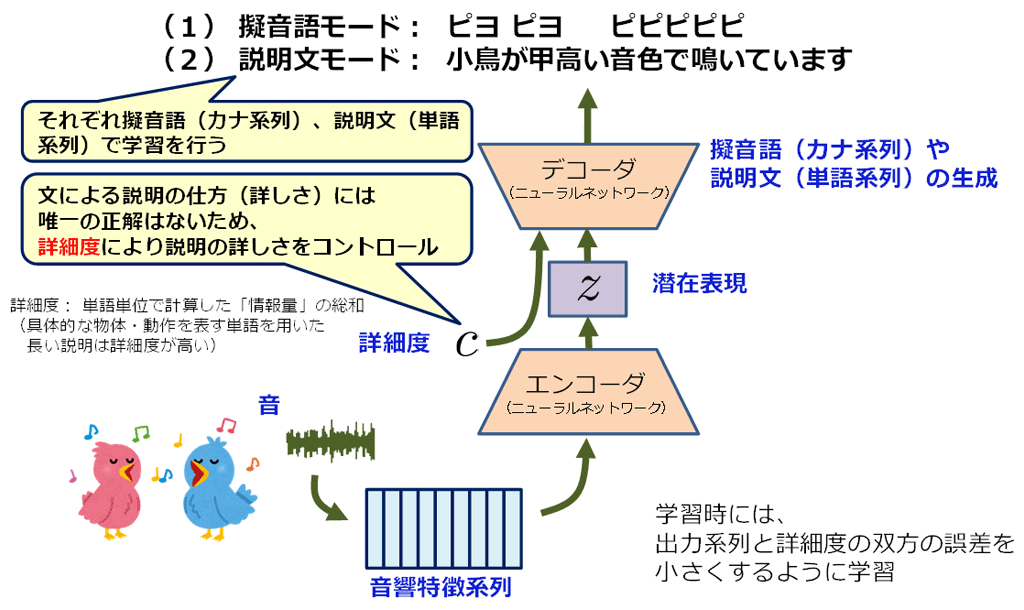
図2:本技術による説明文の生成例
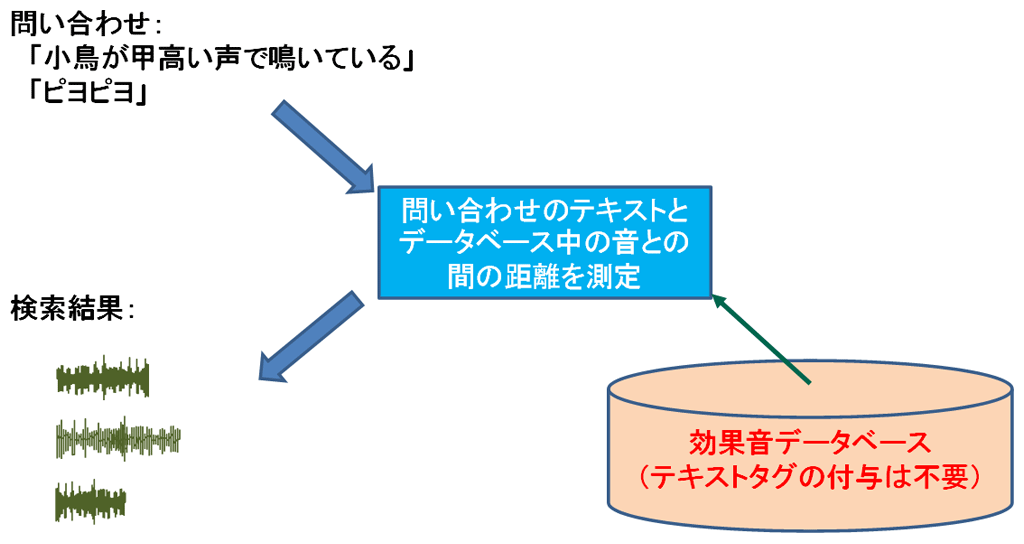
図3:音の聞こえ方に基づく音の検索への応用例
用語解説
※1多層ニューラルネットワーク神経回路網をモデルとした問題解決装置。神経回路網におけるニューロンに相当するノードを多層にわたって層状に結合させ、その結合強度を変化させることで入出力の関係を学習することを特徴とします。その学習は深層学習と呼ばれます。 ※2エンコーダ
ここでは、高次元のデータを低次元のデータに変換する機能をもつニューラルネットワークのことです。 ※3デコーダ
ここでは、低次元のデータを高次元のデータに変換する機能をもつニューラルネットワークのことです。 ※4詳細度
デコーダの動作を制御するための補助入力です。詳細度としては、例えば単語単位で計算した「情報量」の総和を用いることができます。具体的な物体・動作を表す単語を用いた長い説明は、詳細度の値が高くなります。 ※5研究協力の状況
本成果は、東京大学大学院情報理工学系研究科システム情報学専攻中村宏教授との共同研究の成果を含みます。
本件に関するお問い合わせ先
日本電信電話株式会社
先端技術総合研究所 広報担当
Tel 046-240-5157
Email science_coretech-pr-ml@hco.ntt.co.jp
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










