

2019年6月18日
日本電信電話株式会社
光通信で培った技術を応用し、情報処理システムの性能向上を実現する「光インターコネクト技術」を開発
~分散深層学習の高速化に成功。高度なAIサービスを実現する技術として期待~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田純、以下 NTT)は、情報処理システムの高性能化を目指した光インターコネクト技術を開発し、AI処理を高速化することに成功しました。
LSIの大規模化・高速化による処理能力向上が限界を迎える時代(ポストムーア時代)においては、CPUといった演算資源をインターコネクトで複数接続する分散処理が情報処理システムの性能を向上させる手法として期待されますが、この場合はインターコネクトの性能がシステムの能力に大きな影響を与えます。
今回、NTTは光通信用に研究開発を続けてきた高速プロトコル技術・通信処理回路技術を活用し、情報処理システムの性能向上を実現する光インターコネクトを開発しました。本技術を複数のサーバで大量のデータを分担して処理する「分散深層学習」に適用した結果、学習速度を従来技術比で7%高めること成功しました†1。この結果より、GPU台数を増やした場合の効果を見積もると、32GPU接続時に40%程度の速度向上が見込まれます†2 。
本技術は、NTTのAI「corevo®」†3を支える技術であり、将来のIOWN†4構想実現につながる新たな情報処理技術として今後研究開発を続けます。
本技術の詳細は、6月16日からドイツ、フランクフルトで開催されている国際会議ISC 2019にて発表予定です。
†1サーバ4台、1GPU/1サーバ時
†2サーバ4台、8GPU/1サーバ時
†3corevo®は日本電信電話株式会社の商標です(http://group.ntt/jp/corevo/)
†4IOWN(アイオン):「Innovative Optical & Wireless Network」
1.研究の背景
データ量の爆発的増大に伴い複雑化するデータ処理に対して、LSIの大規模化・高速化では処理能力向上の限界を迎える時代(ポストムーア時代)が到来しつつあります。ポストムーア時代に向け、演算リソースを複数接続し能力向上を図る分散処理が情報処理装置の性能向上の手法として期待されますが、そのためには演算リソース間のデータ共有が高速に行える高性能なインターコネクトが必要となります。
今回は、アプリケーションとしてAIに注目し、自動運転やゲノム解析などといった、リアルワールドの大量なデータを高速に処理するために数多くのサーバで分散処理を行う「分散深層学習」に適した光インターコネクトを目指しました。
2.研究の成果
分散深層学習においては、各サーバでの学習結果をインターコネクトを介し共有する通信を行いますが、この通信の早さがAIの学習速度に大きく影響します(図1)。今回、AIの学習結果共有を高速に行える光インターコネクトを新たに開発し(図2)、AI学習の高速化を実現しました。
現在用いられている市販品で最速の構成※1と本技術を用いた場合の比較測定を行った結果、4台のサーバ(1台当たり1GPU*1)を利用した場合、通信のために生じる演算待ち時間(通信オーバーヘッド)が84%以上削減されることを確認しました(図3)、この結果、学習速度が7%向上することを確認しました※2。
この測定結果をもとに、GPU台数を増やした場合の見積もりを行うと、GPU台数を増やした場合では演算に対する通信の時間の比率が高まるため、通信時間短縮の効果が大きく現れ、32GPU利用時に40%以上学習速度が向上する見積もりが得られました(図4)※3。
※1100Gbit/s InfiniBand + 市販最新GPUの組み合わせ
※2データセット:Imagenet、学習モデル:ResNet50、サーバ4台、1GPU/サーバでの実測
※2サーバ4台、8GPU/サーバでの見積もり
3.技術のポイント
本成果の光インターコネクトは、分散深層学習のデータ共有の高速化を、以下の3点の技術的ポイントで実現しました(図4)。
| ポイント1. | CPUやメインメモリを介することなく、学習処理を行うGPUと光インターコネクト間で直接データを授受できるようにし、演算リソース(GPU)と光インターコネクトをより密接に結び付けるGPU-光インターコネクト間ダイレクト通信 |
|---|---|
| ポイント2. | データを順に隣に送りながら加算することで効率的にデータ共有が行える100Gbit/sの高速光リングネットワークと、複雑なレイヤー処理を排除した光リングの高速性を活かすプロトコル |
| ポイント3. | データ共有処理を専用のハードウェアで高速に実行するアクセラレータ回路 |
4.今後の展開
大規模なAI学習を行うデータセンタに今回の技術を導入することで、今後の自動運転・遺伝解析・気象予測など、大量のデータを扱うAI学習処理の高性能・低消費電力化が期待されます。そのため、NTTのAI「corevo®」※4を支える基盤技術の一つとして開発を続けていきます。
さらには今後、爆発的に増大するデータ量や、複雑化するデータ処理に対して、LSIの大規模化・高速化では処理能力の向上が限界を迎える時代(ポストムーア時代)が到来します。ポストムーア時代のIOWN※5構想の実現に向けた、光と電子の利点を結び付けた新アーキテクチャによる情報処理システムを実現する技術として、今回開発した技術を応用・発展させていきます。
※4corevo®は日本電信電話株式会社の商標です(http://group.ntt/jp/corevo/)
![]()
※5IOWN(アイオン):「Innovative Optical & Wireless Network」
「NTT Technology Report for Smart World : What's IOWN?」の発表について
(http://group.ntt/jp/newsrelease/2019/05/09/190509b.html)
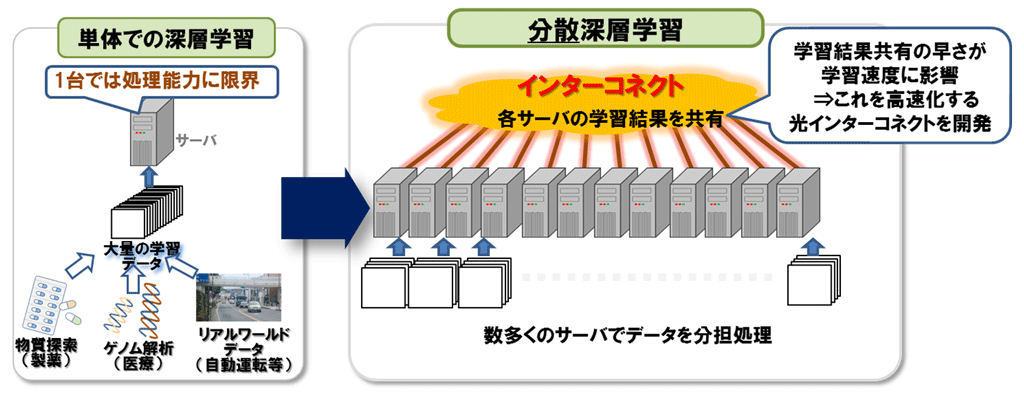 図1 分散深層学習と光インターコネクト
図1 分散深層学習と光インターコネクト
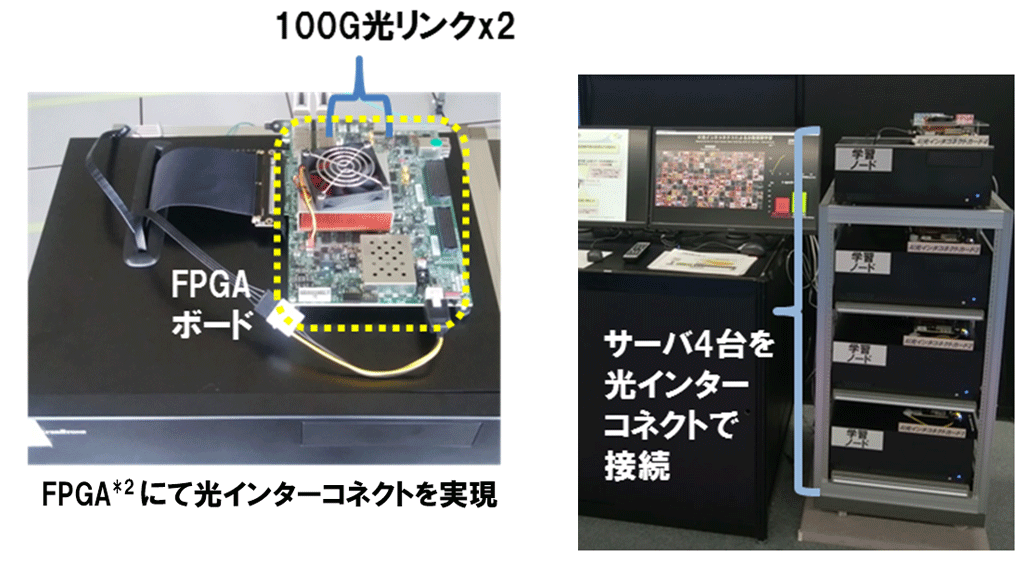 図2 今回成果の光インターコネクトによる通信
図2 今回成果の光インターコネクトによる通信
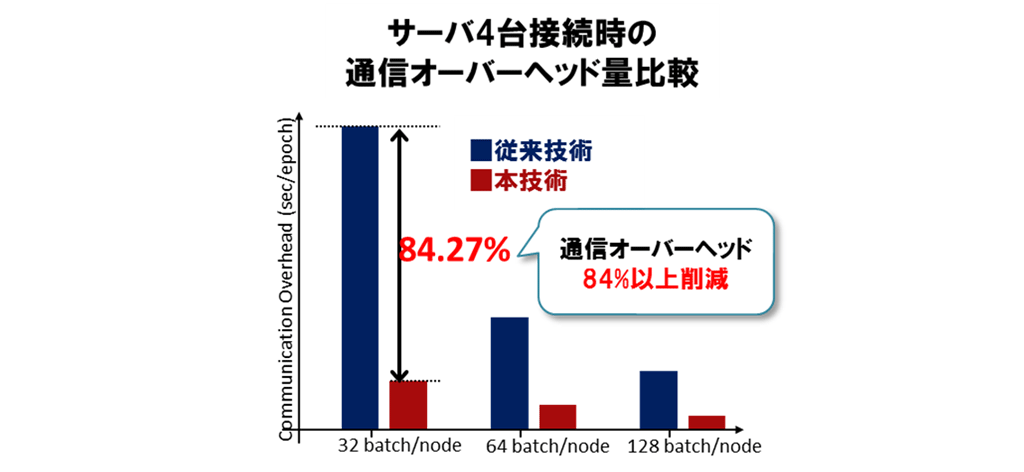 図3 従来技術と本成果の光インターコネクトによる通信オーバヘッド比較
図3 従来技術と本成果の光インターコネクトによる通信オーバヘッド比較
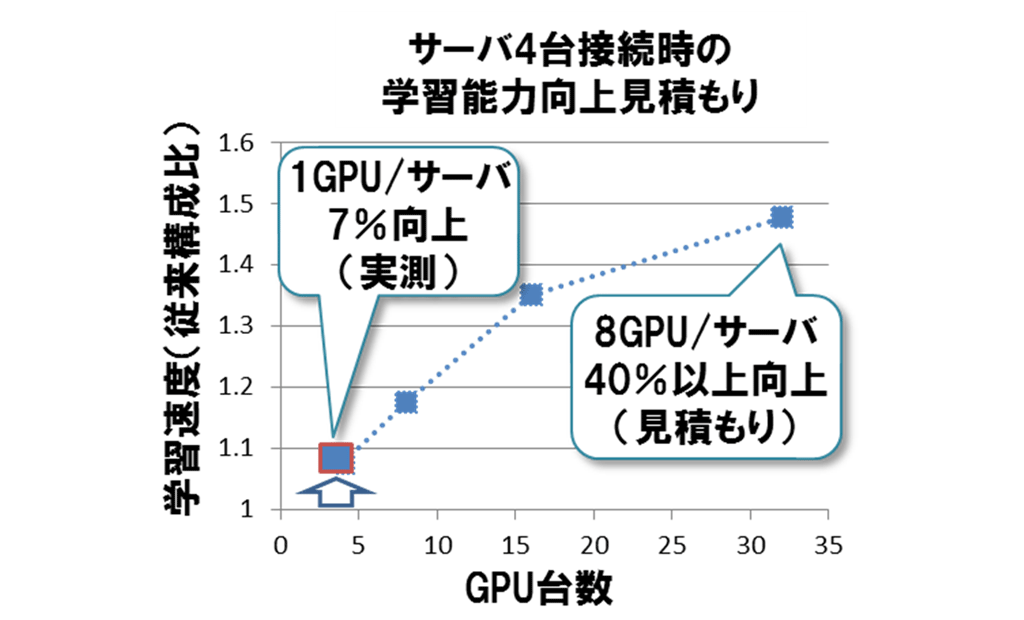 図4 学習能力向上の見積もり
図4 学習能力向上の見積もり
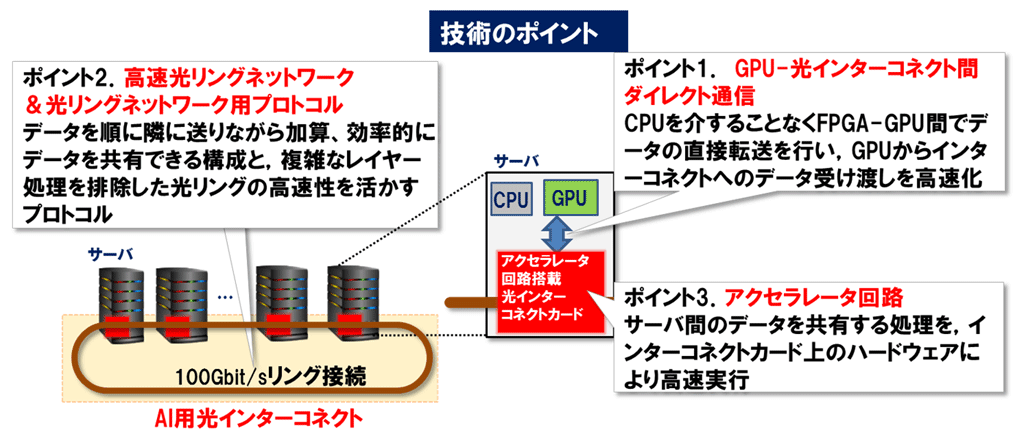 図5 本成果の技術ポイント
図5 本成果の技術ポイント
4.今後の展開
*1GPU:
Graphics Processing Unit。3Dグラフィックスの演算に特化したLSI。AIに必要な演算にも高い性能を発揮するため、近年ではAIの演算用に積極的に用いられる。
*2FPGA:
Field Programmable Gate Array。プログラミングにより内部の回路構成を変更可能なLSI。
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










