

2021年6月 2日
日本電信電話株式会社
取得条件が完全に未知なデータからでも学習可能な深層学習技術を創出
~AIの新たな適応能力を実現~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田 純、以下「NTT」)は、どのような条件で取得されたデータであるかがまったくわからない寄せ集めの学習データからであっても、高精度な認識モデルを学習可能な深層学習(※1)技術を実現いたしました。
深層学習は、質・量ともに十分な学習データが得られる場合には極めて高い認識性能を発揮する一方で、データ取得環境の照度や背景、撮影デバイスの違いといった、データの取得条件(※2)がさまざま混在するような学習データを用いて学習した場合に、大幅な性能低下を引き起こすことが知られています。本成果では、このような様々な取得条件が混在し、また、その条件が完全に未知な学習データに対し、データごとの取得条件の違いを教師なし学習によって推定することで、その影響を受けずに高精度な認識モデルを学習可能な深層学習技術を世界で初めて実現しました。
本技術によって、これまで学習に利用しにくかったデータを活用可能にし、AIの適用領域を拡大することが期待されます。
1.背景
深層学習を核とした人工知能(AI)の本格的な活用が期待されています。深層学習の性能を引き出すには、質・量を兼ね備えた学習データが不可欠です。特に、学習データとテストデータ(学習済みの認識モデルを実際に利用する際に入力されるデータ)の取得条件(例えば、照度や背景などの環境に依存する要因や撮影デバイス、制作・加工手段など)に"ずれ"がある場合、その認識精度が著しく低下することが知られています(図1)。AIを応用領域で実際に活用する際には、学習済みの認識モデルにはさまざまな条件で取得されたテストデータが入力される可能性があります。"ずれ"をなくして、認識精度の低下を防ぐためには、認識モデルを学習する段階で、さまざまな条件で取得した学習データを用いておく必要があります。しかし、これまでの深層学習では、取得条件が異なる学習データが混在する場合に、高精度な認識モデルの学習が難しいという問題がありました。さらに、現実世界において、起こりえる取得条件を事前にすべて想定・把握できるとは限りません。例えば、医療や介護のデータのように、個人情報保護の観点から、取得条件の一部が削除されるような場合や、監視や点検、SNSのデータのように、各々のデータの取得条件を把握することが極めて困難な場合などがあります。これらは、単に良質なデータを集めるだけでは解決が難しい技術課題であり、深層学習の利用拡大を妨げる要因となっていました。
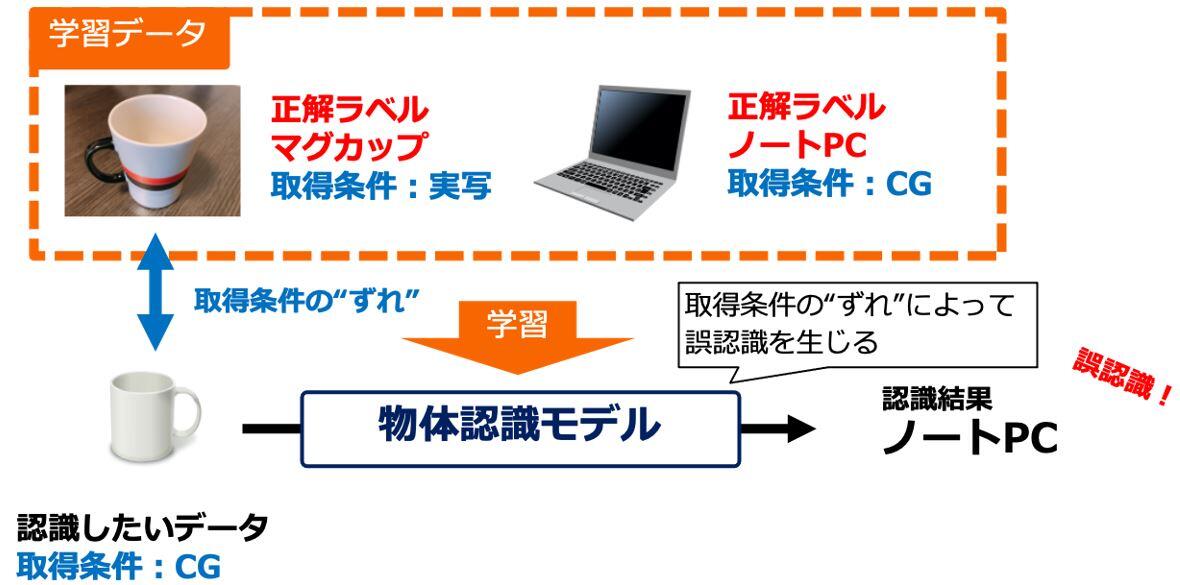 図1: 学習データとテストデータの"ずれ"による認識精度の低下
図1: 学習データとテストデータの"ずれ"による認識精度の低下
2.研究の成果
本成果では、様々な取得条件が混在し、さらに、事前にその条件がわからないような学習データからであっても、高精度な認識モデルを学習可能な深層学習技術を実現しました。さまざまな取得条件のデータが混在する場合に対して、これまでは、各取得条件に特化した認識モデルを学習し、それらを組み合わせる技術や、取得条件の違いによるデータの分布の差を小さくするように学習することで、取得条件の影響を受けない認識モデルを学習する技術などが検討されてきました。しかし、これらの既存技術はいずれも、事前に各データの取得条件がわかっている場合にしか利用できないものでした。
一方、本成果では、データごとの取得条件の違いを明らかにする新たなデータ拡張技術(※3)を考案しました。このデータ拡張技術を用いると、データを取得条件の違いによって教師なしで分類できるようになり、取得条件が完全に未知な寄せ集めのデータからでも、高精度な認識モデルを学習することが可能です。実際に、異なる取得条件が混在する特定のデータを用いて評価した場合、従来技術が3.6%の認識精度であったところ、本技術は77.4%と、大幅に上回る認識精度を達成するなど、取得条件の影響を受けない認識モデルを学習できることを複数のデータで確認しています。
当該技術分野において、様々な取得条件が混在し、また、その条件が完全に未知な学習データからの深層学習問題に取り組んだのは本研究が初めてです。本成果によって、これまで学習に利用できなかった領域のデータを活用可能にし、新たな領域でのAIサービスの実現を促進することが期待されます。
3.技術のポイント
本成果のポイントは、画像データを対象として、これらを取得条件ごとに教師なしで分類可能な技術を創出したことにあります。
画像撮影時の照度や背景、撮影デバイス、制作・加工手段などの取得条件は、例えば画像の平均的な明るさや背景の色・テクスチャ、あるいは、局所的なボケ具合や質感などとして画像上に表れます。このため、画像を一見しただけでは、クラスタリングなどの教師なしデータ分類手法を適用することによって、取得条件ごとにまとめあげることができるように思われます。しかし、これらの取得条件による違いは、認識したい対象物体に比べて不明瞭であることが多く、そのままデータ分類手法を適用しただけではその違いをうまく推定することができません。
そこで本成果では、画像に対して、あえて認識したい対象物体を判別不可能にするようなデータ拡張を適用することによって、取得条件に依存する情報のみを正確に捉える自己教師あり学習技術(※4)を創出しました。具体的には、本技術のデータ拡張では、画像をいくつかのブロックに分割し、各ブロックの位置をランダムに入れ替えます。この操作によって、図2のCGと実写の物体画像の例が示すように、認識したい対象物体の形状はバラバラになり、認識が難しくなる一方で、CGか実写かという取得条件に関わる情報は依然として容易に認識可能であることがわかります。このデータ拡張を適用した画像を用いて自己教師あり学習を行うことで、取得条件に基づいて正確にデータを分類することができるようになり、結果として取得条件の影響を受けない高精度な認識モデルを学習できるようになりました。
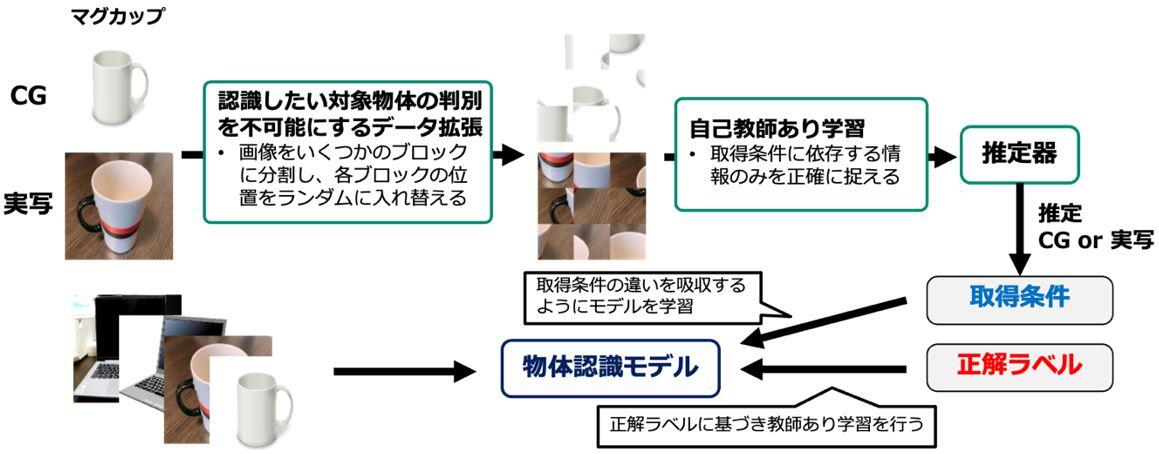 図2: 本成果によるデータ拡張技術と提案技術による学習の流れ
図2: 本成果によるデータ拡張技術と提案技術による学習の流れ
4.今後の展開
データの取得条件の違いによって生じる大幅な性能低下は、画像に限らず音声など映像情報メディアで一般的に直面する問題です。本成果で創出した、認識したい対象物体を判別不可能にするデータ拡張によって、取得条件の違いを分類する技術は、これら多くの映像情報メディアで有効であることが期待できます。
用語解説
※1深層学習:
ニューラルネットワークを多層に結合して表現・学習能力を高めた機械学習の一手法。単純に多層にするだけでは、表現力不足や過学習などの問題があったが、数々の工夫とビッグデータの助けにより解決され、現在、AIを構成するアルゴリズムとして、もっともよく用いられている。
※2データの取得条件:
パターン認識や機械学習分野においては「ドメイン」と呼ばれる。取得条件の違いによって、データを生成する確率分布に偏りが生じ、この偏りによる認識精度の低下が起こる。
※3データ拡張技術:
元のデータに対して単純な改変(拡大縮小や一部領域の切り出しなど)を施すことで、新しいデータを生成する技術。
※4自己教師あり学習技術:
データ拡張を適用してもその内容は変わらない性質を利用し、同一のデータに異なるデータ拡張を施して生成したデータ同士の特徴が一致するように学習する教師なし特徴学習技術。
本件に関する報道機関からのお問い合わせ先
日本電信電話株式会社
先端技術総合研究所 広報担当
science_coretech-pr-ml@hco.ntt.co.jp
℡ 046-240-5157
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










