

2015年12月14日
公共エリア雑音下でのモバイル音声認識の国際技術評価で、世界1位の精度を達成 ~ひずみなし音声強調とディープラーニング新技術により音声認識を高精度化~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:鵜浦博夫、以下 NTT)は、公共エリア(バス内・カフェ・商店街・市街地)の騒がしい環境でモバイル端末を用いて音声認識を行う技術評価国際イベントCHiME-3(The 3rd CHiME Speech Separation and Recognition Challenge)※1で、参加25機関中トップの精度を達成しました。
これは、NTTが独自開発したひずみなし音声強調技術※2とディープラーニング(深層学習)に基づく音声認識の新技術を用いることで、従来の限界を超える精度を実現したものです。本成果は、2015年12月13日(米国時間)より開催の国際会議The 2015 IEEE Automatic Speech Recognition and Understanding Workshop(ASRU 2015)※3にて発表されます。
背景
近年、ディープラーニング(深層学習)技術の進展に伴い、音声認識技術が急速に発展し、スマートホンなどの音声インタフェースに利用されるようになってきています。現在、音声認識は、主に、比較的静かな環境で人が話す場合に利用されています。これに対し、今後、公共エリアなどのように様々な雑音が聞こえている環境でも利用できるようになれば、利便性はさらに拡大していくと期待されます。このために、更なる音声認識の性能改善が求められています。
この実現を加速するために、本年、公共エリア(バス内・カフェ・商店街・市街地)の騒がしい環境でモバイル端末を用いて音声認識を行う技術評価国際イベントCHiME-3が企画されました。具体的には、公共エリア(バス内・カフェ・商店街・市街地)の騒がしい環境で、タブレット型モバイル端末に設置した6個のマイクロホンを用いて収録された英語新聞の読み上げ音声を認識していくというものです。従来の最新技術であるディープラーニングに基づく音声認識では、66.6%の音声認識率しか得られない難しい課題にもかかわらず、世界中から25もの重要研究機関が参加したほか、最先端の音声認識・理解技術に関する議論を行う国際会議IEEE ASRU-2015での公式チャレンジに採用されるなど、本企画の重要性が、世界中から注目を集めました。
研究の成果
NTTコミュニケーション科学基礎研究所は、図1に示す音声認識システムを開発してCHiME-3に参加し、図2に示すように、94.2%という高い音声認識率(参加25機関中トップの精度)を実現しました。
NTTコミュニケーション科学基礎研究所ではかねてより、騒がしい環境での音声認識は、ユーザの利便性向上のために必須の課題であると位置づけ、長年、そのための研究に取り組んできました。今回、これまでに培った技術に加えて、ひずみなし音声強調、および、ディープラーニング(深層学習)を用いた音声認識の新技術を開発し、CHiME-3でトップ精度を達成した高精度な音声認識システムの実現に成功しました。
技術のポイント
(1)雑音や残響が混ざった音声に対しても高精度な音声認識を実現する音声認識部
NTTが従来から開発を続けてきたディープラーニングに基づく最新音声認識技術に、以下の新技術を加えることで、大幅な性能改善が得られました。
(1)CNN-NIN(Convolutional Neural Network and Network In Network)※4(図3):画像処理で有効性が確認されている雑音に頑健なニューラルネット技術。今回、世界で初めて音声認識に導入し、その有効性を実証。
(2)WFST型RNN言語モデル※5(図4):長い文脈依存性を考慮して高速・高精度な音声認識を実現する技術。
その結果、音声認識部だけを用いる場合でも、音声認識率84.4%を達成できました (図2中央)。
(2)騒がしい環境において音声認識を劣化させる主要因である雑音や残響を、収録音から抑圧する音声強調部
これまで、ディープラーニングに基づく音声認識では、音声強調処理で雑音などが低減されるのと一緒に音声が変形されてしまうと、音声認識の改善が得られなくなるという課題がありました。
これを克服するために、今回、収録音に含まれる音声を原理的にひずませることなく、雑音や残響だけを低減できる「ひずみなし音声強調技術※2」(図5)の開発に成功し、その結果、上述のディープラーニングに基づく音声認識部と組み合わせることで、CHiME-3では、音声認識率を94.2%まで大幅に向上できることを示しました。
今後の展開
今回実現した要素技術について、2018年頃の音声認識サービスへの導入をめざし、研究開発を進めます。具体的には、CHiME-3では、6個のマイクロホンを利用していたのに対し、より少ないマイクロホンを用いたシステムでの性能評価や、リアルタイム動作の実現に向けた検討を行っていきます。
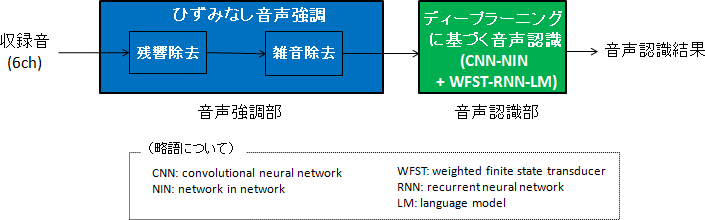 図1:音声認識システムの構成
図1:音声認識システムの構成
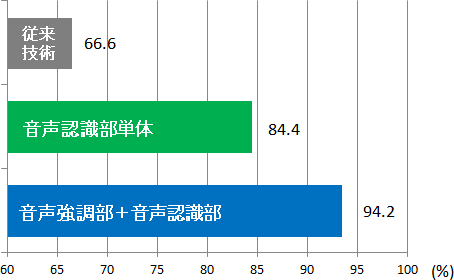 図2:音声認識性能の評価結果
図2:音声認識性能の評価結果
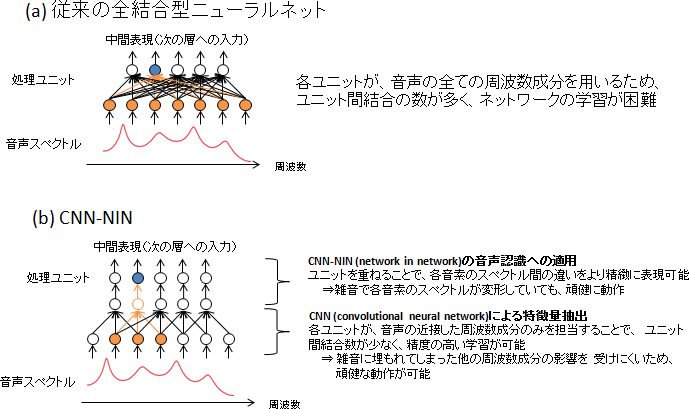 図3:CNN-NINの音声認識への適用
図3:CNN-NINの音声認識への適用
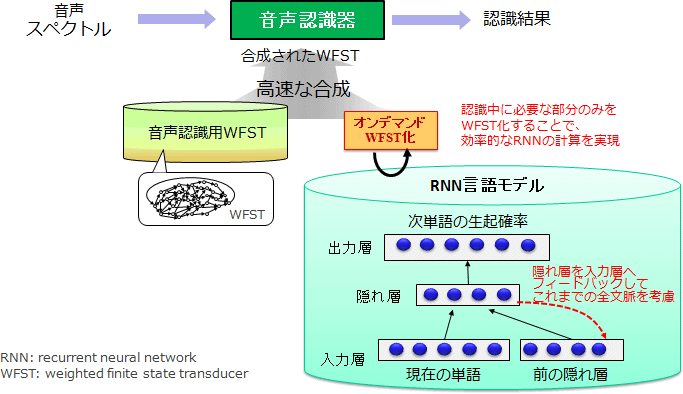 図4:WFST-RNN-LM:長い文脈依存性を考慮した高速・高精度音声認識
図4:WFST-RNN-LM:長い文脈依存性を考慮した高速・高精度音声認識
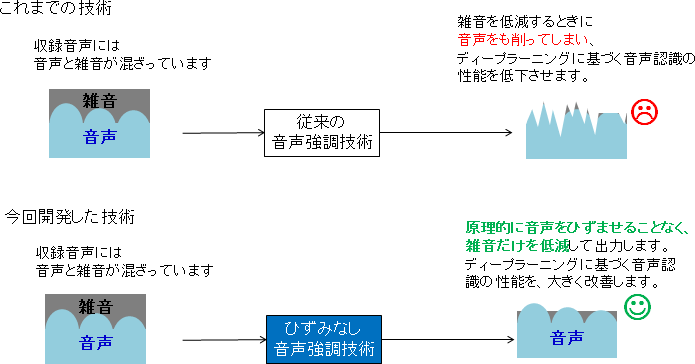 図5:ひずみなし音声強調技術
図5:ひずみなし音声強調技術
用語解説
※1CHiME-3(The 3rd CHiME Speech Separation and Recognition Challenge)
従来技術では困難とされるシビアな雑音環境下での音声認識を可能とするために、挑戦的な共通課題を設定し、世界のトップ研究機関が最新技術成果を評価しあう国際イベント。今回で、3回目の開催。今回の課題は、公共エリア(バス内・カフェ・商店街・市街地)の騒がしい環境でタブレット型モバイル端末に設置した6個のマイクロホンを用いて収録された音声データベースを用いた音声認識。雑音のレベルが非常に高く、従来の最新技術であるディープラーニングに基づく音声認識を用いても、66.6%の音声認識率しか得られない難しい課題。
CHiME-3 ホームページ:http://spandh.dcs.shef.ac.uk/chime_challenge/index.html
![]()
※2ひずみなし音声強調技術(図5)
音声にひずみを生じさせない拘束条件のもと、残響や雑音のみを低減し、音声を抽出する技術。この拘束条件は、空間中の音の伝わり方に関する物理特性を表した数理モデルに基づき与えられる。数理モデルが実際の収録環境の音の伝わり方と合致していれば、原理的に音声にひずみが生じない。
※3国際会議 The 2015 IEEE Automatic Speech Recognition and Understanding Workshop(ASRU 2015)
米国電気電子学会IEEEが主催し隔年開催されている学術的国際会議で、世界中の研究機関・企業から研究者が集まり、最先端の音声認識・理解技術に関する議論が行われている。2015年の開催地は米国スコッツデールで、開催期間は12月13日(日)から17日(木)。
ASRU 2015 ホームページ:http://www.asru2015.org/default.asp
![]()
※4CNN-NIN(図3):
CNNとは、近接した入力成分のみから特徴抽出するニューラルネット技術(図3(b))。従来のニューラルネット(図3(a))に比べてユニット間結合数が少ないことから、精度の高い学習ができる特長があるうえ、音声の近接した周波数成分のみを使うので、雑音に埋もれた周波数成分の影響を受けにくい頑健な動作が可能。
CNN-NINは、CNNにさらにユニットを重ねて特徴抽出をする技術。各音素に対応するスペクトル間の違いをより精緻に表現できるため、雑音で各音素のスペクトルが変形していても、頑健な音素識別ができる。
※5WFST型RNN言語モデル(図4)
長い文脈依存性を考慮して高速・高精度な音声認識を実現する技術。再帰型ニューラルネット言語モデル(Recurrent Neural Network Language Model, RNN-LM)を用いた高精度な単語予測を、重み付き有限状態トランスデューサ(Weighted Finite State Transducer, WFST)を用いて高速に実現する技術。
本件に関するお問い合わせ先
日本電信電話株式会社
先端技術総合研究所 広報担当
TEL 046-240-5157
Email a-info@lab.ntt.co.jp

ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










