

2018年5月28日
世界初、声の特徴に基づき "聞きたい人の声" を抽出する技術を実現 ~深層学習の新技術により、騒がしい環境で特定の声のみを抽出可能に~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:鵜浦博夫、以下 NTT)は、複数の人の声が混ざった音声から、目的話者の声の特徴に基づき、その人の声だけを選択的に抽出する技術SpeakerBeam※1を実現しました。
本技術は、様々な声や雑音が聞こえている環境において、目的話者の声の特徴やその位置だけに注目して、その声を聞き取る人間の聴覚の能力「選択的聴取※2(図1参照)」と同等の機能を実現したことに相当します。選択的聴取のうち、話者の位置に注目して声を聞き取る能力※3は、すでにコンピュータでも実現されていましたが、目的話者の声の特徴に注目して聞き取る能力は、本技術が世界初です。今回、NTTが独自開発した深層学習※4の新技術を用いて、この実現に成功しました。
本技術を用いることで、目的話者がどこで話すかわからない状況などでも、その声の特徴に注目して音声を抽出することができます。今後、人の会話を理解する音声認識・ロボット技術などに、本技術を応用していく予定です。
【動画】https://www.youtube.com/watch?v=BM0DXWgGY5A![]()
リンク先は外部サイトとなります。
背景
近年、コンピュータによる自動音声認識技術が急速に発展し、スマートホンやスマートスピーカなどの音声インタフェースで利用されるようになってきました。しかし、日常の様々な場面では、複数の人が会話をしていたり、テレビの音声が背景で流れていたりするなど、目的話者以外の声が混ざって収録されることが、しばしば起きます。現在の音声認識技術では、目的話者だけに注目してその声を聞き取ること(選択的聴取)ができないため、このような状況にうまく対応することができませんでした。
研究の成果
NTTコミュニケーション科学基礎研究所は、図2に示すように、複数の人の声が混ざった収録音を入力音声として受け取り、その中から目的話者の声のみを抽出する技術 SpeakerBeam を開発しました※5。SpeakerBeam では、目的話者の声を識別できるようにするために、入力音声とは別に収録した目的話者の声(約10秒程度以上)を補助情報として利用します。そして、補助情報から抽出した声の特徴に基づき、その特徴に合致する音声を収録音から抽出します。
SpeakerBeam は、収録音にどんな音が含まれているかに依らず、目的話者の声の特徴のみに注目して、その特徴に合致する音声を抽出します。マイク1本でも処理が可能なのに加えて、より多くのマイクが利用できれば、さらに品質の良い音声の抽出ができます。
複数の話者の声を混合した入力音声を用いたシミュレーション実験により、SpeakerBeam は、音の聞き取りやすさを改善し(図3左参照)、音声認識精度を60%改善する(図3右参照)ことが確認されています。
技術のポイント
(1)目的話者の声の特徴に基づく選択的聴取
人の声には、声の高さ、声質、抑揚、強勢、音長、リズムなど、様々な個性があります。人の聴覚は、これらの個性の違いに基づき、混ざっている声の中からでも、特定の話者の声の特徴に注目して(かつ、その他の音は無視して)、目的の声を聞き取ることができます。特に、一度でも、その人の声を聞くことで、瞬時にその特徴を理解し、その声を聞き分けることができるようになります。本技術は、この能力と同等の機能をコンピュータで実現しました。
人の声の特徴は、前記の各要素が複雑に絡み合って形成されています。このため、声の特徴のどの部分に注目すれば、選択的聴取が実現できるかは、明らかではありません。本技術では、後述の深層学習の新技術を用いて、声の特徴の抽出方法、および、声の特徴に基づく声の抽出方法の両方を、データから同時に学習する仕組みを構築しました。その結果、比較的短い発話からでも声の特徴を抽出し、選択的聴取が行えるようになりました。
選択的聴取とは対照的な能力を実現する技術に、音源分離があります。音源分離は、収録音に含まれている話者の数が既知であるとの前提の下で、何らかの音の特徴(音の到来方向など)に基づき、収録音を話者数と同じ数の音に分解する技術です。すべての音を取り出せる利点がある一方で、話者数の情報が必要、すべての話者の位置や雑音の統計量の推定が必要、分離音のどれが目的話者かの推定が必要などの課題があります。このため、現時点では、その適用範囲は必ずしも大きくありません。
これに対し、SpeakerBeamによる選択的聴取では、目的話者の声に注目して、その特徴に合致する音を取り出すというシンプルな処理で、目的話者の声の抽出を実現できます。
(2)SpeakerBeamのための深層学習の新技術
SpeakerBeamの実現のために、図4に示した構造を持つニューラルネットワークを考案しました。主ネットワークと、補助ネットワークの二つで構成されており、それぞれ、以下の機能を実現します。
- (1)主ネットワークは、入力音声を受け取り目的話者の音声を出力します。多層のネットワークからなり、その中に、適応層と呼ばれる特別な層を含んでいます。適応層は、ネットワークの制御情報として、補助ネットワークが抽出した目的話者の声の特徴を受け取り、その特徴に合わせて、目的話者の声の抽出ができるように処理を変更する仕組みを持ちます。
- (2)補助ネットワークは、入力音声とは別に収録した目的話者の声を補助情報として受け取り、多層のネットワークを用いて、その声の特徴を抽出して出力します。
SpeakerBeamでは、上記の二つのネットワークを組み合わせた状態で用いた時に最適な選択的聴取が実現できるように、多数の話者や背景雑音を含む大量の学習データを用いて、各ネットワークの処理を事前学習します。その結果、学習に含まれていない目的話者に対しても、選択的聴取が行えるようになります。
今後の展開
今回実現した技術について、今後、似た声の人でも聞き分けられるようにするなどの点で性能改善を進めつつ、実環境において、人の会話を理解するコンピュータを実現するための要素技術として、本技術の応用の検討を進めます。
 図1 人間の聴覚による声の選択的聴取
図1 人間の聴覚による声の選択的聴取
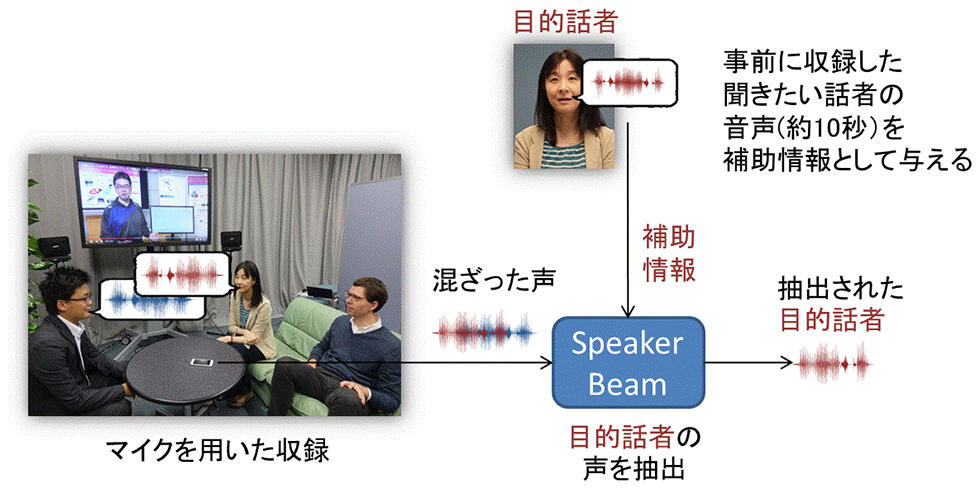 図2 SpeakerBeamによる声の選択的聴取
図2 SpeakerBeamによる声の選択的聴取
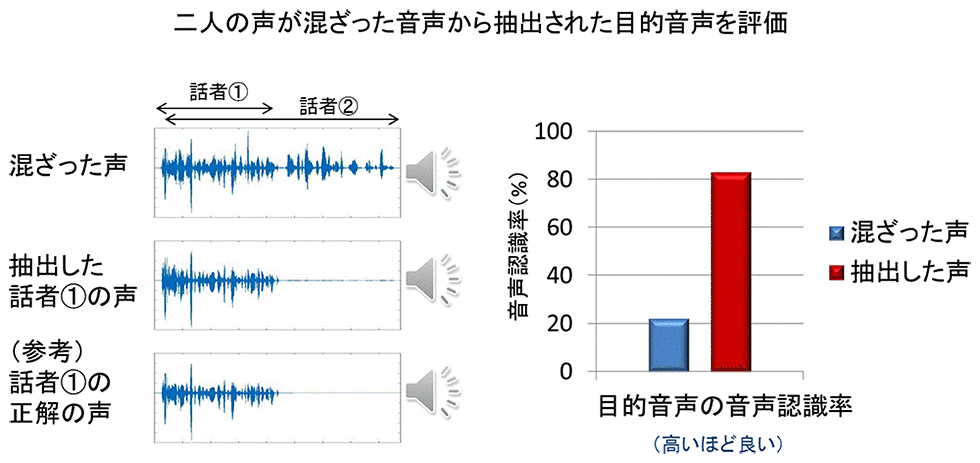 図3 SpeakerBeamによる音質改善と音声認識精度改善
図3 SpeakerBeamによる音質改善と音声認識精度改善
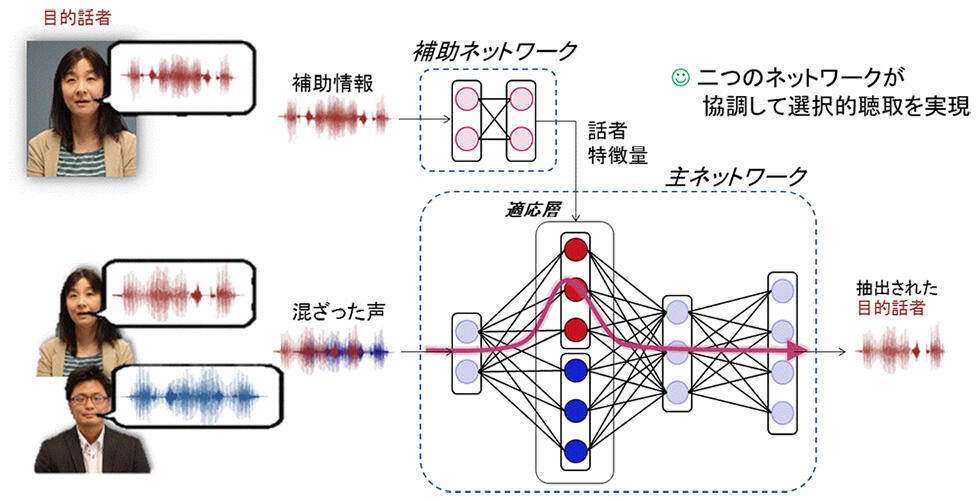 図4 SpeakerBeamのための深層学習の新技術
図4 SpeakerBeamのための深層学習の新技術
用語解説/h3>
※1SpeakerBeam
聞きたい人の声の特徴に注目して、その人の声を選択的に抽出するNTT音響処理技術の技術名称。特定の方向に音の指向性を向けて、その方向から到来する音を抽出する複数マイク処理技術をビームフォームと呼ぶのになぞらえて、特定の話者の特徴に注目して、その特徴に合致する音声を抽出する本技術をSpeakerBeam と名付けました。
※2選択的聴取
多数の音が聞こえている状況で、興味のある音だけに注意を向け、その他の音を無視して、目的の音を聞き取る能力のことを選択的聴取と呼びます。この能力を利用することで、例えば、人は、騒がしい環境にいるときでも、話し相手の声だけに集中して会話をすることができます。(この能力は、カクテルパーティ効果とも呼ばれています。) SpeakerBeam は、この能力に相当する機能をコンピュータで実現しました。背景音の状態(どんな音がいくつ含まれているかなど)に依らず、目的話者の声の特徴に注目して、その声を抽出することができます。
※3音の到来方向に基づく音声抽出
収録に用いられるマイクから見て、目的話者の声が到来する方向が分かっている場合、その方向にマイクの指向性を向けることで、混ざった声の中からその声だけを抽出することができます。また、目的話者の方向が分からなくても、同時に話している話者やその他の音源の数が分かれば、音源分離を用いて、収録音からすべての話者や音を分離できます。しかし、多くの日常的な場面では、話者の位置を定められなかったり、背景でいつどのような音声や音が生じるかは予期できなかったりします。また、仮に、すべての音声が分離できたとしても、目的話者の声を聞き取るためには、さらに、どれが目的話者であるかを推定する必要があります。
これに対し、SpeakerBeam では、音の到来方向に基づく方法と違い、話者の位置や、目的話者以外に話している人の数、その他の音の状態などに依存せずに、目的話者の声のみを抽出することができます。このため、話者がどこで話すかわからない、また、予期できないタイミングで他の音声や様々な音が混在するような状況にも、対応することができます。
※4深層学習
深い階層構造を持つニューラルネットワークを用いた機械学習の手法。ディープラーニングとも呼ばれます。大量の学習データを用いてニューラルネットワークのパラメータを最適化することで、所望の入出力関係を精度よく学習できることから、音声認識、画像認識、機械翻訳などのメディア処理において、幅広く利用されています。なお、従来の深層学習では、固定の入出力関係をニューラルネットワークで学習するのが一般的であるのに対し、SpeakerBeam のためのニューラルネットワークは、補助ネットワークの出力に応じて、主ネットワークの一部のパラメータを変更することができ、その結果、目的話者の声の特徴に応じて異なる入出力関係を持つことができるという特長を持っています。
※5研究協力の状況
本成果の一部は、Brno University of Technology との共同研究によるものです。
本件に関するお問い合わせ先
日本電信電話株式会社
先端技術総合研究所 広報担当
TEL:046-240-5157
Email:science_coretech-pr-ml@hco.ntt.co.jp
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










