

2019年9月 2日
日本電信電話株式会社
暗号化したままディープラーニングの標準的な学習処理ができる秘密計算技術を世界で初めて実現
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田純、以下NTT)は、データを暗号化したまま一度も元データに戻さずに、ソフトマックス関数*1やAdam(adaptive moment estimation)*2と呼ばれる最適化処理を含む標準的なディープラーニングの学習処理を行う技術を、世界で初めて実現しました。
通常、データを利活用するためには、通信時や保管時に暗号化していたとしても、処理を行う際には元データに戻して処理する必要があります。このことは、データ所有者からすると情報漏洩のリスクを感じることから、企業秘密や個人のプライバシーに関わるデータの利活用に抵抗感を持つユーザや組織が少なくありません。特に所有者から他者、または同一組織内であっても、データ提供して積極的に利活用したい場合には、このことは大きな障害だと考えられます。
今回開発した技術を用いることで、企業秘密や個人のプライバシーにかかわるデータをディープラーニングで活用する際に、サーバではデータを暗号化したまま一度も元データに戻さずに処理することが可能となります。つまり、ディープラーニングでのデータ活用に必要な (1)データ提供、(2)データの保管、(3)学習処理、(4)予測処理、の全てのステップを暗号化した状態で行えます。サーバでは常にデータは暗号化されたままであり一度も元データに戻すことがないため、従来よりもユーザや組織が安心してデータを提供でき、学習に利用できるデータ量や種類が増え、精度の高いAIの実現が可能になると考えています。
なお本成果は、9/3から開催されるFIT2019(第18回情報科学技術フォーラム)、および10/21から開催されるCSS2019(コンピュータセキュリティシンポジウム)にて発表予定です。
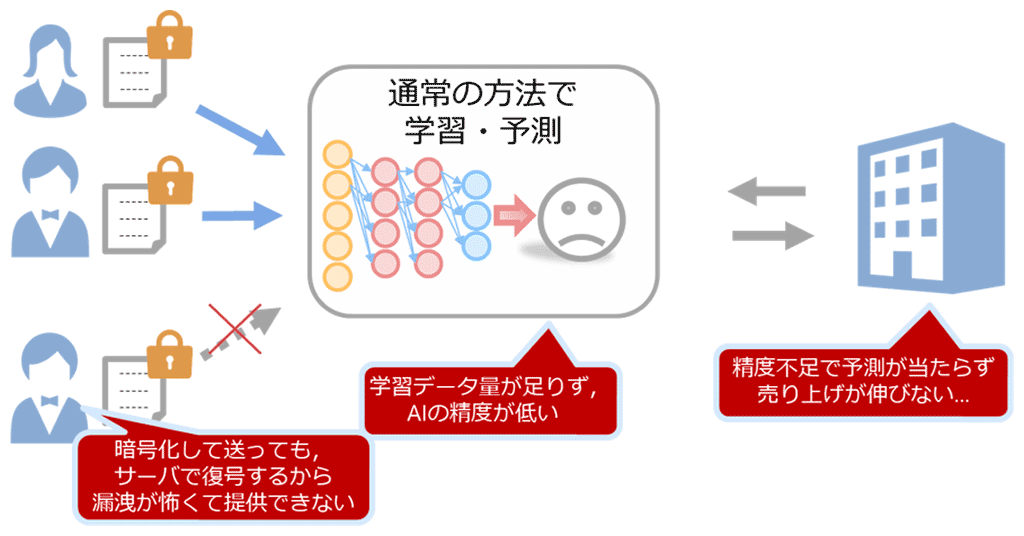 図1:秘密計算がないディープラーニングシステム
図1:秘密計算がないディープラーニングシステム
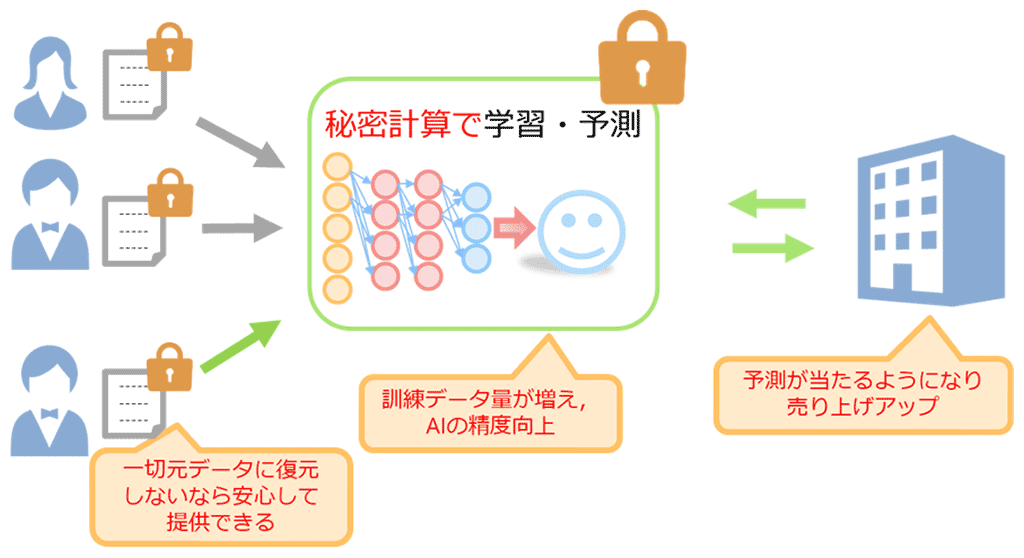 図2:秘密計算を導入するメリット
図2:秘密計算を導入するメリット
背景
昨今、様々な分野のデジタルトランスフォーメーションが進んでおり、分野横断的なデータの蓄積やAIなどの高度分析がイノベーションを促進し、様々な産業・サービスが発展すると期待されています。その一方で、情報漏洩や不正利用の懸念がデータの提供・利活用促進を阻害する要因となっています。
NTTはそのような要因の解消に貢献するため、データを暗号化したまま一度も元データに戻さずに処理ができる秘密計算技術の研究開発を世界に先駆けて取り組んできました。NTTが取り組む秘密計算技術は、ISO国際標準*3である秘密分散技術を利用して暗号化されたデータを、一度も元データに戻さずに分析を行うため、企業の秘密情報や個人のプライバシーに関わる情報などの情報を安全に、安心して提供し利活用できる社会の実現に貢献すると期待されております。
今回、NTTはAIのなかでも活用が進み始めているディープラーニングの標準的なアルゴリズムについて、暗号化したまま一度も元データに戻さずに処理できる技術を世界で初めて実現しました。この技術によって、企業秘密や個人のプライバシーにかかわるさまざまな情報を活用する際、データ所有者からのデータ提供の安心感を高めることができ、データの量や種類の増加や、これに伴う精度向上・高度分析の実現につながると考えます。例えば、個人の位置情報やスケジュールを暗号化したまま、天気や企業のイベント情報などと併せて学習することで、最適な飲食店の仕入れや人員リソースの配備を予測することが考えられます。また、さらにこの技術を応用すれば、レントゲン写真、MRI、CTスキャン、顕微鏡写真などの医療データを秘匿しつつ学習し、検査結果に悪性腫瘍があるかなどを高速かつ精度よく判定することが可能になると期待されます。
技術のポイント/特徴
秘密計算ではデータを暗号化したまま一度も元データに戻すことなく処理を行うため、その処理方法は通常の処理方法とは大きく異なります。そのため、暗号化していないデータでは簡単に処理できても秘密計算では実現が難しいという、不得手な処理がありました。秘密計算でこのような処理を行うには新しい技術や工夫が必要となります。
一般にディープラーニングの学習では、訓練データを入力として、複数の層を順番に処理して学習の途中結果を得て、その途中結果が十分に学習されたものであればそれを最終結果として出力し、そうでなければ途中結果を更新する処理(最適化処理)を行い、もう一度最初の層の処理から一連の処理を繰り返します。複数の層のうち最後の層は出力層と呼ばれ、標準的にはソフトマックス関数と呼ばれる数式を計算します。また、最適化処理ではSGD(Stochastic Gradient Descent)が原始的な手法として知られていますが、繰り返しの回数が多いため、SGDを改善したAdamなどが主に用いられています。これらディープラーニングの標準的な学習処理で用いられるソフトマックス関数やAdamでは、割り算、指数、逆数、平方根を組み合わせた処理を行います。
ディープラーニングの学習を秘密計算で行うとき、従来技術では上にあげた割り算、指数、逆数、平方根が秘密計算にとって不得手な処理なため、秘密計算でソフトマックス関数やAdamを計算することは困難でした。そのため、多くの先行研究は学習・予測のうちこれらを計算しなくてもよい予測のみに絞ったものでした。また、幾つかは学習に取り組んだ先行研究もあるものの、ソフトマックス関数を非常に粗い精度で近似し、且つ最適化処理は標準的にはあまり用いられないSGDしか使用できませんでした。
今回、NTTは従来では計算が困難であったソフトマックス関数を高速かつ精度良く計算し、さらに主要な最適化処理であるAdamを利用できる秘密計算技術を開発しました。実現方法には2つの異なるアプローチがあり、それぞれの開発を行いました。 1つはソフトマックス関数やAdamを計算するために、あらかじめ入出力の組を並べた対応表を用意し、入力と対応表を暗号化しつつ、入力に対応する出力が得られる秘匿写像と呼ばれる独自技術を利用するアプローチです。もう1つはソフトマックス関数やAdamを構成する割り算、指数、逆数、平方根それぞれについて専用の高速アルゴリズムを開発するアプローチです。前者はFIT2019、後者はCSS2019でそれぞれ発表予定です。
この技術を用いることで、データを暗号化したまま、標準的なディープラーニングのアルゴリズムを用いて学習することが可能となりました。例えば今回開発した割り算・指数・逆数・平方根の専用アルゴリズムを用いる行う方法では、60,000件の手書き文字を判別するモデル学習*4において、1エポックの学習*5を5分強で実行することができます。
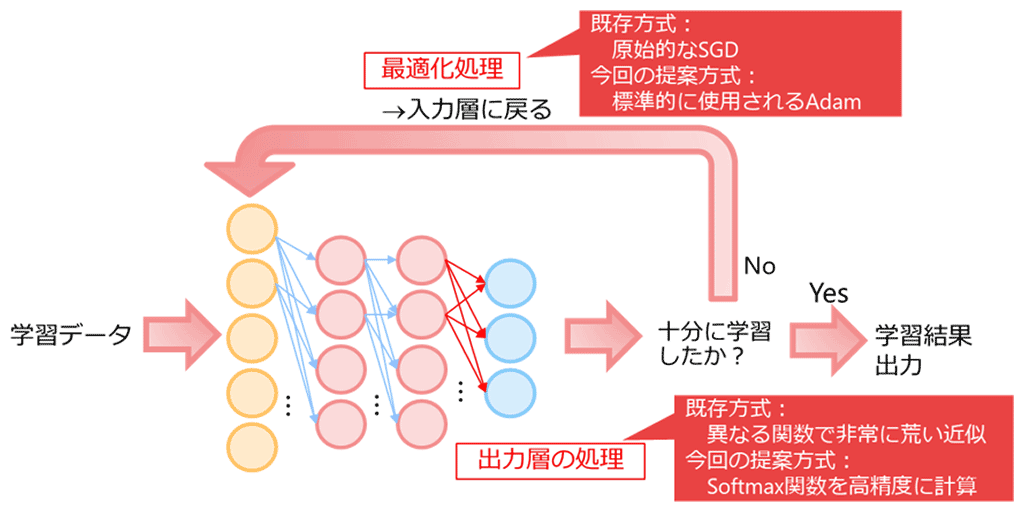 図3:ディープラーニングの学習の模式図
図3:ディープラーニングの学習の模式図
今後の展開
今後はAIの知見を持つパートナーと連携して実証実験等を行うことで、秘密計算を使ったディープラーニングの効果を実証していきたいと考えております。最終的には誰もが安心してデータの提供と利活用ができる環境を提供していきたいと考えております。
注釈
*1ソフトマックス関数:
主にクラス分類などで、ディープラーニングの出力層において計算される関数です。複数の入力 (x1,...,xn) から、0から1までの値
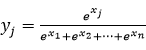
を出力します。
*2Adaptive moment estimation:
学習でパラメータを更新する最適化処理の一つです。原始的な方法を改良し良い学習結果を得やすく[Ruder16]、多数の機械学習フレームワークでも利用されています。詳細は参考文献[KB15]をご参照ください。
[Ruder16] Sebastian Ruder, An overview of gradient descent optimization algorithms. arXiv:1609.04747, 2016. [KB15] Diederik P. Kingma, Jimmy Ba, Adam: a Method for Stochastic Optimization. International Conference on Learning Representations, 2015.
*3ISO/IEC 19592-2 Information technology-Security techniques-Secret sharing-Part 2:
Fundamental mechanisms.
*4MNIST database, http://yann.lecun.com/exdb/mnist/.![]()
*5一般に機械学習では訓練データを何度も繰り返し学習しますが、そのうち訓練データを1回学習させることを1エポックの学習と呼びます。
本件お問い合わせ先
日本電信電話株式会社
サービスイノベーション総合研究所
企画部広報担当
E-mail:randd-ml@hco.ntt.co.jp
Tel:046-859-2032
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










