

2020年6月 3日
日本電信電話株式会社
令和版単語親密度データベースの構築と語彙数推定テストの作成
~語彙数推定から学習支援へ~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田 純、以下「NTT」)は、約20年前に作成した、単語のなじみ深さを示す単語親密度のデータベースを更新し、約16万3千語からなる『令和版単語親密度データベース』を構築しました。
また、小中高校生を含む約4,600人の語彙数調査を実施し、各学年・年齢における語彙獲得状況を、単語親密度に対応付けてモデル化しました。この結果は、児童・生徒がこれから獲得していくであろう、あるいは獲得した方がよい語を見つけ出す手がかりとして単語親密度が有効であることを示唆します。これらの分析結果を反映し、令和版語彙数推定テストを作成しました。
本成果は、言語心理学や自然言語処理などの学術分野では、基盤的言語資源として分野の発展に貢献するとともに、学校教育分野では、児童・生徒の学習支援を行う上での貴重な手がかりとなります。
1.研究の背景
単語親密度とは、語のなじみ深さを成人による評定実験によって数値化したものです。NTTでは20年以上前から単語親密度などの基盤的言語資源の構築に取り組んできました。過去に調査した約7万7千語からなる平成版の単語親密度データベースは、NTTデータベースシリーズ「日本語の語彙特性」として公開され、言語心理学や言語教育、言語聴覚療法分野などの基礎指標として幅広く活用されてきました。しかしながら、調査から時間が経ち、単語親密度自体が時代とともに変化している可能性や、新しく出現した語(「インターネット」や「コンビニ」など)に対応していないといった問題がありました。
また、単語親密度に基づいて抽出した少数の語のチェックから、回答者の語彙数を簡単に推定できる「語彙数推定テスト」は、弊社のウェブサイトで公開後、多くの方に様々な用途で利用していただきました。しかし、推定できる語彙数の上限が単語親密度データベースのサイズに依存し、7万7千語以上の語彙数は推定できないという問題がありました。また、語彙数の推定において参照する単語親密度自体が変化している可能性から、テストで利用する項目なども時代変化に合わせた更新が必要でした。
さらに、これまでは児童・生徒を対象とした語彙数調査はほとんど実施されておらず、児童・生徒の語彙数調査方法の確立が求められていました。
2.研究の成果
(1)過去最大の単語親密度データベースを構築、経年変化を調査
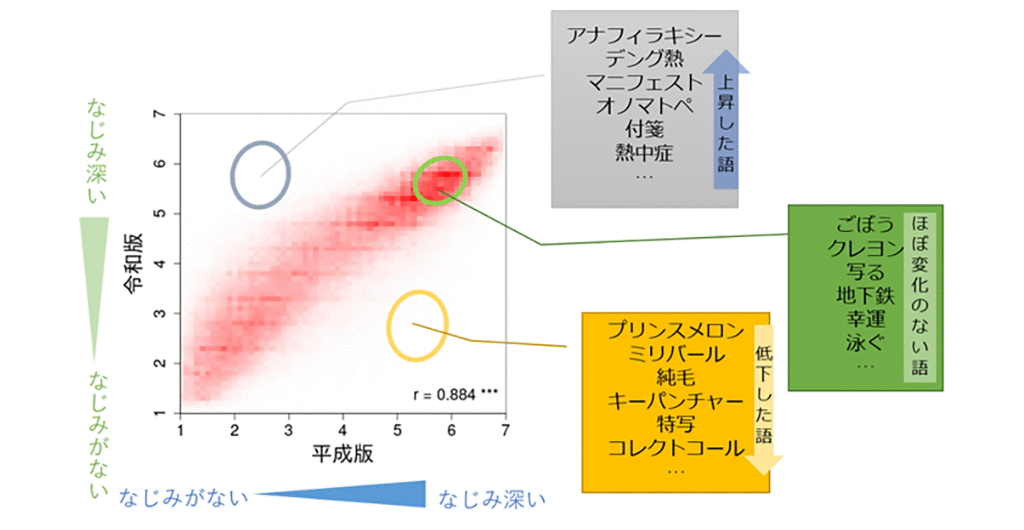
単語親密度の調査を16万3千語という過去最大の規模で実施し、令和版単語親密度データベースを構築しました。 さらに、平成版単語親密度からの変化を調査し、両者に強い相関があり、多くの語では20年以上経っても親密度に大きな変化がないことを確認しました。一方で、大きく変化した語も一部存在すること、どういった語が大きく変化したかを明らかにしました(図1)。
図1. 平成版から令和版への単語親密度の変化
(2)学童期からの語彙数を大規模に調査・分析し、令和版語彙数推定テストを作成
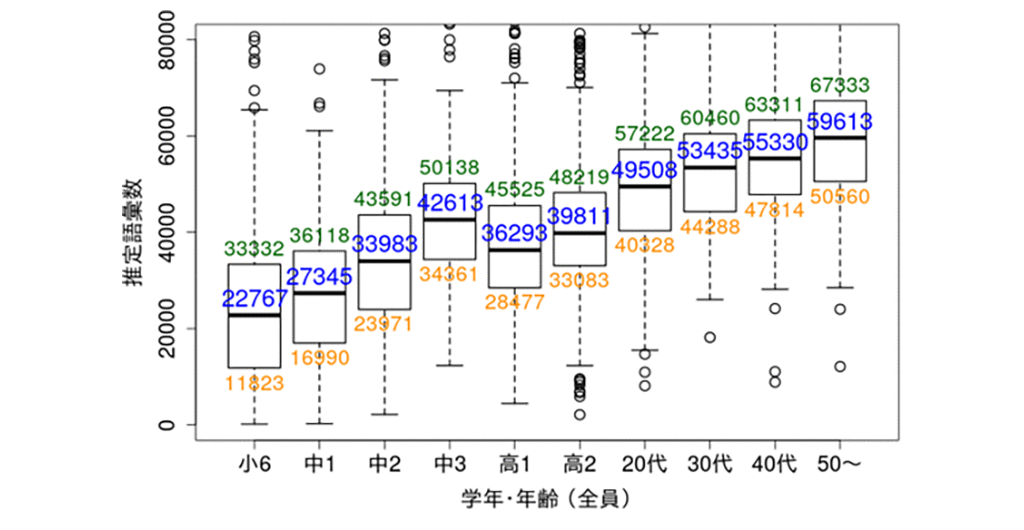
公立の小学生~高校生を含む約4,600人を対象に、語彙数調査を実施しました ※1。まず、平成版単語親密度を基にした語彙数推定テストを作成し、各学年・年齢での語彙数変化を調査しました。その結果、特に、小中学生では急激に語彙数が上昇すること、成人でも、年齢とともに語彙数が上昇することを確認しました(図2)。
図2. 各学年・年齢の語彙数推定結果(語彙数は平成版単語親密度に基づき推定)
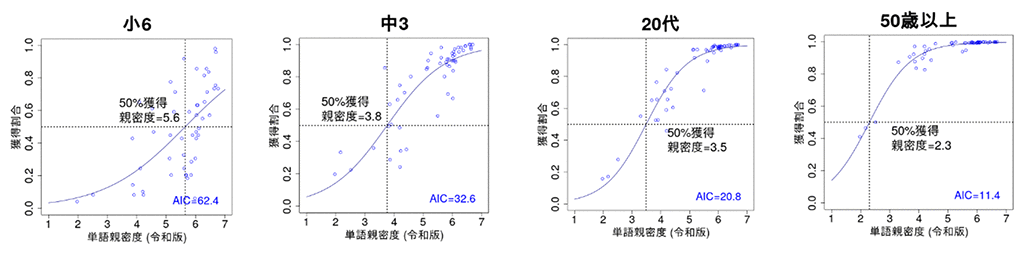
さらに、各学年・年齢において、単語親密度と語彙獲得状況(その語を知っている人の割合)との関係をモデル化しました(図3)。図3は、年齢ごとに、各単語親密度の語に対し、その語を知っていると回答した人の割合(獲得割合)を表します。どの年齢でも親密度が高い語ほど、知っている人の割合は高くなる傾向があり、年齢が上がれば上がるほど、この傾向は顕著になります。一方、成人にくらべて、小学生や中学生では、比較的親密度の高い語であっても、児童・生徒ごとに個人差があり、知っているかどうかにばらつきがあります。こうした分析から、単語親密度を手掛かりとして、児童・生徒がこれから重点的に獲得するだろう語彙、あるいは個人ごとに獲得した方がよい語彙を見つけていくことができると考えています。
さらに、学校教育で重点的に扱われる語を用いてしまうと、児童・生徒の語彙数の推定が影響を受けることを明らかにしました。令和版単語親密度に基づく語彙数推定テストには、こうした分析結果が反映されています。さらに、基盤となる単語親密度データベースの拡充により推定できる語彙数の上限が大きく上昇し、テストの汎用性を高めることができました。
図3. 各学年・年齢における語彙獲得状況と単語親密度(令和版)
3.今後の展開
単語親密度データベースは、実験心理学や教育分野、自然言語処理などの分野における基盤的言語資源として、さらなる活用をめざします。
語彙数調査は、自治体と協力し、学童期からの調査をより広範に進めます。さらに、語彙数と読解力や学力全般との関係の調査・分析を行い、効果的な学習支援の実現をめざします。
学校での調査用とは別に、一般の方に試していただける令和版語彙数推定テストも公開予定です。
また、語彙数推定方法を英語学習にも援用し、語彙数にあった英語の多読支援を進めていきます。
※1本語彙数調査は、一般社団法人教育のための科学研究所との共同研究において実施したものです。
本件に関する報道機関からのお問い合わせ先
■日本電信電話株式会社
先端技術総合研究所 広報担当
science_coretech-pr-ml@hco.ntt.co.jp
TEL: 046-240-5157
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










