

2020年8月24日
日本電信電話株式会社
エッジコンピューティング環境を想定した非同期分散型深層学習の実現 ~大量のデータを多サーバーに分散蓄積したままでも、モデル学習を可能にする技術~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田 純、以下「NTT」)は、エッジコンピューティング(※1)上の機械学習を想定した非同期分散型深層学習技術(Edge-consensus Learning)(※2) を実現しました。
現在の機械学習、特に深層学習では、1か所(クラウド)にデータを集約し、画像/音声認識等のモデルを学習することが一般的です。しかし、あらゆるモノがネットワークに接続するIoT時代において、膨大なデータをクラウドに集約することは困難です。また、プライバシー保護の観点で、データをローカルにあるサーバー/機器にとどめたいという需要も増加しています。関連して、EUの一般データ保護規則(GDPR)(※3)のようなプライバシー保護のための法的規則も強化されつつあります。こうした時代において、データを蓄積・分析・処理するサーバーを分散化し、上位システム(クラウド)や通信網の処理負荷を低減させ、応答速度やプライバシー保護の観点でユーザーの利便性を高めるエッジコンピューティングへの期待が高まっています。
本研究の目的は、エッジコンピューティングのように分散配置されたサーバー群に分散してデータが蓄積されていく環境でも、あたかも一か所にデータを集約して学習したかのようなグローバルモデル(※4)を得るための学習アルゴリズムを開発することです。今回開発した技術は、(1)統計的に非均一なデータがサーバー群に蓄積されていて、 かつ(2)サーバー群がモデルに関連する変数を非同期に通信/交換していても、全部のデータを1か所に集めて学習したのと同等のモデルを得られることを確認したという点で、学術性/実用性が共に高い学習アルゴリズムだと言えます。
本成果は、8/23から開催されるアメリカ計算機学会(ACM)主催の国際会議KDD 2020(Knowledge Discovery and Data Mining、採択率16.9%)にて発表予定です。また、本成果についての多角的な検証を目的に、関連したコードをGithubにて公開予定です。
1.研究の背景
現在の機械学習、特に深層学習では、1か所にデータを集約し、1か所でモデルを学習するのが一般的です。しかし、データ量の激増やプライバシー保護の観点から、近い将来データは分散蓄積されるようになります。例えば、エッジコンピューティング構想では、データ蓄積や処理の負荷分散が提唱されていますし、EUのデータ保護法的規制GDPRでは、国を跨ぐデータの移送に制限をかけていたり、最小限のデータ収集を要請する条項も存在します(図1)。
 図1 エッジコンピューティング環境で想定されるアプリケーション例と分散データ蓄積
図1 エッジコンピューティング環境で想定されるアプリケーション例と分散データ蓄積
このような状況では、データプライバシー保護と機械学習によって得られる恩恵をトレードオフとみなすのではなく、むしろデータプライバシーを保護しつつ機械学習の恩恵を受けられる世界がより望ましいといえます。そのためには、性能を犠牲にすることなくデータ収集やモデルの学習を分散化することが、技術的な課題の一つでした。
2.技術のポイント/特徴
今回開発した学習アルゴリズムは、複数のサーバーに異なるデータが分散して蓄積される状況でも、サーバー間で合意形成されたモデルを得ることができます。データの代わりに、モデルに関連する変数をサーバー間で非同期に通信/交換することで、合意形成されたモデルを得ます。具体的には、図2に示すように、各サーバー内で行う処理(U)とサーバー間で変数を交換する(X)の2つを交互に繰り返す学習アルゴリズムになっています。
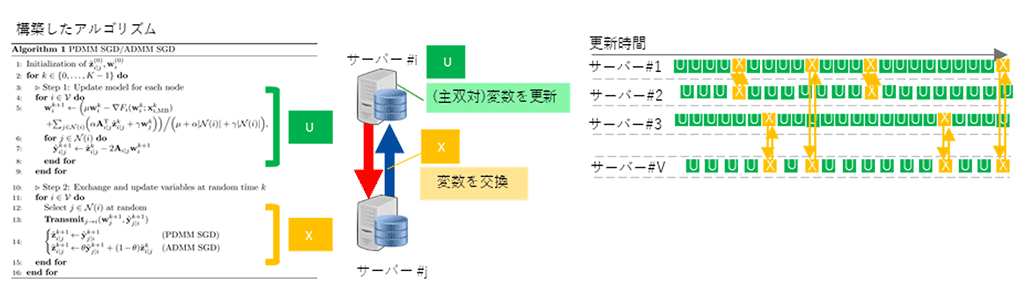 図2 開発した非同期分散型の学習アルゴリズム(Edge-consensus Learning)
図2 開発した非同期分散型の学習アルゴリズム(Edge-consensus Learning)
このアルゴリズムの有効性を検証するために行ったシミュレーション実験の結果を、以下で簡単にご紹介します(図3)。8台のサーバーがリング状に接続されたネットワークを想定します。テスト用の画像データセットとして、一般的に用いられる物体画像認識用のデータセット(CIFAR-10)を用いました。これは、計10個のクラス(航空機、自動車、鳥、猫など)に分類可能な大量の画像で構成されています。一方本実験では、各サーバー上に統計的に非均一となるように画像を与えます。具体的には、各サーバーにはそれぞれ10クラスのうち、ある5クラス分のデータのみを与えます(ただし、8台合わせると全てのクラスがほぼ均等に存在するデータセットとなります)。サーバー群が非同期に通信する状況をシミュレートした結果、提案法を用いると、あたかも一か所にデータを集約して学習したかのようなモデル(グローバルモデル)が得られることを確認しました。
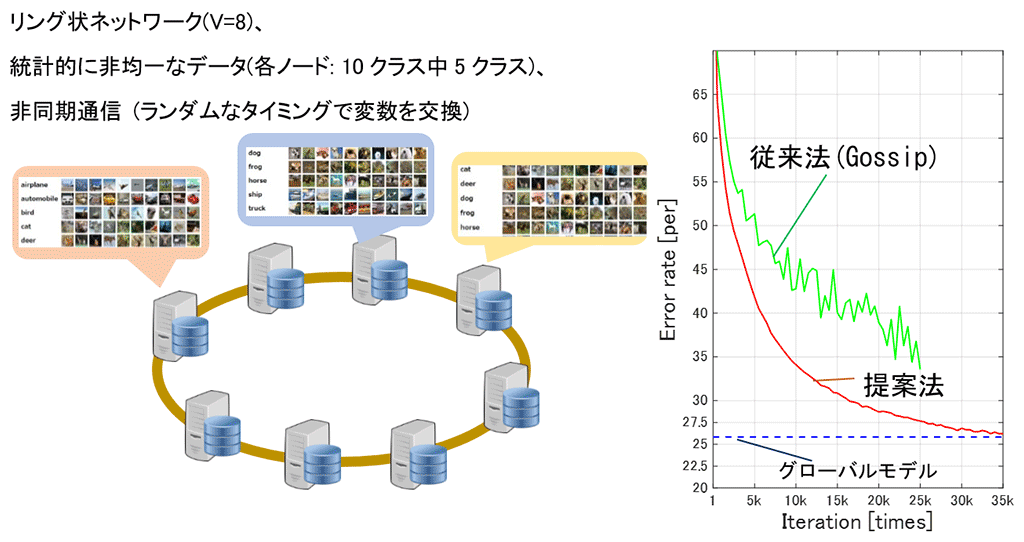 図3 実験結果(抜粋)
図3 実験結果(抜粋)
図3解説
一か所にすべてのデータを集約して一か所で学習した結果(青)と性能が一致するモデルを得られるのかを検証するための実験。従来法(緑)を用いた場合は学習が不安定となるが、提案法を用いた場合は安定して学習が進み、グローバルモデルに極めて近いモデルが得られる。
3.今後の展開
エッジコンピューティングを活用した大規模なAI応用が期待される分野での実用化をめざして、パートナーと連携しながら研究開発や実証実験を今後も継続していきます。コード公開を通じて、本技術の更なる発展、アプリケーションに関するコラボレーションを促進していきます。
用語解説
※1エッジコンピューティング:
利用者や端末と物理的に近い場所に処理装置を分散配置して、ネットワークの端点でデータ処理を行う技術の総称。多くのデバイスが接続されるIoT時代となり提唱されるようになりました。
※2非同期分散型深層学習技術:
データが多数のサーバーに分散して蓄積されている環境で、かつサーバー間が非同期に通信する状況において、深層学習モデルを得るためのアルゴリズム
※3一般データ保護規則(GDPR):
EU一般データ保護規則とは、欧州議会・欧州理事会および欧州委員会が欧州連合内の全ての個人のためにデータ保護を強化し統合することを意図している規則です。欧州連合域外への個人情報の輸出も対象としています。
※4グローバルモデル:
ここでは、一か所にすべてのデータを集約して一か所で学習したときに出来上がるモデルのことを指しています。
発表・公開について
本成果は8月23日(米国時間)からオンライン開催されるACM主催の国際会議、KDD2020にて、下記のタイトル・著者で発表されます。
Title: Edge-consensus Learning: Deep Learning on P2P Networks with Nonhomogeneous Data Authors: Kenta Niwa (NTT), Noboru Harada (NTT), Guoqiang Zhang (University Technology of Sydney), Bastiaan Kleijn (Victoria University of Wellington)
また、本成果に関連したコードを以下のサイトで公開します。
https://github.com/nttcslab/edge-consensus-learning本件に関する報道機関からのお問い合わせ先
日本電信電話株式会社
先端技術総合研究所 広報担当
TEL 046-240-5157
E-mail science_coretech-pr-ml@hco.ntt.co.jp
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










