

2021年6月 1日
日本電信電話株式会社
因果関係に基づく公平・高精度な機械学習予測を実現
~どんな予測が差別的かを指定しながら、人を対象とした効果的な予測が可能に~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田純、以下 NTT)は、因果関係に基づく公平・高精度な機械学習技術を実現しました。
融資承認や人材採用など、人を対象とした意思決定を機械学習予測によって行う場合、単純に予測精度のみを優先する機械学習技術を適用すると、性別・人種・障がいなど、人間が持つセンシティブな特徴に関して不公平な予測を行う機械学習モデルになってしまう可能性があります。一方で、どのような予測が不公平かということは個々の応用によって異なり、例えば「体力を要する職種における人材採用なので、体力の不足を理由とした不採用は不公平でない」とする場合も考えられ、このような不公平さに関する事前知識を活用しなければ、体力が不足した人材を採用し、予測精度が下がってしまうことがあります。
本技術では、不公平さに関する事前知識を、特徴・予測結果間の因果関係を表す因果グラフ(※1)として表現し、これを活用することで公平かつ高精度な機械学習予測を行う技術を実現しました。また従来法ではデータが特定のモデルから生じている場合でなければ公平性を保証できないのに対して、提案手法では様々なデータを用いて、公平な予測を行うことができることを確認しました。
1.背景
近年のAI・機械学習技術の目覚ましい発展に伴い、銀行における融資承認・企業における人材採用・児童に対する虐待の検知など、人生に重大な影響を与える意思決定を機械学習予測によって行い、人的コストの低減や意思決定の効率化・高速化を目指す事例が増えつつあります。
このような人を対象とした予測において、単純に予測精度のみを優先する機械学習技術を適用すると、性別・人種・障がいなど、人間が持つセンシティブな特徴に関して不公平な予測を行う機械学習モデルになってしまう可能性があります。
一方で、どのような予測が不公平であるかということは、個々の応用事例において求められる要請によって異なることが多く、例えば「体力を要する職種における人材採用なので、体力の不足を理由とした不採用は不公平ではないと考えたい」というような要請も考えられます。このような要請を考慮しない従来技術を用いると、体力の不足した応募者を多く採用してしまい、効果的な意思決定を行うことができないという問題がありました。
このような問題を解決するために、公平性に関する社会的要請を、特徴・予測結果間の因果関係を表す因果グラフとして表現することで、予測精度を向上させる機械学習技術がいくつか提案されましたが、これらの従来技術は単純な関数形で表現できるようなデータを用いた場合にしか、予測の公平性を保証できないという問題がありました。
2.研究の成果
NTTコミュニケーション科学基礎研究所は、人が持つ特徴と予測結果の間の因果関係に基づいて公平・高精度な予測を行える機械学習技術を開発しました。本技術を実現するにあたり、まずは予測の不公平さの度合いを数値化することが必要でした。公平さは、どのような社会的状況でも同じように判断されるわけではありません。例えば、体力を要する職種における人材採用を考えるときに、体力の不足を理由として不採用にすることは不公平ではなく、むしろ、職務遂行に必要な体力のある応募者のみ採用したい、と採用する側は考えるでしょう。このように、不公平さは、それぞれの社会的状況がもたらす条件や考え方(社会的要請)に基づいて決まります。今回の成果では、このような社会的要請に基づいて予測の不公平さの度合いを数値的に測定するための尺度を新たに考案しました。この予測の不公平さについての尺度は、複雑なデータに対しても適用可能であるように構成しました。従来技術では、データが複雑になると予測の公平さを保証することができませんでしたが、今回、この尺度を導入することによって、複雑なデータに対しても、予測結果がその問題に対する社会的要請に沿って公平になるように制約を課しながら、機械に学習をさせることが可能になりました。結果として、様々に異なる状況での社会的要請に柔軟に対応でき、既存技術では複雑すぎて適用が難しかったデータも含め、公平かつ高精度な機械学習モデルを構築できるようになりました。さらに、本技術を用いることで、従来技術では公平性を保証できなかったデータにおいて公平性を保証し、かつ高精度な予測を行うことを、シミュレーション実験により確認しました。
3.技術のポイント
(1)人を対象に公平な予測を行う機械学習モデルの構築
本技術は、人を対象とした意思決定に関する過去の履歴(訓練データ)と、矢印(因果グラフ)によって「どんな予測が不公平か」に関する事前知識を表現したものを入力として受け取り、公平な予測を行う機械学習モデルを出力します(図1)。ここで、訓練データは各個人の特徴と、その個人に対する意思決定の結果から成り、各個人の特徴は性別・人種・障がいなどのセンシティブな特徴を含みます。また、因果グラフは、特徴と予測結果の間の因果関係を矢印によって表したものです。この矢印の有無や方向については、データに関する専門知識によって判断する、あるいは既存技術を用いてデータから推定する、などによって、予め用意されることを本技術では想定しています。
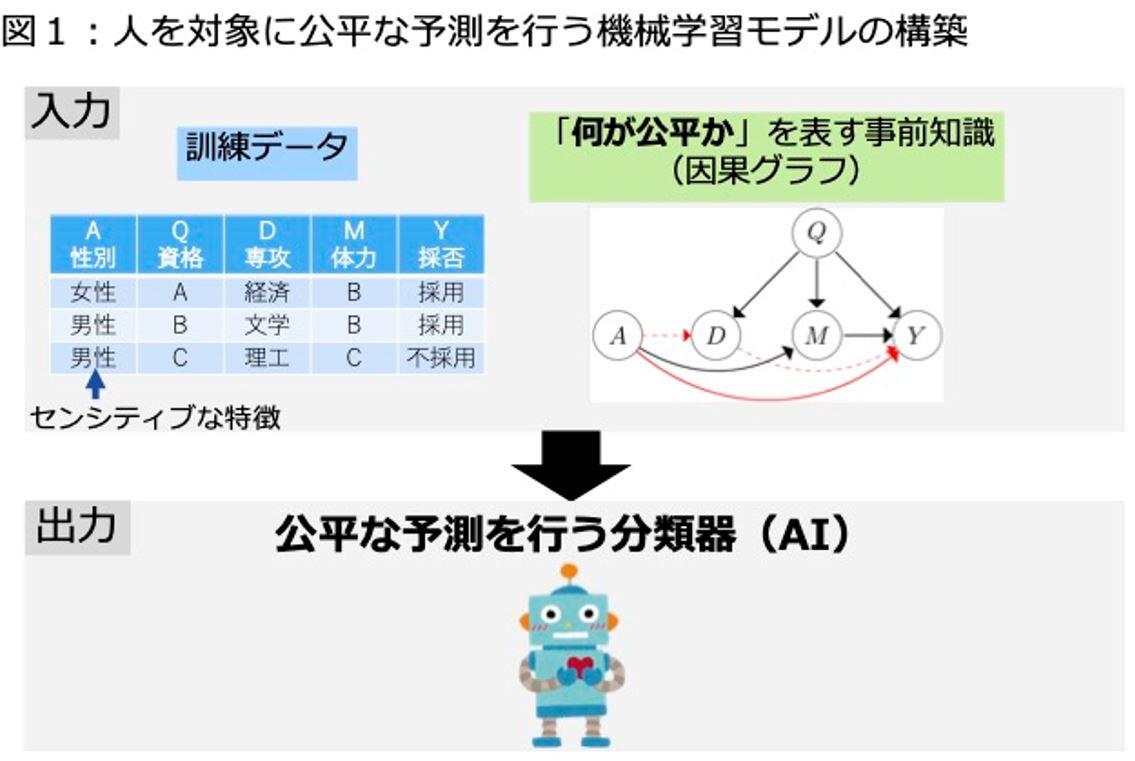
(2)因果グラフを用いて、どのような予測が不公平かを指定
本技術では、因果グラフを用いてどのような予測が不公平であるかを指定することで、公平性に関する様々な要請を因果グラフで柔軟に表現することが可能です。例として、体力を要する職種における人材採用を考えます(図2)。 この場合、(1)性別によって採否を決定するのは性別に関して不公平な決定であり、(2)性別と相関のある出身専攻によって採否を決定し、その結果採用率に性差が生じるのも不公平です。しかし、(3)体力を要する職種なので、体力によって採否を決定し、その結果採用率に性差が生じるのは不公平でない、ということが考えられます。このような公平性に関する要請を表現するために、因果グラフ中の性別から予測結果に至る矢印(図2中のA→Y)と性別から出身専攻を経由して予測結果に至る矢印(図2中のA→D→Y)を不公平な経路として指定します。これにより、(1), (2)によって生じる採用率の性差には制約を課す必要があるが、(3)によって生じる採用率の性差には制約を課す必要がないことを表現でき、後者のような不要な制約を課して予測精度が低下する問題を防ぐことができます。

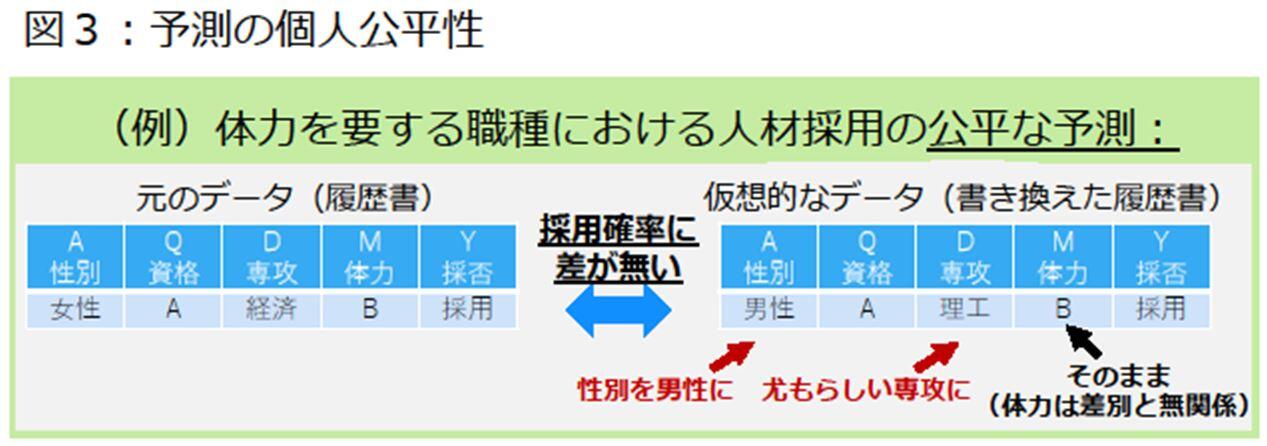
(3)各個人に対して公平性を保証
本技術は、個々の公平性に関する要請に則して、各個人に対する予測の公平性を保証することができます。ここで、各個人にとって予測が公平であるとは、例えば上述の体力を要する職種における人材採用の場合、ある個人に関する履歴書に対し、その性別と出身専攻を書き換えた履歴書を考えても、予測した採用確率に差が無いことを意味します(図3)。このような履歴書の書き換えには、例えば性別を女性から男性に変えた場合に、その男性が選ぶであろう尤もらしい専攻を求める必要があり、そのためには正しい履歴書の書き換え方法(データの真の生成式)が必要になります。しかしながら、履歴書の書き換え方法を正しく得るには、その書き換え方法が単純な関数形で表せる必要があり、それゆえ従来技術では特定のデータでしか、各個人に対して公平性を保証することができませんでした。一方で、本技術ではあらゆるデータから、各個人に対して公平な予測を行う機械学習モデルを構築することができます。
(4)提案技術のポイント
本成果では、どんなデータを用いた場合でも予測の不公平性を測ることが可能な尺度を考案しました。この尺度は、例えば上述の体力を要する職種における人材採用において、元の履歴書を入力した場合と書き換えた履歴書を入力した場合との間で採否結果とが異なる確率値を、あらゆる履歴書の書き換え方法(データの生成式)のもとで考えるとき、最大でどの程度の値になるかを表す尺度です。本技術は、この不公平性尺度の値がゼロに近くなるように制約を課しながら学習することで、どんなデータを用いた場合でも、各個人にとって公平でかつ高精度な予測を行う機械学習モデルを構築することが可能です。
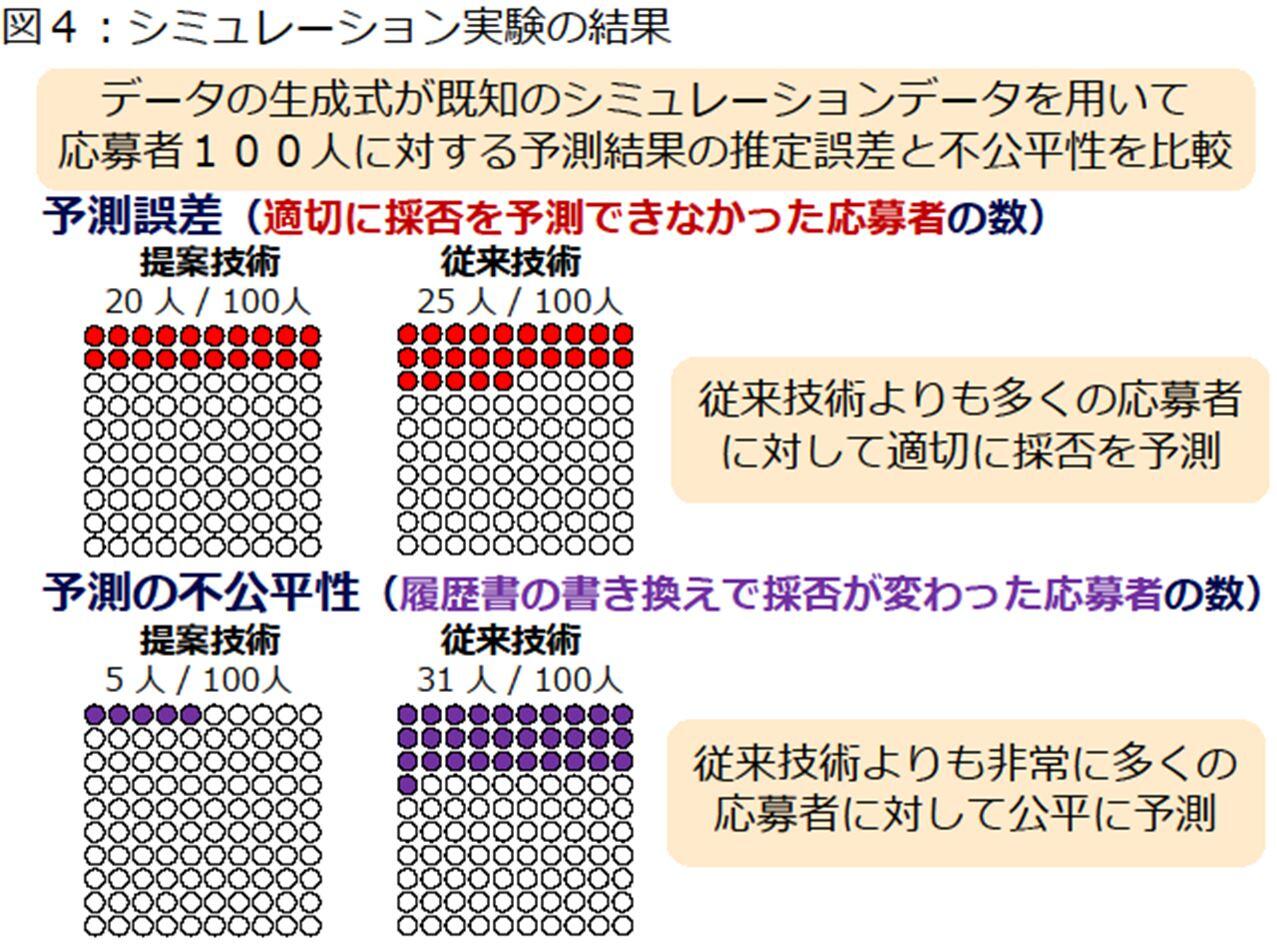
(5)シミュレーション実験
シミュレーションデータを用いて、本技術と従来技術の比較実験を行いました(図4)。本実験では、体力を要する職種における人材採用を想定したシミュレーションを行って得た応募者100人に対し、適切に採否を予測できなかった人数(予測誤差)と、履歴書の書き換えによって採否の予測結果が変わった人数(予測の不公平性)を評価しました。その結果、従来技術と比べて、高精度でかつ遥かに公平な予測を行なっていることを確認しました。具体的には、適切に採否を予測できなかった人数は、従来技術で100人中25人であったのに対し、本技術では20人となり、より適切な予測を行っていることがわかりました。また、履歴書の書き換えによって採否の予測結果が変わった人数は、従来技術で100人中31人であったのに対し、本技術では5人となり、予測の公平性が飛躍的に向上していることを確認しました。公平性の面で飛躍的な性能向上が見られたのは、従来技術とは異なり、本技術が履歴書の書き換え方法が複雑な関数形で表されるデータを用いた場合でも、各個人にとって公平な予測を行う機械学習モデルを構築できることを示唆しています。
4.研究協力の状況・関連文献
本成果は、京都大学大学院情報学研究科鹿島教授との共同研究の成果であり、統計的機械学習分野の難関国際会議AISTATS2021(Artificial Intelligence and Statistics、採択率29.8%)にて発表されたものです。その技術的詳細は、以下の文献に述べられています。
Yoichi Chikahara, Shinsaku Sakaue, Akinori Fujino, Hisashi Kashima, "Learning Individually Fair Classifier with Path-Specific Causal-Effect Constraint," in
Proc. of the 24-th International Conference on Artificial Intelligence and Statistics (AISTATS), 2021.
5.今後の展開
今回実現した技術について、今後、回帰や教師なし学習など、他の機械学習の問題への拡張を進め、より多様な場面における人を対象とした予測を実現するための技術の確立と、応用の検討を進めます。
【用語解説】
(※1)因果グラフ
確率変数間の因果関係を矢印で表した図。本研究では、人が持つそれぞれの特徴と、人に対する予測結果を確率変数とみなし、その間の因果関係を表す図を考えている。
本件に関する問い合わせ先
日本電信電話株式会社
先端技術総合研究所 広報担当
℡ 046-240-5157
Email science_coretech-pr-ml@hco.ntt.co.jp
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










