

2021年6月25日
日本電信電話株式会社
世界初、一般的な写真群から未知の奥行きとボケ効果の学習を実現
~限られたデータから三次元世界の理解が可能なAIの実現に向けて前進~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田 純、以下「NTT」)は、一般的な写真群から、未知の三次元情報(奥行きおよびボケ効果)を学習可能な新たな深層学習技術(※1)を実現しました。
一般に写真撮影は三次元世界を、二次元画像として記録・保存します。私たち人間は、このような二次元画像に対して、これまでの経験および知見に基づき、対応する三次元情報を比較的容易に推定することができます。しかし、コンピュータにはそのような経験や知見がないため、二次元画像のみから三次元情報を理解することは容易ではありませんでした。
これに対して、本成果では、カメラの絞りにおける光学的な制約を考慮した深層学習モデルを新たに構築することで、インターネット上に公開されている画像のような一般的な写真群のみから、奥行きやボケ効果といった三次元情報を学習することを可能にしました。
一般に三次元情報を取得するには、専用の機器が必要であったり、あるいは、データ取得環境に制約があったりするため、応用上の障壁となっていました。一方、本技術では、学習に必要なデータは二次元画像のみであり、奥行き情報やボケ情報などの三次元情報をあらかじめ取得し、学習時に付加情報として与える必要がありません。したがって本技術は、データ取得に関わる応用上の障壁を低減するブレークスルーとなることが期待されます。
本成果は、2021年6月19日~25日(米国東部標準時間)にオンライン形式にて開催されている、コンピュータビジョン分野のトップカンファレンスCVPR 2021(Conference on Computer Vision and Pattern Recognition)でOral採択(採択率は全投稿の約4%)されています。
1.背景
私たちは、三次元世界で生活をしています。しかし三次元情報を直接記録または表示することは容易ではないため、記録および伝達媒体としては二次元画像が広く用いられています。私たち人間は、日々の生活を通して得た経験や知見により、媒体が二次元画像であったとしても、それに対応する三次元情報(奥行きやボケ効果など)を比較的容易に推定することができます。しかし、一般的なコンピュータ(特に、ここでは深層学習モデルを想定)には、そのような経験や知見がないため、二次元画像のみから三次元情報を理解することは簡単ではありません。
一方で、近年のAI技術の急速な発展により、コンピュータはより身近な存在となり、人間の行動の補助または代替する役割を果たすことへの期待が高まっています。このような状況を考えると、コンピュータに私たち人間が住む三次元世界を理解させることは、一つの大きな課題であると言えます。一般に、深層学習モデルは、入力と出力の正解データが明確に与えられていれば比較的容易に学習ができます。二次元画像から三次元情報を理解させる課題でも、二次元画像と三次元情報のペアデータを大量に集めることができれば、その対応関係を学習することは比較的容易です。しかし、三次元情報を取得するには、深度センサーやステレオカメラなどの専用の機器が必要であったり、あるいは、データ取得環境に制約があったりするため、応用上の障壁となっていました。
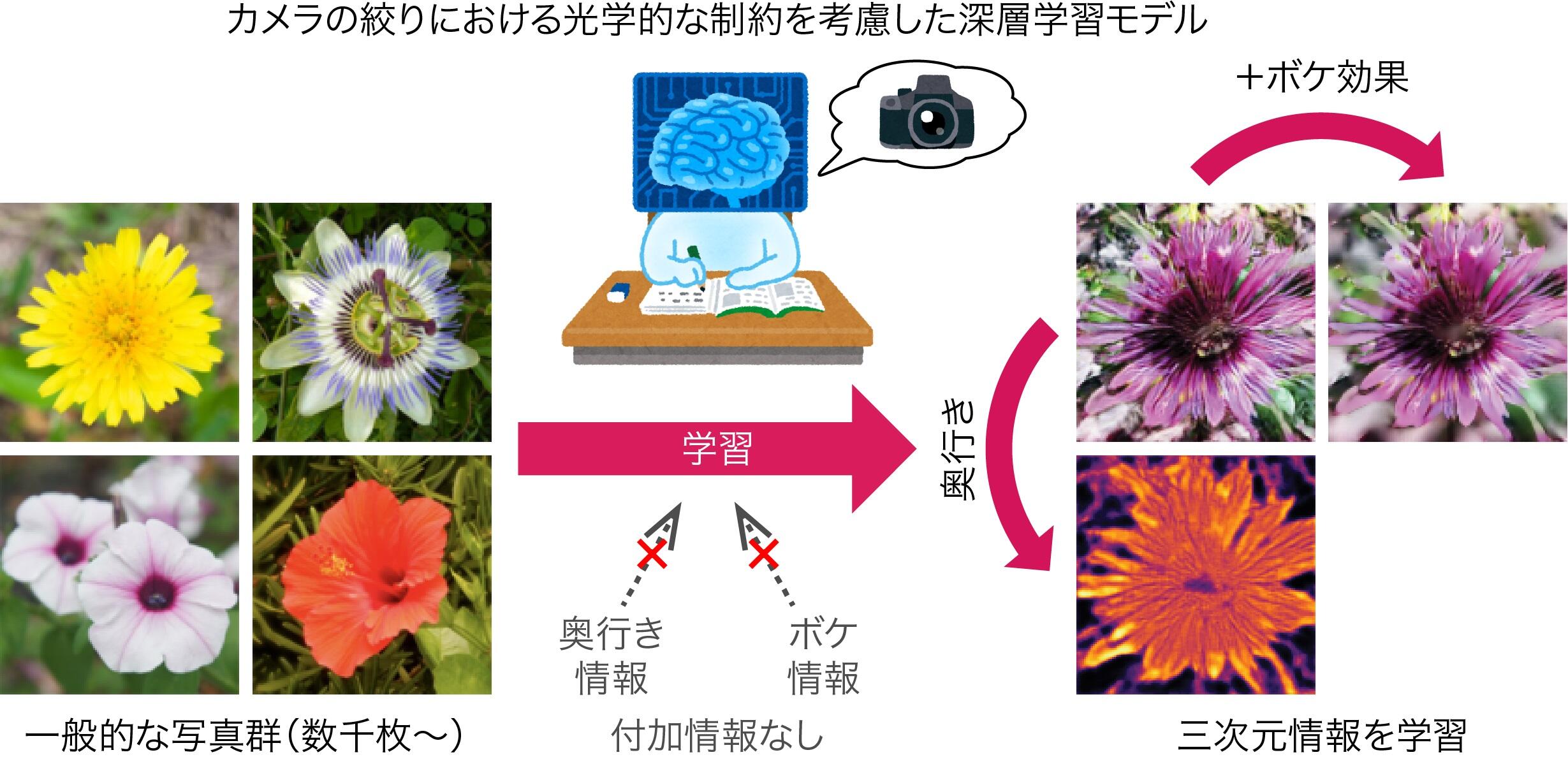 図1:付加情報のない一般的な写真群から三次元情報を学習。カメラの絞りにおける光学的な制約を考慮した深層学習モデルを新たに構築することで、二次元画像集合のみから、奥行き情報やボケ効果といった三次元情報を学習することを実現。
図1:付加情報のない一般的な写真群から三次元情報を学習。カメラの絞りにおける光学的な制約を考慮した深層学習モデルを新たに構築することで、二次元画像集合のみから、奥行き情報やボケ効果といった三次元情報を学習することを実現。
2.研究の成果
本研究では、上記課題を克服するため、入手が比較的容易な二次元画像のみから、三次元情報を理解できるコンピュータの実現を目的としました。上述したように、一般的なコンピュータは、三次元世界に関する経験や知見を持たないため、二次元画像のみから三次元情報を理解することは容易ではありません。その解決のため、本研究では、コンピュータに三次元情報を理解させるための手がかりを与えることを考えました。
特に、本研究で着目したのは、一般的なカメラで撮影した画像であれば、画像内に自然に存在しているボケ効果です。このボケ効果は、被写体が被写界深度(写真のピントが合っているように見える被写体側の距離の範囲)から外れることによって生じる現象で、そのボケ具合は、カメラの絞りを調整することによって変えることができます。具体的には、カメラの絞りを開くと、カメラに入る光の量が多くなるため、被写界深度は浅くなり(ピントの合う領域は狭くなり)、ボケ効果(被写界深度効果)は大きくなります。一方で、カメラの絞りを狭めると、カメラに入る光の量は少なくなるため、被写界深度は深くなり(ピントの合う領域は広くなり)、ボケ効果は小さくなります。このように、カメラの絞りは、被写体の三次元的な位置関係(具体的には、カメラからの距離、つまり、奥行き)をボケ効果として画像に反映する際に重要な働きをします。
この考え方に基づき、本研究では、カメラの絞りにおける光学的な制約を考慮した深層学習モデルを新たに構築し、画像、奥行き情報、ボケ効果の三者について関連付けながら学習することを可能にしました。これにより、図1に示すように学習時には付加情報のない一般的な写真群しか用いないにもかかわらず、その写真を再現するようなモデルを学習する過程で、シーンの奥行き構造や、写真に含まれるボケ効果といった三次元情報についても間接的に学習させることができます。
このように、付加情報の一切ない二次元画像集合のみから、奥行き情報やボケ効果といった三次元情報を学習することに成功したのは世界初の成果です。従来技術では専用機器を用いて三次元情報を収集する必要があるため、データ収集コストが高いのに対し、インターネット上の公開画像のような一般的な写真群だけから学習できることは本技術の大きな強みです。コンピュータによる三次元世界の理解を一歩前進させるとともに、実用面でもデータ収集コストを大幅に削減できる画期的な技術と言えます。
3.技術のポイント
本技術は、敵対的生成ネットワーク(Generative Adversarial Network、GAN)(※2)と呼ばれる深層学習ベースの生成モデルの一種に基づいた技術です。GANは、乱数から画像を生成する生成器と、与えられた画像が生成画像(偽物の画像)か実画像(本物の画像)かを識別する識別器の二つの深層ニューラルネットワーク(Deep Neural Network、DNN)から構成されています。生成器は、なるべく識別器を騙せるような画像を生成するように学習を行い、一方、識別器は、なるべく生成器に騙されないように学習を行います。このように、生成器と識別器の二つのDNNが互いに競合する条件下で学習を行うことで、最終的に、生成器は、実画像と区別できないような精緻な画像を生成できるようになります。
このGANの強みは、学習データを再現できる生成器を学習する過程で、与えられたデータを構成的に理解することが可能となる点です。本技術では、この性質を、二次元画像に内在する奥行き情報やボケ効果を学習する際に活用しました。より具体的には、本研究では、Aperture Rendering GAN(AR-GAN)と呼ぶカメラの絞りにおける光学的な制約を考慮したGAN を考案しました。AR-GANの生成器における処理の流れを図2に示します。このAR-GANでは、乱数からまずボケのない画像と奥行き情報のペアデータを生成します。このペアデータをもとに、絞りに入る光線の集合(光線場)をシミュレーションします。そして、最後に、絞りを模擬した円型のマスク(値が0の場合は光線を通さず、それ以外の場合は光線を通す)を用いて光線場を集約することで、ボケのある画像を合成します。
学習時には、上述したGANのフレームワーク(つまり、生成器はなるべく識別器を騙せるような画像を生成できるように学習を行い、一方、識別器は、なるべく生成器に騙されないように学習を行う)に基づき、ボケ具合の異なる二種の画像(ボケのない画像とボケのある画像)の両者が実画像として妥当となるように学習を行います。これによって、二種の画像の差分に該当するボケについても自然な効果を学習することができます。さらに、二種の画像を実画像として最適化する過程で、両者を結びつける働きを持つ奥行き情報についても間接的に学習することが可能です。
このように、AR-GANでは、カメラの絞りにおける光学的な制約を取り入れることによって、画像、奥行き情報と、ボケ効果の三つを関連づけさせながら学習を行うことができます。そして、観測可能な画像について直接最適化するのに加えて、その背後にある奥行きおよびボケ効果についても間接的に最適化することができます。
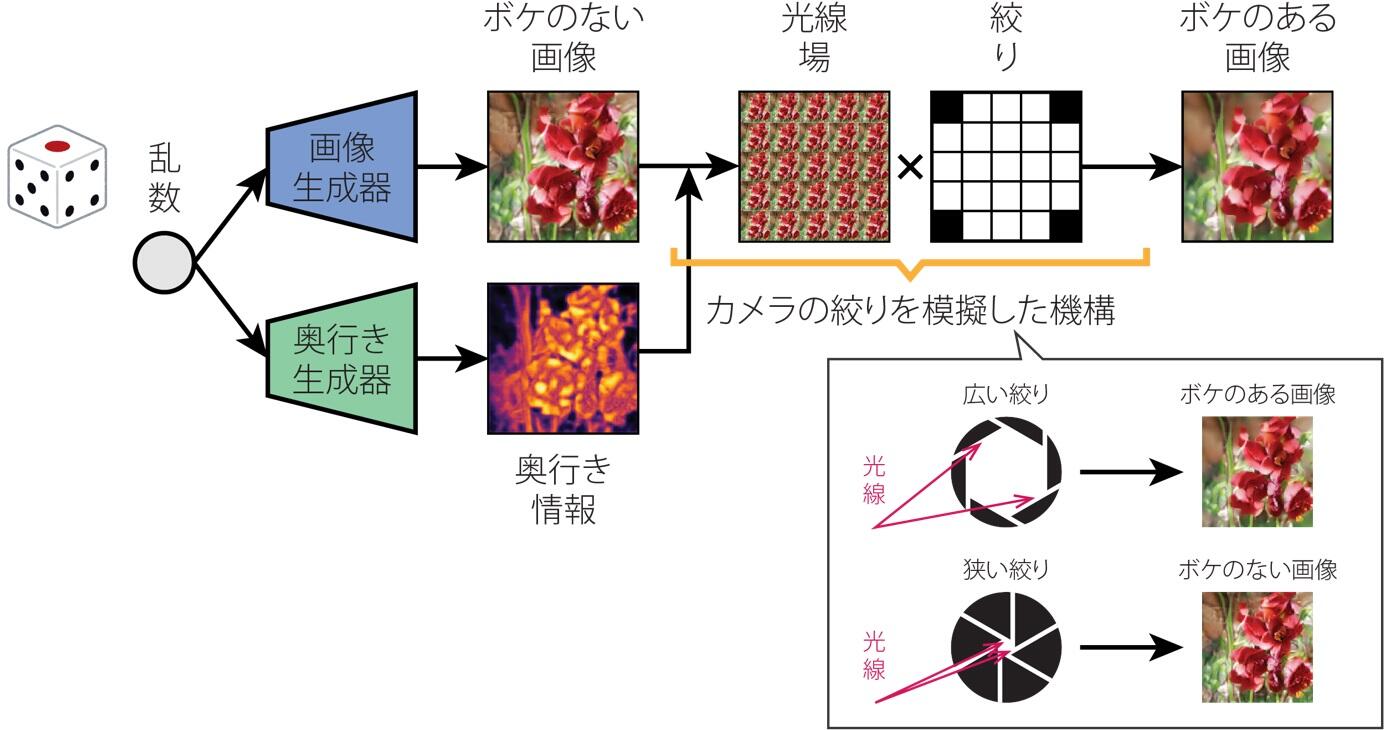 図2:考案したAR-GANの生成器における処理の流れ。AR-GANでは、カメラの絞りにおける光学的な制約を考慮しながら、GANのフレームワークの中で、生成器の学習を行う。これにより、ボケのない画像、奥行き情報、ボケのある画像のセットを生成可能な生成器の学習が可能。
図2:考案したAR-GANの生成器における処理の流れ。AR-GANでは、カメラの絞りにおける光学的な制約を考慮しながら、GANのフレームワークの中で、生成器の学習を行う。これにより、ボケのない画像、奥行き情報、ボケのある画像のセットを生成可能な生成器の学習が可能。
このAR-GANの強みは、ボケ効果という、一般的なカメラで撮影された二次元画像であれば画像内に自然と存在する性質を利用している点です。この柔軟性によって、画像のボケ度合いに関してある程度の多様性をもたせながら、二次元画像を収集することできれば、様々な種類のデータに適用できる可能性があります。実画像を用いてAR-GANを学習した結果の例を図3に示します。こちらの図に示したように、AR-GANは花画像、鳥画像、顔画像と、全く異なる種類のデータに対しても同様の枠組みを用いて学習することが可能です。
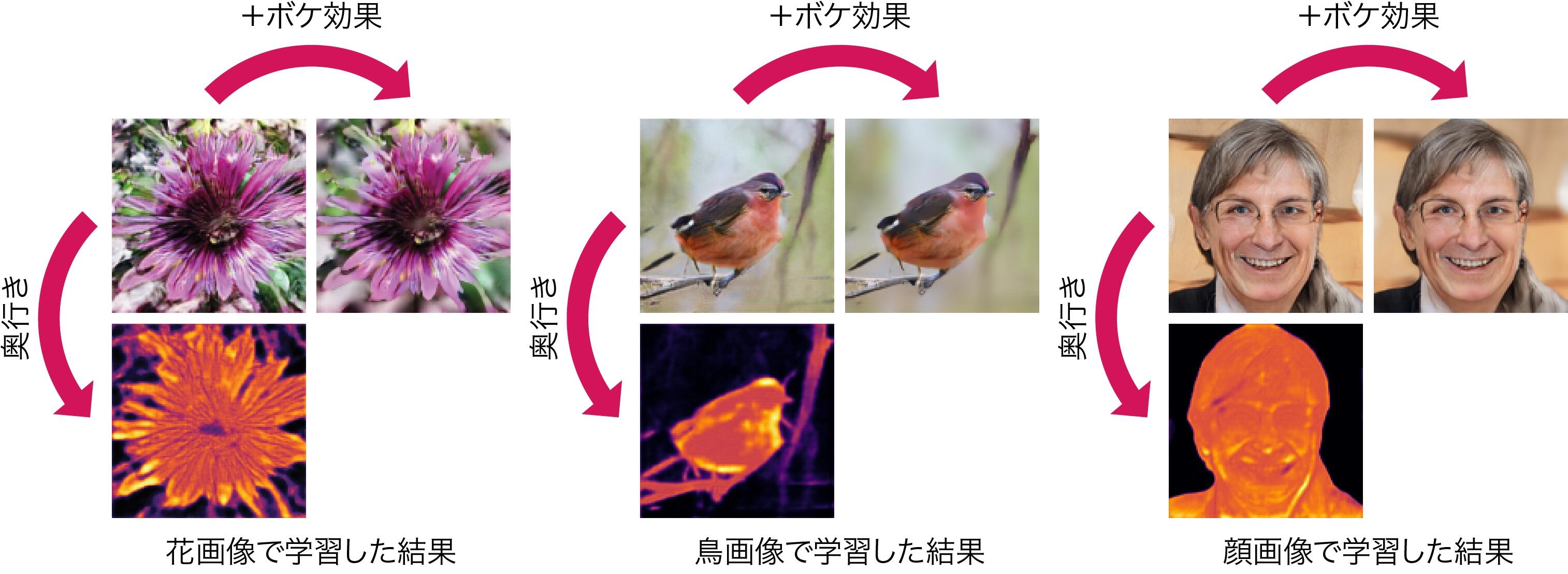 図3:考案したAR-GANを花画像、鳥画像、顔画像を用いて学習した結果の例。画像のボケ度合いに関してある程度の多様性をもたせながら、二次元画像を収集することできれば、様々な種類のデータに適用することが可能。
図3:考案したAR-GANを花画像、鳥画像、顔画像を用いて学習した結果の例。画像のボケ度合いに関してある程度の多様性をもたせながら、二次元画像を収集することできれば、様々な種類のデータに適用することが可能。
4.今後の展開
私たちは三次元世界で生活をしており、人間にとって親和性の高いコンピュータを実現するためには、三次元世界を理解可能なコンピュータを実現することが重要です。しかし、上述のように、三次元情報の収集はデータ収集コストが高いということが応用上の大きな障壁となっていました。これに対して本技術は、二次元画像のみから奥行き情報やボケ効果といった三次元情報を学習可能にするものであり、コンピュータによる三次元世界の理解において、新たな可能性を切り拓く技術であると期待しています。
発表について
本成果は、2021年6月19日~25日(米国東部標準時間)にオンライン形式にて開催されているコンピュータビジョン分野のトップカンファレンスCVPR 2021(Conference on Computer Vision and Pattern Recognition)にて、下記のタイトル・著者で発表されます(Oral採択、採択率は全投稿の約4%)。
Title: Unsupervised Learning of Depth and Depth-of-Field Effect from Natural Images with Aperture Rendering Generative Adversarial Networks
Author: Takuhiro Kaneko (NTT)
用語解説
(※1)深層学習
ニューラルネットワークを多層に結合して表現・学習能力を高めた機械学習の一手法。単純に多層にするだけでは、表現力不足や過学習などの問題があったが、Dropout法やReLUなど、数々の工夫とビッグデータの助けにより解決された。現在、AIを構成するアルゴリズムとして、もっともよく用いられている手法となっている。
(※2)敵対的生成ネットワーク(Generative Adversarial Network、GAN)
生成モデルの一種であり、データから特徴を学習することで、実在しないデータを生成したり、存在するデータの特徴に沿って変換できる。学習対象のデータはあるものの、それが何かという正解は与えられておらず、どうにかして何かしらの構造や法則を見いだすという、いわゆる「教師なし学習」の一つの手法。「敵対的」とあるように、普通のディープラーニングのネットワークと異なり、GANには「生成器」と「識別器」という2つのネットワークで構成される。ジェネレーターは本物と同じような内容を作り出そうとする一方、ディスクリミネイターはレプリカか本物なのかどうかを識別する役割を担っている。レプリカを作る側は本物にできるだけ近づけようと努力し、対して識別する側は確実に見分けられるように、互いに競い合う仕組みとなっている。
本件に関する報道機関からのお問い合わせ先
日本電信電話株式会社
先端技術総合研究所 広報担当
science_coretech-pr-ml@hco.ntt.co.jp
℡ 046-240-5157
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










