

2021年8月17日
日本電信電話株式会社
世界で初めて高精度類似検索の大幅な高速化を検索精度はそのままに実現
~創薬、がん検診など、大規模データの高速かつ精密な分類が可能に~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田 純、以下「NTT」)は、数千個以上のデータであっても1時間以内に格納し、瞬時に類似検索することを可能にするハッシング技術(※1)を実現しました。
通信ネットワークの高度化やデータベース技術の進展により、現在膨大な量のデータが利用可能になっています。問い合わせデータに類似するデータをデータベースの中から効率的に探し出す類似検索は様々なアプリケーションで用いられる重要な技術です。ハッシング技術は事前に0と1のバイナリで表現したデータのハッシュ値をデータベースに格納することで、効率的な類似検索を近似的に実現するもので、現在まで様々なハッシング技術が提案されています。その中でもアンカーグラフハッシング(※2)は高い近似性能と検索実行時の高速性と省メモリ性で優れた技術として知られています。しかし、ハッシュ値の計算に必要な計算コストが高いため、予めデータをデータベースに格納する際に長い処理時間がかかるという問題がありました。
そこで本成果では事前のハッシュ値計算を高速化し、大規模なデータをデータベースに高速に格納できるようにしました。一般的にハッシュ値計算を高速化すると検索結果が劣化するというトレードオフが問題となりますが、本成果は検索結果を犠牲にすることなく高速にデータの格納を可能にするという利点があります。アンカーグラフハッシングは創薬やがん検診などの様々なアプリケーションで利用されており、本成果はこれらのアプリケーションを数千万個規模のデータに対しても実行可能にするブレークスルーとなることが期待されます。
本成果は中央ヨーロッパ時間の 8/16 から開催されているデータベース分野のトップ会議 VLDB 2021 (The 47-th International Conference on Very Large Data Bases) にて口頭発表予定です。
1.背景
通信環境やコンピュータ、分散処理基盤技術の高度化により膨大なデータが現在利用可能になっています。膨大なデータを利用することによりアプリケーションの高品質化が可能になる一方、その膨大さのために、データへの素早いアクセスや、内容を一覧して素早く把握することなどが困難になりつつあり、深刻な問題となっています。類似検索はデータベースに格納されたデータから問い合わせデータに類似するものを探す、というコンピュータ科学において重要な技術の一つです。類似検索としては R-tree など木構造を用いた技術がありますが、データベースに格納されているデータの数が多くなるほど検索時間を要するため、膨大な量のデータを対象としたときには検索時間が非常に長くなってしまうという問題があります。一方ハッシング技術ではデータを一定の長さのビット列として表現するので、データベースに格納されているデータの数によらず一定の検索時間で近似的に類似データを発見できるという利点があります。現在まで様々なハッシング技術が提案されていますが、その中でもアンカーグラフハッシングは類似検索を高い近似性能で実現するものです。アンカーグラフハッシングは検索対象のデータをアンカーグラフというグラフ構造(※3)に変換してからハッシュ値を計算する技術です(図1)。アンカーグラフは検索結果のデータにつけられたラベルを用いることで、データを高速かつ省メモリに分類できます。そのためアンカーグラフハッシングは創薬やがん検診などのアプリケーションで活用されています(図2)。しかし、この技術にはハッシュ値の計算コストが大きいという問題がありました。そのためデータベースに格納するには長い処理時間が必要であり、アンカーグラフハッシングを膨大な量のデータに適用する妨げとなっていました。
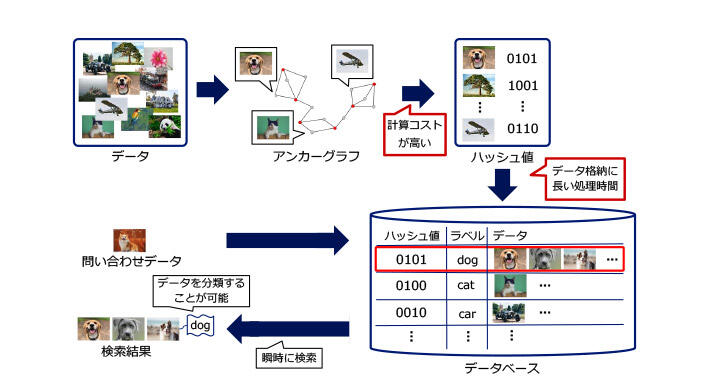 図1:アンカーグラフハッシングの概要
図1:アンカーグラフハッシングの概要
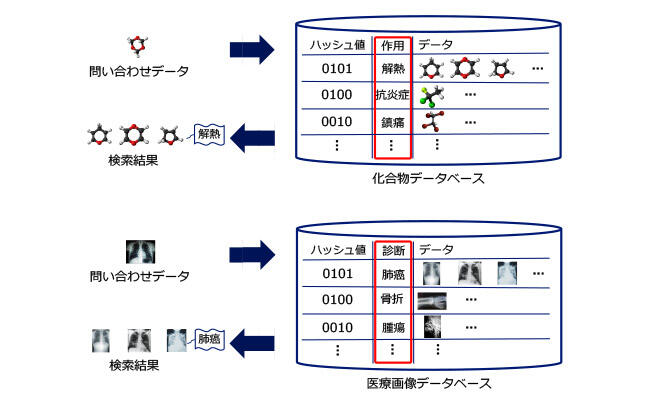 図2:アンカーグラフハッシングの応用例
図2:アンカーグラフハッシングの応用例
2.研究の成果
本成果ではアンカーグラフハッシングにおいて、アンカーグラフの疎な性質を利用し、ハッシュ値計算の高速化を実現しました。アンカーグラフでは n 個のデータはノードとして表現され、それらは近接するデータから選択されたアンカーと呼ばれる少数のノードに接続しています(図3)。アンカーとはデータの中から選択されたクラスタを代表するデータです。アンカーグラフの計算においてはデータのラベルは必要ありません。アンカーの数が m 個であるとき、アンカーグラフにおいてデータとアンカーの繋がりは疎な n×m 行列として表現できます(図4上)。
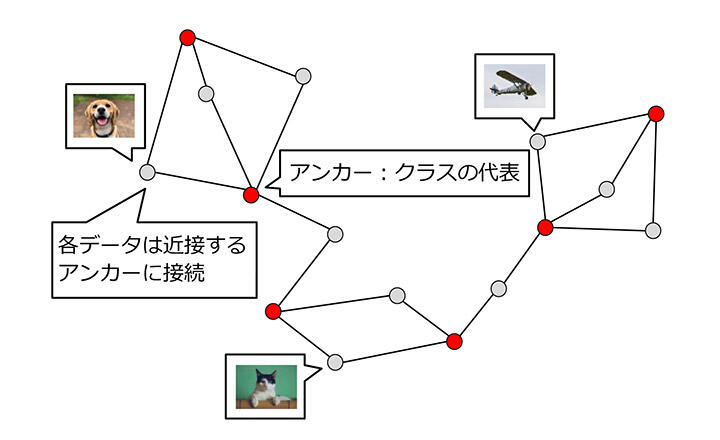 図3:アンカーグラフ
図3:アンカーグラフ
従来のアンカーグラフハッシングではハッシュ値を計算するために疎なデータとアンカーの行列からアンカー同士のつながりを表す m×m 行列を計算します(図4上)。アンカーは複数のデータを介してつながっているため、この行列は密になります。従来のアンカーグラフハッシングではこの密な行列の固有値分解(※4)を計算し、それの固有ベクトルからハッシュ値を計算します。しかし m×m の密な行列の固有値分解には高い計算コストが必要になるためハッシュ値を計算する時間が長くなってしまいます。
本技術ではハッシュ値を計算するために m×m の密な行列を計算せずに、それと同じ固有値を持つ三重対角行列(※5)という疎な行列を計算します(図4下)。この疎な三重対角行列を用いて固有値の下限値から高速に固有ベクトルを計算することで、ハッシュ値を計算する処理時間を大幅に低減しました。
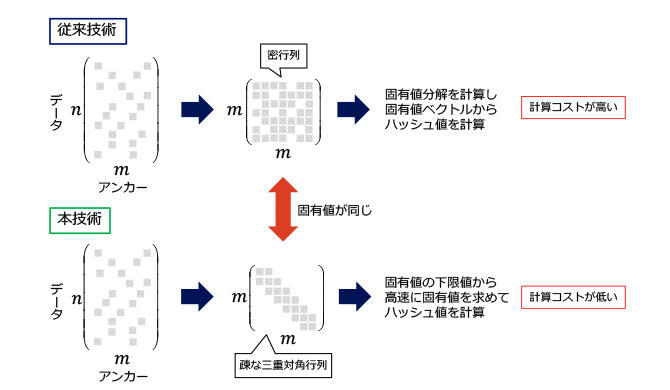 図4:従来技術と本技術の概要
図4:従来技術と本技術の概要
3.技術のポイント
本技術のポイントは、①疎な三重対角行列をアンカーグラフから高速に計算可能にしたことと、②三重対角行列の固有値計算を高速化したことの2つがあります。
アンカー間の m×m の行列と同じ固有値を持つ三重対角行列を計算するには、その m×m の行列とベクトルの掛け算を繰り返し行う必要があります。しかしこの行列は密であるため高い計算コストが必要でした(図5左)。本技術ではアンカー間の m×m の行列の代わりに、データとアンカーの n×m 行列を用いて三重対角行列を計算します。図3のとおりにアンカーグラフではデータとアンカーが疎につながっているので、この n×m 行列は疎な構造となります。そのためn×m 行列とベクトルの掛け算は高速に処理できます(図5右)。
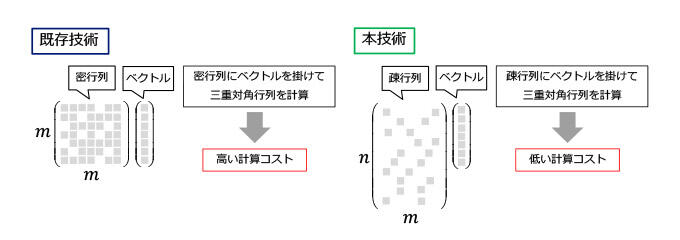 図5:三重対角行列の高速計算
図5:三重対角行列の高速計算
三重対角行列の i 番目に大きい固有値を σi としたとき、三重対角行列の固有値を求めるには σi-1≤σi≤σi≤σi≤σi+1 となるような、σi を挟み込む σi と σi を計算する必要があります。既存技術では大きい順に固有値を求める処理において σi=0 と初期化し、そこから繰り返しσi の値を更新するため計算コストが高くなっていました(図6左)。本技術ではグラフカットという技術を使って固有値 σi の下限値で σi を初期化し更新を減らします(図6右)。このグラフカットとは三重対角行列をブロックに分割できる技術です。固有値の下限値はブロックにおける要素の和から計算できるため、効果的に σi の更新を減らせます。
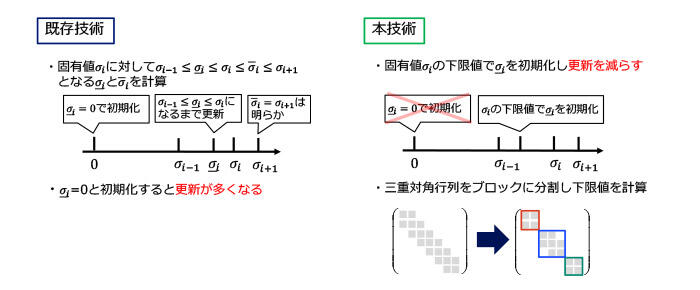 図6:固有値の高速計算
図6:固有値の高速計算
本技術により固有値とその固有ベクトルを高速に計算することで、データのハッシュ値を求める処理時間を大幅に減らせます。データの数が数千万個以上のものを含む connect-4、epsilon、mnist、kitsune、wesad の5個のデータセット(表1)に対して、本技術と従来技術を用いたハッシュ値の計算時間を示します(図7)。ここでアンカーの数は m=300 です。従来技術におけるハッシュ値の計算時間はそれぞれ 11.4 秒、7.8 分、1.1 時間、1.2 時間、4.3 時間ですが、本技術はそれぞれ 2.4 秒、5.3 分、0.5 時間、0.2 時間、0.7 時間と最大で 80% 以上計算時間を削減でき、数千万個規模のkitsuneやwesadであっても1時間以内にハッシュ値を計算できます。kitsuneはサイバー攻撃におけるトラフィックのデータですが、この結果は本技術を用いることによりゼロデイ攻撃のような新種のサイバー攻撃であっても短時間に検出可能になることを示しています。また一般的に高速化と検索精度はトレードオフの関係がありますが、本技術は正確に固有値とその固有ベクトルを計算できるため、検索結果を犠牲にすることなく高速にデータを格納できます。アンカーグラフハッシングは創薬やがん検診などの様々なアプリケーションで利用されていますが、本技術によりこれらのアプリケーションを膨大な量のデータに適用することが可能になります。
表1:データセット
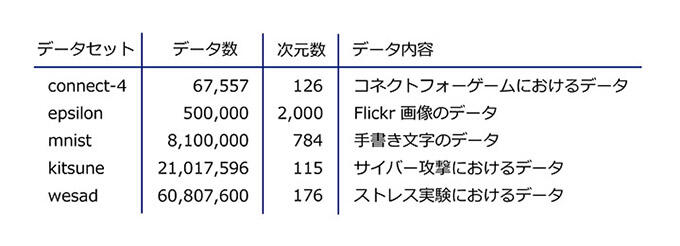
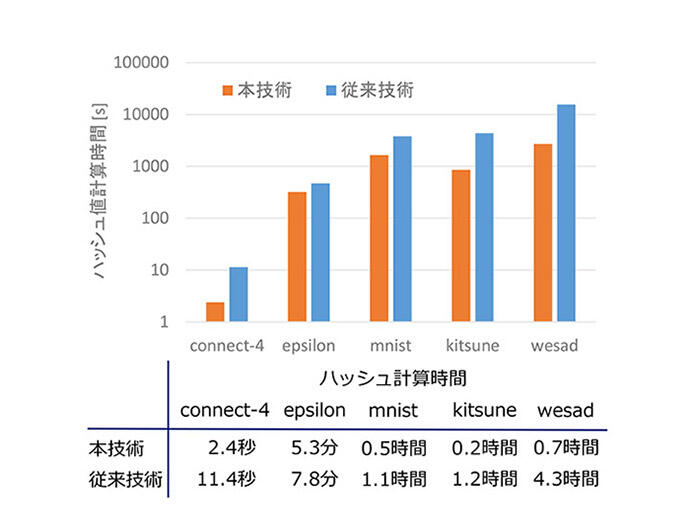 図7:ハッシュ値の計算時間
図7:ハッシュ値の計算時間
4.今後の展開
アンカーグラフハッシングは創薬やがん検診などの様々な類似検索の場面で利用されていますが、本技術により膨大な量のデータへの適用が可能になることや、これまでアンカーグラフハッシングを適用不可能と考えられていた大規模なデータに基づいた様々なアプリケーションへの活用が期待されます。
発表について
本成果は 2021年8月16日~20日(中央ヨーロッパ時間)に開催されているデータベース分野のトップ会議 VLDB 2021 (The 47-th International Conference on Very Large Data Bases) にて下記のタイトル及び著者で発表されます。
Title: Fast Algorithm for Anchor Graph Hashing
Authors: Yasuhiro Fujiwara、 Sekitoshi Kanai、 Yasutoshi Ida、 Atsutoshi Kumagai、 Naonori Ueda (NTT)
用語解説
※1ハッシング技術:
データを0と1の2値で表現し、問い合わせデータと類似したデータを高速に検索する技術
※2アンカーグラフハッシング:
データをノード、データから選択されたクラスタを代表するデータをアンカーとするアンカーグラフを用いて類似検索のためのハッシングを計算する手法
※3グラフ構造:
データとそれらのつながりの関係性をそれぞれノードとエッジとして表現するデータ構造
※4固有値分解:
ある行列を、その行列の固有値からなる行列と固有ベクトルからなる行列に分解する手法
※5三重対角行列:
対角成分とその上下の成分のみが非零となる行列
本件に関する報道機関からのお問い合わせ先
日本電信電話株式会社
先端技術総合研究所 広報担当
science_coretech-pr-ml@hco.ntt.co.jp
℡ 046-240-5157
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










