

2021年11月 1日
日本電信電話株式会社
人間に近い情報処理機構を実現した次世代メディア処理AI「MediaGnosis™」を新たに開発
~マルチメディアを統合的に活用したアプリケーションを1つのAIにより実現~
日本電信電話株式会社(東京都千代田区、代表取締役社長:澤田 純、以下「NTT」)は、音声音響・画像映像・自然言語といったマルチメディアを統合的にオールインワンで扱うことで、人間に近い情報処理機構を実現した次世代メディア処理AI「MediaGnosis™」(※1)を新たに開発しました。本技術では、「知識統合型アーキテクチャ」により、音声認識・画像認識・機械翻訳などの様々なAI機能(以下、各種メディア処理AI機能)を1つに統合することで、効率的な「学習」と、高精度かつ総合的な「推論」を実現します。本技術により、マルチメディア間の相互の特徴を活用した様々なアプリケーションを、1つのAIにより実現することが可能となります。なお、2021年11月16日~19日に開催するNTT R&Dフォーラム2021(※2)にて、本技術、および本技術を活用したアプリケーションを展示致します。
1.背景および目的
データとデジタル技術を活用し既存の仕組みを変革することで新しい価値を創造するデジタルトランスフォーメーション(DX)が様々な分野で重要視されております。このDXの効果的な実現には、メディア処理AIと呼ばれる技術が鍵を握っていると考えられております。これまで、各種メディア処理AI機能がDXに活用されてきておりますが、まだまだ限定的な用途となっており、AIに基づくDXをより幅広い場面で推進するためには、さらなる技術の高度化が必要となります。
2021年現在、市場において一般的に使用される各種メディア処理AI機能は、それぞれ独立に技術開発された上で構築されており、人間に例えるならば、「それぞれの知覚機能ごとに、1つずつ脳が準備されている」ことに相当して動作しております。一方人間は、1つの脳に五感で得られた知識を蓄積することができ、その知識を共通的に参照しながら様々な情報を処理することが可能です。人間はこのような情報処理機構を持つからこそ、効率的に知識を蓄えて成長することができ、その知識を活用して世の中の様々な情報を正確に理解することができます。
そこでNTTでは、AIにも人間と同様の情報処理機構を持たせることで、人間のような効率的な「学習」や、マルチメディアの同時処理による高精度かつ総合的な「推論」が可能になると期待して、研究開発を進めております。
2.技術の概要と特徴
NTTでは、人間に近い情報処理機構を実現した次世代メディア処理AI「MediaGnosis™」(図1)を新たに開発しました。「MediaGnosis™」では、音声音響処理・画像映像処理・自然言語処理といったマルチメディアの情報処理を統合的にオールインワンで扱うことで、これまでよりも効率的な「学習」と、高精度かつ総合的な「推論」を実現します。なお、「MediaGnosis™」の名称は、「あらゆるMedia(情報の記録)を、人間のように統合的にGnosis(知識)とし、それをもとにDiagnosis(判断)する」ということに由来しております。
 図1. MediaGnosisのロゴ
図1. MediaGnosisのロゴ
「MediaGnosis™」の特徴は、「知識統合型アーキテクチャ」により、人間のように1つの脳(AIにおいてはモデル)の中で、各種メディア処理AI機能を統合的にサポートするモデリングを行うことができる点です。具体的に「知識統合型アーキテクチャ」では、図2に示すように、入力モーダル(音声音響情報・画像映像情報・自然言語情報、など)、および出力対象(数値・ベクトル・ラベル・テキスト、など)の両者に対して、複数の機能間で同様の役割を持つ情報処理機構(理解部)を、複数の機能間で共通化します。これにより、1つのモデルの中に様々なAI処理機能を統合することが可能となります。なお「MediaGnosis™」には各種メディア処理AI機能に関するNTTの最新の研究成果(※3)が内包されております。
本技術により、①これまでよりも少ないデータ量で、人のように効率的な知識獲得が可能な「学習」が実現できます。例えば、音声認識の学習を行うことで、画像認識や機械翻訳の性能改善につなげることが可能となります。そして、②複数の機能を同時に駆動した「推論」が実現できます。例えば、声質とその言葉の内容、表情を同時に考慮して人の感情を推論することが可能となります。
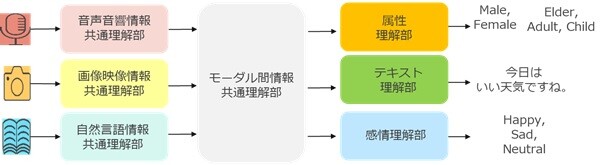 図2. 知識統合型アーキテクチャの概略図
図2. 知識統合型アーキテクチャの概略図
3.本技術により実現できるアプリケーション
「MediaGnosis™」では、マルチメディアの情報処理を統合的に扱うことにより、メディア処理AI機能に基づく多様なアプリケーションを、1つのAIにより実現することが可能となります。具体的には、個別のメディア処理AI機能はもちろんのこと、ユースケースに応じて容易に複数のメディア処理AI機能を組み合わることができ、マルチモーダル・マルチメディア間の相互の特徴を活用したアプリケーションを実現できます。
本技術を活用したアプリケーションの例として、2021年11月16日~19日に開催予定のNTT R&Dフォーラム2021では、「コミュニケーション時の振る舞いから魅力となる個性を見つけ出すシステム」と、「複数人コミュニケーションをリアルタイムで可視化することでリモート会議の活性化・円滑化を狙うシステム」をご紹介いたします。
4.将来への展望
「MediaGnosis™」の一部の機能(知識集約型アーキテクチャ上でモーダル独立に処理する機能)は、実用化に向けた検討が進んでおり、2021年度中に商用展開予定です。その他の機能(複数モーダルを同時に処理する機能)については、実用に向けたフィージビリティの検証を現在進めており、2022年度中に商用展開予定です。本技術を展開することで、より幅広い場面でAIによるDXを推進するとともに、NTTが掲げるIOWN構想で中核的な役割を担うデジタルツインコンピューティングの実現を加速します。さらに、汎用AIの実現に向けて、より「人間に近い情報処理機構」を追求することで、「MediaGnosis™」の高度化を推進します。
※1MediaGnosisは日本電信電話(株)の商標です
※2NTT R&Dフォーラム2021のホームページ:http://www.rd.ntt/forum/![]()
本技術に関する技術セミナー:
人のように考え、成長できるAIが切り拓く世界 ~次世代メディア処理AI『MediaGnosis』~
https://www.rd.ntt/forum/lecture.html![]()
※3典型的なもののみ抜粋:
- Ryo Masumura, Naoki Makishima, Mana Ihori, Akihiko Takashima, Tomohiro Tanaka, Shota Orihashi, "Unified Autoregressive Modeling for Joint End-to-End Multi-Talker Overlapped Speech Recognition and Speaker Attribute Estimation", In Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH), 2591-2595, 2021.
- Mana Ihori, Naoki Makishima, Tomohiro Tanaka, Akihiko Takashima, Shota Orihashi, Ryo Masumura, "MAPGN: MAsked Pointer-Generator Network for Sequence-to-Sequence Pre-training", In Proc. International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 7563-7567, 2021.
- Akihiko Takashima, Naoki Makishima, Mana Ihori, Tomohiro Tanaka, Shota Orihashi, Ryo Masumura, "Unsupervised Domain Adversarial Training in Angular Space for Facial Expression Recognition", In Proc. Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), 1054-1059, 2020.
- Tomohiro Tanaka, Ryo Masumura, Mana Ihori, Akihiko Takashima, Takafumi Moriya, Takanori Ashihara, Shota Orihashi and Naoki Makishima, "Cross-Modal Transformer-Based Neural Correction Models for Automatic Speech Recognition", In Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH), 4059-4063, 2021.
- Naoki Makishima, Mana Ihori, Akihiko Takashima, Tomohiro Tanaka, Shota Orihashi, Ryo Masumura, "Audio-Visual Speech Separation using Cross-Modal Correspondence Loss", In Proc. International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 6673-6677, 2021.
- Shota Orihashi, Mana Ihori, Tomohiro Tanaka, Ryo Masumura, "Unsupervised Domain Adaptation for Dialogue Sequence Labeling Based on Hierarchical Adversarial Training", In Proc. Annual Conference of the International Speech Communication Association (INTERSPEECH), 1575-1579, 2020
本件に関する報道機関からのお問い合わせ先
日本電信電話株式会社
サービスイノベーション総合研究所
企画部広報担当
randd-ml@hco.ntt.co.jp
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










