

2023年6月16日
日本電信電話株式会社
学校法人早稲田大学
プログラム中の文字列抽出機能を自動修正する技術を世界に先駆けて実現
~専門知識をもたない開発者でも正規表現の修正が容易に~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:島田 明、以下「NTT」)と学校法人早稲田大学(本部:東京都新宿区 理事長:田中愛治 以下、「早稲田大学」)は、情報漏洩やサービス停止の原因となりうる文字列抽出機能の誤りを自動修正する技術を世界で初めて実現しました。Webサービスにおけるユーザの入力値などから任意の文字の並び(文字列)を抽出する場合、一般的に文字列パターンを表すために正規表現(※1)と呼ばれる記法が利用されています。正規表現は複雑な文字列パターンを簡潔に記述可能である反面、非常に難解であり、誤った記述が修正されないまま残っている事例が確認されています。
本技術により、専門知識を持たない開発者でも正規表現の誤りを自動修正することが可能になるため、安全なサービスの実現が期待できます。
本技術の詳細は、2023年6月17日に開催されるプログラミング言語分野の最難関国際会議PLDI2023(※2)にて発表を予定しています。
1.背景
正規表現は、ほとんどのプログラミング言語に組み込まれて利用されており、WebサイトのURLに含まれるユーザIDの抽出(図1)など、さまざまなソフトウェア/サービスで幅広く利用されています。
しかし、正規表現を用いたプログラムの動作を人間が正確に理解することは難しく、一般公開されているオープンソースのプログラムにも誤った正規表現が修正されないまま残っています(※3)。これらの誤った正規表現はシステムの誤動作を引き起こし、情報漏洩やサービス停止の原因となることが知られています。また、これを意図的に起こそうとするサイバー攻撃も顕在化しており、安定的なサービス提供を脅かすリスク要因となっています。
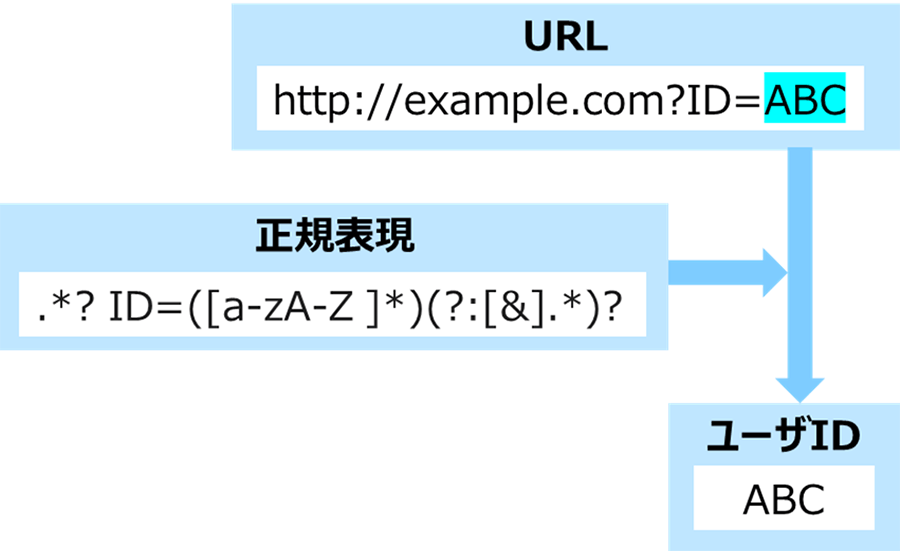 図 1 正規表現を用いた文字列抽出の例
図 1 正規表現を用いた文字列抽出の例
("ID="の後で末尾または"&"の前にあるアルファベット大文字または小文字から成る文字列を抽出する例)
2.研究の成果
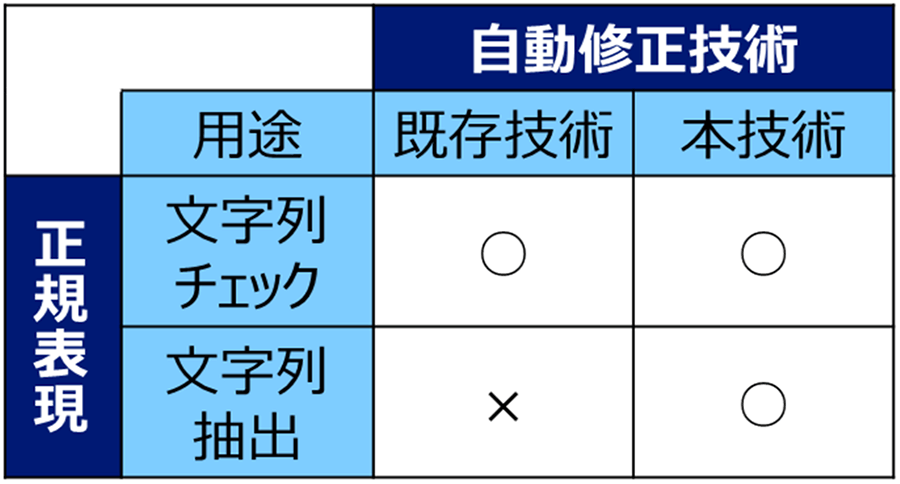
正規表現の主な用途には、文字列が意図したパターンと一致しているか判定する用途(以下、文字列チェック)と文字列から意図したパターンに一致する文字列を抽出する用途(以下、文字列抽出)があります。文字列抽出は、文字列チェックよりも多様なバリエーションを扱うことが求められるため、曖昧性がない形で正確に正規表現を記述するには高い専門知識が必要であり、従来の理論では機械的に修正することが難しいことが知られています。そのため、全ての用途に対応した正規表現の自動修正は実現できていませんでした。
本成果では、正規表現を用いた文字列抽出を行うプログラムの振る舞いを厳密に定義して、その修正問題を形式化し、その修正問題を解くアルゴリズムを考案することで、文字列抽出にも対応した正規表現の自動修正技術を世界に先駆けて実現しました(表1)。これによって、専門知識を持たない開発者でも誤った正規表現を修正することが容易になり、情報漏洩やサービス停止等のリスクを低減することが可能になります。
NTTは、正規表現の解釈を行うプログラムの振る舞いの定義と修正アルゴリズムの考案を行い、早稲田大学理工学術院の寺内多智弘教授はNTTが考案した手法の理論的な正確さの検証を行いました。
表 1 正規表現の用途における本成果の位置づけ
3.技術のポイント
本技術のポイントは、以下の通りです。
- 正規表現によるパターンの確認を実施するプログラム(正規表現エンジン)の振る舞いを理論モデルとして厳密に定義
- 理論モデルに従って修正結果となる正規表現に誤りがないことを保証する条件を生成する方法を提案
- 条件を生成する方法を活用し、修正対象となる正規表現および利用者が望む正規表現に対するポジティブな例(受理される文字列)とネガティブな例(拒否される文字列)を与えると、処理時間短縮のための正規表現の抽象化機能と抽象化された正規表現を、誤りがない具体的な正規表現にする機能を交互に繰り返し実行し、誤りがないことが理論的に保証された正規表現を出力するアルゴリズムを考案(図2)
本技術では、Webアプリケーションなどで広く利用されている ECMAScript 2023 (※4)に完全に準拠した正規表現エンジンの振る舞いを厳密に定義しました。
このように、プログラムがある性質を満たすことを論理的に検証し、特定の不具合が存在しないことを保証する手法は「形式検証(※5)」と呼ばれ、従来の発見型のレビューやテストによる網羅性を持たない検証の問題点を解決でき、高品質なソフトウェアを効率的に生成できると期待されています。
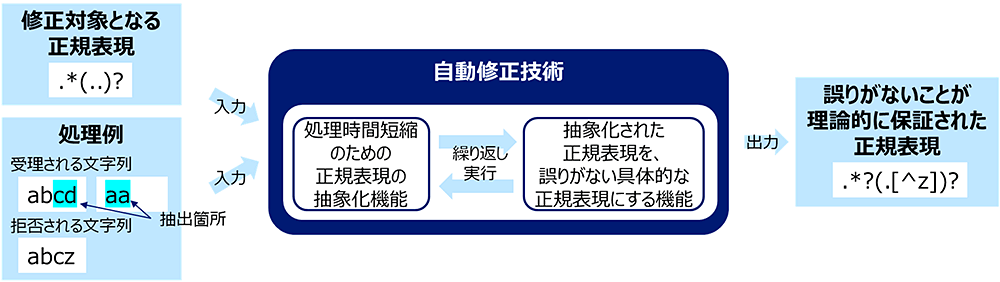 図 2 正規表現を用いた文字列抽出の例
図 2 正規表現を用いた文字列抽出の例
4.今後の展開
本技術は、世界中で幅広く使われている正規表現の誤った記載を自動的に修正する技術であり、本技術を活用することで専門的な知識経験を持たずとも安全なソフトウェアの創出を可能にするものと期待されます。また、AIを用いたプログラムの自動生成が一般的になりつつありますが、非熟練者がAIを用いて作成したプログラムに含まれる誤りにどう対処するのかという新しい問題も生まれています。正規表現の誤りを自動修正する本技術は、AIによる自動化のメリットを損なうことなくプログラムの安全性向上に寄与できるものと期待されます。
発表について
本成果は、2023年6月17~22日に開催されるプログラミング言語分野の最難関国際会議PLDI2023(Programming Language Design and Implementation 2023)にて、下記のタイトル及び著者で発表されます。
タイトル:Repairing Regular Expressions for Extraction
著者:Nariyoshi Chida (NTT Social Informatics Laboratories), Tachio Terauchi (Waseda University)
URL:https://dl.acm.org/doi/10.1145/3591287![]()
用語解説
※1正規表現・・・コンピュータで特定の文字の並び(文字列)をルールに基づき簡略化して表現する方法の1つで、特定の文字列のパターンを検索・抽出・置換するときに用いられる。
※2PLDI・・・Programming Language Design and ImplementationはACM(Association for Computing Machinery)によって運営されるプログラミング言語分野の最難関国際会議。
URL:https://pldi23.sigplan.org/![]()
※3文字列に関するバグの実態調査によると、調査対象のオープンソースプロジェクトには204個のバグがあり、そのうち75個が正規表現の誤りであったとされています。
※4ECMAScript 2023・・・ECMAScriptは、Webアプリケーションなどで広く利用されているプログラミング言語JavaScriptの標準規格。本技術は2023年に改定されたECMAScriptを対象に検証を実施。
※5形式検証・・・プログラムの状態をモデル化し、ある性質を満たしていることを論理的に検証する高信頼なソフトウェアを設計・開発する手法。
本件に関する報道機関からのお問い合わせ先
日本電信電話株式会社
サービスイノベーション総合研究所
広報担当
nttrd-pr@ml.ntt.com
学校法人早稲田大学
広報室広報課
koho@list.waseda.jp
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










