

2023年6月19日
日本電信電話株式会社
自然な音を聴き分ける人工ニューラルネットワークが音の振幅の変化に対して人間のような反応を示すことを発見
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:島田 明、以下「NTT」)は、自然な音(※1)を聴き分ける人工ニューラルネットワーク(NN、※2)が音の振幅の変化に対して人間のような反応を示すことを発見しました。本成果により、これまでに知覚心理学の研究によって調べられてきた人間の振幅変調(AM、※3)の知覚特性と、神経科学の研究によって調べられてきた脳によるAM処理を、ひとつの枠組みで統一的に理解できることが分かりました。将来的には、医療、福祉等においてより人間の耳の仕組みに近いデバイスの開発を初めとした、様々な分野への展開が期待されます。本研究の詳細は、米国東部時間2023年5月24日、米国科学誌「Journal of Neuroscience」に掲載されました。
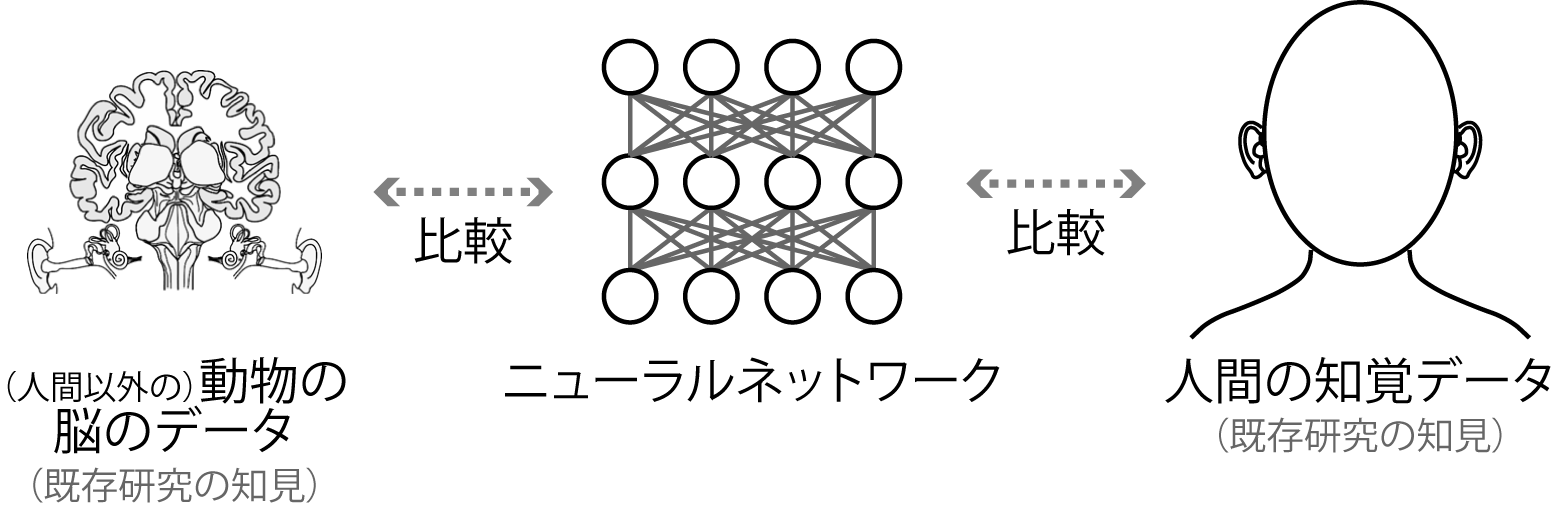 図1.本研究の枠組み。NNの反応を、人間の知覚特性と脳の神経活動とそれぞれ比較した。
図1.本研究の枠組み。NNの反応を、人間の知覚特性と脳の神経活動とそれぞれ比較した。
1.研究の背景
人間は、音に含まれる様々な手がかりをもとに音を認識します。音認識に重要な手がかりのひとつに、音の振幅の緩やかな時間変化のパターン(振幅変調、AM、※3、図2)があります。NTTの研究所ではこれまでに、聴覚によるAM処理を理解するために、人工ニューラルネットワーク(NN、※2)を用いた研究を行ってきました。自然な音を認識するように訓練(※4)した人工NNにAM音を入力しその反応を調べたところ、動物がAM音を聴いているときの脳の反応と類似した反応が得られました。動物の脳におけるAM音への反応も、自然な音を認識するように適応してきた結果、形作られたものである可能性が示唆されました。しかしながら、これまでは脳にある単一の神経細胞の反応特性を検討していたにすぎず、多数の神経細胞のはたらきによって構成されるであろう知覚と音認識との関係の理解には至っていませんでした。また、これまでは人間以外の動物の脳についての検討のみであり、単一の神経細胞からの計測が容易でない人間の知覚についても、同じ枠組みで説明できるかどうかわかっていませんでした。そこで私たちは新たに、NNを人間の知覚特性と比較する研究を行い、その類似性を明らかにしました。
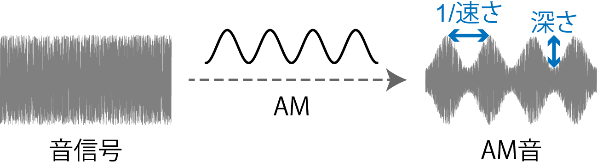 図2.音のAMの例。音信号にAMをかけると、振幅が緩やかに変化するようになる。AM音の重要なパラメータに、速さと深さがある。
図2.音のAMの例。音信号にAMをかけると、振幅が緩やかに変化するようになる。AM音の重要なパラメータに、速さと深さがある。
対象とする知覚特性として、多くの聴覚研究で調べられてきた、人がAMを聞き取れる深さの最小限界値(AM検出閾値、※5)に着目しました。AM検出閾値の特性から聴覚によるAM処理に関する多くの知見が得られていますが、人間の日常生活にとって重要な聴覚機能である自然な音の認識との関係はあまり明らかではありませんでした。
2.研究の成果
自然音認識で訓練した人工NNを用いて、そのNNに対して知覚実験と神経活動記録実験をシミュレーションしました。その結果、NNの構築の際に人間や動物の聴覚の性質を考慮していなかったにもかかわらず、人間のようなAM検出閾値の特性を示すことがわかりました(図3)。ここから、人間のAM検出閾値も、進化や発達の過程で聴覚系が音認識に適応してきた結果得られた性質である可能性が示唆されます。さらに、その特性を得るためには自然な音に含まれるAMが重要であることがわかりました。また、人間のようなAM検出閾値の特性を示すモデル内の領域が脳の下丘・内側膝状体・聴覚皮質と対応していることもわかり、人間のAM検出に関わる脳部位についても示唆を与えることができました(図4)。
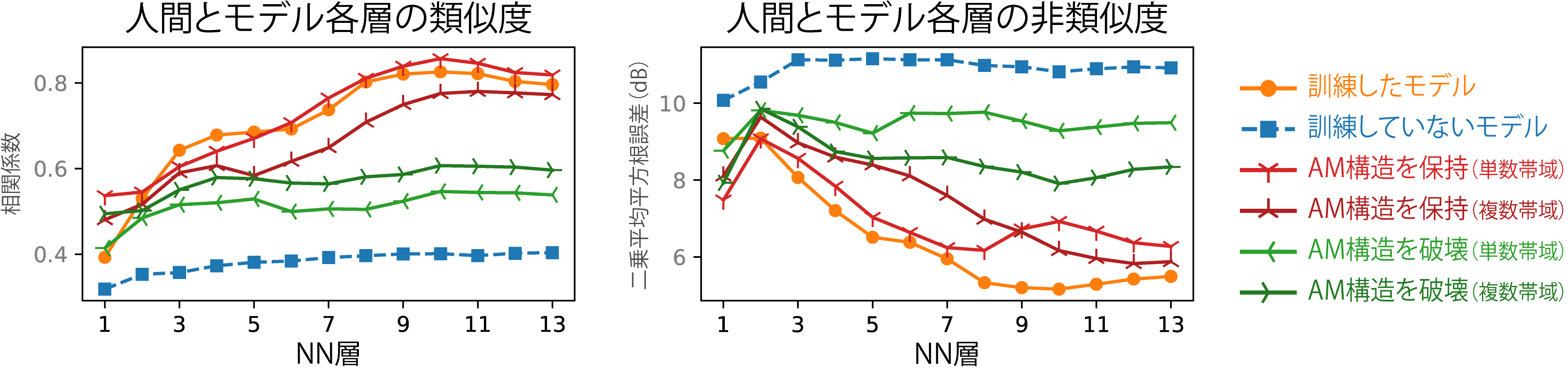 図3.人間とモデル各層のAM検出閾値の類似度(左)と非類似度(右)。類似度が高いほど、また、非類似度が低いほど、人間と似ている。それぞれの線で、自然な音で訓練したモデル、訓練していないモデル、AM構造を保持した音で訓練したモデル、AM構造を破壊した音で訓練したモデルについて示した。
図3.人間とモデル各層のAM検出閾値の類似度(左)と非類似度(右)。類似度が高いほど、また、非類似度が低いほど、人間と似ている。それぞれの線で、自然な音で訓練したモデル、訓練していないモデル、AM構造を保持した音で訓練したモデル、AM構造を破壊した音で訓練したモデルについて示した。
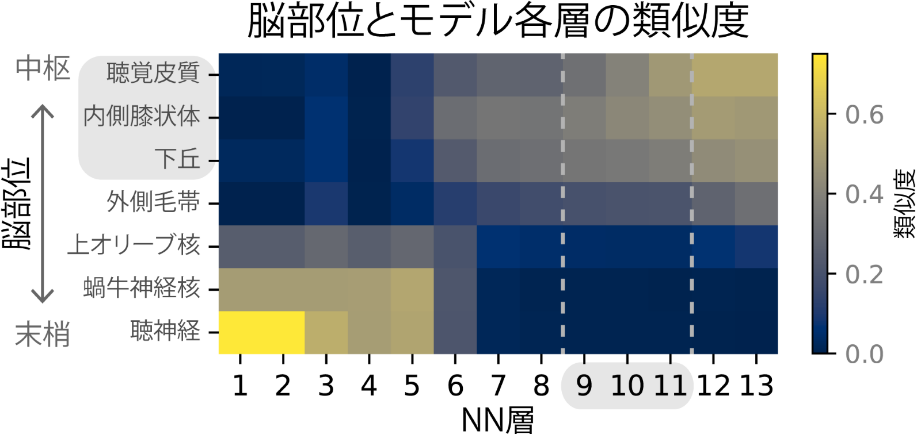 図4.NNの層(横軸)と脳部位(縦軸)との対応。色の明るさで類似度を示した。図3で人間のようなAM検出閾値を示した層(9-11層目付近、横軸の灰色背景)が、下丘・内側膝状体・聴覚皮質(縦軸の灰色背景)と類似していることがわかる。
図4.NNの層(横軸)と脳部位(縦軸)との対応。色の明るさで類似度を示した。図3で人間のようなAM検出閾値を示した層(9-11層目付近、横軸の灰色背景)が、下丘・内側膝状体・聴覚皮質(縦軸の灰色背景)と類似していることがわかる。
本研究により、これまでの知覚心理学と神経科学の知見を、自然な音に適応した結果として統一的に説明することができるようになりました。
3.研究のポイント
・知覚実験のシミュレーション
AM検出実験の計算機シミュレーションには、人間の知覚心理実験となるべく同じ刺激音を用いました。これにより、得られたAM検出閾値の数値を人間と直接比較することができるようになりました。NNに刺激音を入力すると、NNの各素子から活動値の時系列が得られます。NNのAM検出閾値を計算するために、NNの層ごとに素子の活動値を時間平均し、その時間平均値から刺激音がAM音か非AM音どうかを推定しました(図5)。この手続きを様々な深さを持つAM刺激について行い、刺激音がAM音かどうか判別できる最小のAM深さ(つまりAM検出閾値)を計算しました。
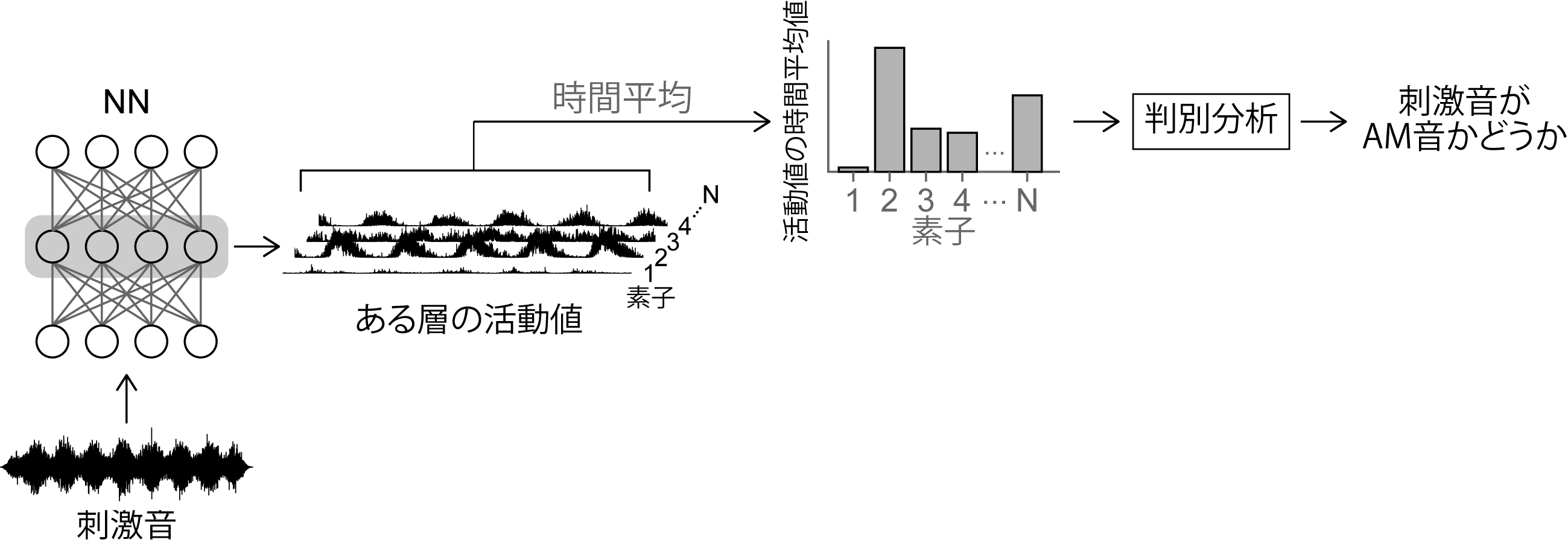 図5.AM検出実験の計算機シミュレーション。音をNNに入力し、ある素子の活動値を時間平均したものから、入力音がAM音かどうかを判別した。
図5.AM検出実験の計算機シミュレーション。音をNNに入力し、ある素子の活動値を時間平均したものから、入力音がAM音かどうかを判別した。
・人間のようなAM検出閾値を獲得するために必要な音の特徴
NNが人間と類似したAM検出閾値を獲得するためには、訓練に使われた自然音のAMパターンが重要であることも確認しました。自然なAM構造を保持した音(※6)と、その構造を破壊した音(※6)を作成し、それぞれの音の認識で訓練したNNを構築しました。AM構造を保持した音で訓練したNNは人間と類似したAM検出閾値の特性を示しましたが、AM構造を破壊した音で訓練したNNは人間と類似したAM検出閾値の特性を示しませんでした(図3)。
4.今後の展開
知覚心理学の研究では、検出閾値といった知覚的な特性を説明・理解するために、感覚情報処理を複数の段階を積み重ねたモデルによって表現することが通例です。人間のAM検出閾値に関しても、これまでに優れたモデルが提案されています。今後は、このような既存のモデルにおける処理段階と本研究で構築したモデルとの対応関係を明らかにし、聴覚情報処理のどの段階が音認識への適応で説明できるのか・できないのかを、詳細に検討していきます。
本研究では、自然音に含まれるAMパターンがNNの形成に重要であるという示唆が得られました。この知見は脳の発達・可塑性や「聞こえ」の困難のメカニズムの理解にもつながる可能性があります。例えば聴覚末梢に何らかの障害が発生すると、脳に届く信号の特徴も変化します。このような状態をモデル化できれば、難聴またはその補償によって生じうる脳の情報処理への影響について分析可能となり、医療、福祉等においてより人間の耳の仕組みに近いデバイスの開発つながることが想定されます。
本研究の枠組みは、AM処理以外の聴覚機能やより一般の感覚機能へ拡張することもできます。例えば、両耳からの音の情報の統合処理は、AM処理と同じくらい深く研究されていますが、人間の両耳音処理に関する心理学的な知見と神経科学的な知見の統一的な理解はあまり進んでいません。本研究のパラダイムを用いることを通じ、これらの性質の起源やメカニズムを探ることをめざします。
【本研究への支援】
本研究はJSPS科研費20H05957(学術変革領域研究(A) 深奥質感)の助成を受けたものです。
【掲載論文】
Human-like Modulation Sensitivity Emerging through Optimization to Natural Sound Recognition. Takuya Koumura, Hiroki Terashima, and Shigeto Furukawa. Journal of Neuroscience 24 May 2023, 43 (21) 3876-3894; https://www.jneurosci.org/content/43/21/3876![]()
用語解説
※1自然な音
人間が日常的に耳にする音を、ここでは自然な音と呼ぶ。例えば、動物の鳴き声、雨の音、くしゃみの音、ドアが軋む音、車のエンジン音、など。
※2人工ニューラルネットワーク(NN)
機械学習のモデルの一種で、複雑な分類課題を高精度で行う有力技術としても用いられる。多数の素子からなる多数の層が縦列した構造により、データを処理する。ある層のある素子はその一段下の層の素子から入力を受け、単純な処理を経た後にその出力が次の層の多数の素子に伝達される。
※3振幅変調(amplitude modulation, AM)
信号の振幅を緩やかに変化させること、またはその変化のパターン。振幅変調を記述する重要なパラメータに、速さと深さがある(図2)。
※4機械学習モデルを音認識で訓練
音認識の精度が高くなるように、モデルのパラメータを調整すること。モデルがNNの場合、層内の素子数や素子間の結合パターン・結合強度などのパラメータを調整する。
※5AM検出閾値
ある音がAM音かどうかを聴き分けられる最小のAM深さ。実験的には、AM音と非AM音(振幅の緩やかな変化が無い音)を区別できるかどうかで調べる。一般に、AMは深いほど聴き分けやすい。
※6AM構造を保持・破壊した音の作成
ある音を、AM構造を反映した振幅包絡と、より細かな変動である時間微細構造に分け、元の音の振幅包絡と雑音の時間微細構造を組み合わせることにより、AM構造を保持した音を作成した。元の音の時間微細構造と時間変化しない振幅包絡を組み合わせることにより、AM構造を破壊した音を作成した。音を振幅包絡と時間微細構造に分割するためには、ヒルベルト変換という操作を行った。
本件に関する報道機関からのお問い合わせ先
日本電信電話株式会社
先端技術総合研究所 広報担当
nttrd-pr@ml.ntt.com
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










