

2024年5月 7日
日本電信電話株式会社
株式会社NTTデータ数理システム
連合学習において一部のクライアントに異常や悪意がある場合にも高精度にAIモデルを学習可能な手法を開発
~LLM tsuzumi の学習への適用やIOWN機能としての実用化を目指す~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:島田 明、以下「NTT」)と株式会社NTTデータ数理システム(本社:東京都新宿区、代表取締役社長:箱守 聰、以下「NTTデータ数理システム」)は、複数のクライアント(個人や組織)でデータを保持したまま分散して学習する連合学習において、一部のクライアントに異常や悪意がある場合にも高精度にAIモデルを学習可能な学習手法を開発しました。クライアント間で統計的なデータの偏りがある場合において、耐障害性が最も優位なアルゴリズムです。
個人情報などの機微なデータを使って複数者で学習する場合、データを手元に置いたまま安全に学習可能な連合学習が注目されています。しかし、異常な動きをする参加者がいた場合に、連合学習で得られるモデルの精度劣化を引き起こすことが知られています。
本技術(モメンタムスクリーニング技術※1)により、すべての参加者が正常であることを前提とせず、高精度なAIモデルを分散して構築できるようになり、安全かつ安定した学習の実現ができます。本技術は機械学習分野の三大トップカンファレンスの1つであるInternational Conference on Learning Representation 2024(ICLR2024:5月7日~11日)に採択され、オーストリア・ウィーンで発表予定です。
1. 背景
近年、組織や分野横断でデータを活用することで、新たな価値を創造することが大きく期待されています。例として、社内文書を活用した業務DXや希少疾患の医療診断を支援するAIモデルの構築などが挙げられます。
しかし、扱われるデータは個人情報や機密情報を含むことがあり、情報漏洩のリスクなどの観点から組織間でのデータの共有は進んでいません。そこで、データを共有せず、それぞれのデータを用いて学習されたAIモデルを共有することで、それぞれのデータの特徴を反映した一つのモデルを作成する技術として連合学習が注目されています。
図1のように、連合学習では、複数のクライアントがそれぞれのデータを使ってローカルモデルを学習し、中央サーバは複数のローカルモデルの平均化などの処理により、単一のグローバルモデルを作成するプロセス(ラウンドと呼ぶ)を繰り返すことでAIモデルを学習します。
![図1 従来の機械学習(左)と連合学習(右)の比較 [画像出典] 連合学習とは?Federated Learningの基礎知識をわかりやすく解説(※2)](img/240507aa.jpg) 図1 従来の機械学習(左)と連合学習(右)の比較
図1 従来の機械学習(左)と連合学習(右)の比較
[画像出典] 連合学習とは?Federated Learningの基礎知識をわかりやすく解説![]() (※2)
(※2)
連合学習の課題として、学習に参加するクライアントの一部が異常あるいは悪意を持って、正常なクライアントとは大きく異なる学習モデルを共有した場合に、連合学習自体が困難になることが挙げられます。悪意のあるクライアントがいる場合でも、悪意のあるクライアントがいない場合と同様に、連合学習自体はうまくいくことが求められ、それが実現されるアルゴリズムはビザンチン耐障害性があるとされます。ビザンチン耐障害性は、ラベル付のミスや、計測エラーによる学習データの品質劣化に対して効果を発揮します。また、連合学習に不特定多数が参加し、その中でクライアントの乗っ取りなど悪意のあるクライアントが想定される場合にも有効です。
 図2 ビザンチン耐障害性を持つ連合学習のイメージ
図2 ビザンチン耐障害性を持つ連合学習のイメージ
2. 研究の成果
ビザンチン耐障害性のある連合学習手法では、全クライアントのうち悪意のある行動(実際とは異なる学習モデルの共有など)をするクライアントが50%未満である場合、悪意のあるクライアントがどのような行動をしたとしても、その手法の精度の低下を小さくすることができます。
連合学習における既存のビザンチン耐障害性のある従来手法として、CClip※3が挙げられます。この手法は連合学習の各ラウンドで、正常なクライアントの勾配(モデルの更新方向)の平均推定量を用いて、全てのクライアントの勾配の影響が小さくなるように補正(Clipping)を行います。これにより悪意のあるクライアントが学習全体に与える影響が小さくなり、ビザンチン耐障害性を得ていました。しかし、各クライアントが持つデータの統計的性質が大きく異なる際には、正常なクライアントの学習も悪意のあるクライアント同様に補正の影響を受けてしまい、学習したモデルの精度が下がる欠点がありました。
本技術では、ラウンドごとではなく、過去のラウンドでの学習情報を適切に用いて、正常および悪意あるクライアントの判定を行うことで、正常なクライアントの学習には補正が加わらず、そのことにより全体で学習したモデルの精度が下がることなく、よりよいモデルを生成することができます。
3. 技術のポイント
モメンタムスクリーニング技術のポイントは以下の通りです。
- モメンタム:学習ごとの勾配ではなく、過去の勾配の指数平均を用いて学習
- スクリーニング:各クライアントのモメンタム同士を比較し、近いモメンタムの割合を閾値以上であれば正常、そうでなければ異常と判断
モメンタムは図3のように過去の勾配の指数平均と勾配を加算し、勾配の代わりに用いることです。スクリーニングは図4のように各クライアントのモメンタム同士を比較し、近いモメンタムが閾値以上あれば正常、そうでなければ異常と判断することです。異常と判断されたモメンタムの情報は使わずにモデル全体の更新を行います。
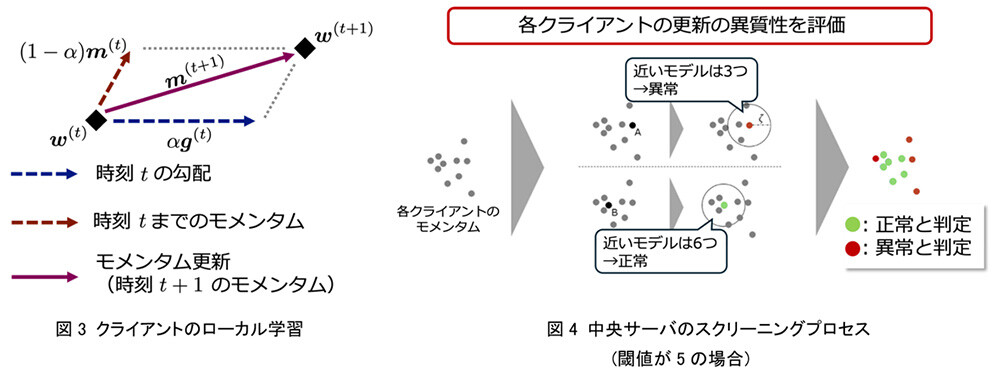
このようにモメンタムにスクリーニングを適用し、精度の高いモデルを学習することができます。また、数理的な証明により、一般的なクライアント間のデータの統計的な偏りを想定した目的関数において、CClipと比べて学習誤差を小さくできることを確認し、さらに、提案手法を上回る手法が存在しないことを確認しました※4。また図5に示すように、画像認識のベンチマークテストを通じて、ビザンチンノードが存在する状況下で、いくつかの従来手法(CClipを含む)よりも、異常挙動に対する最悪ケースの比較において高いテスト認識率のモデルを学習できることを実験的に確認しました。
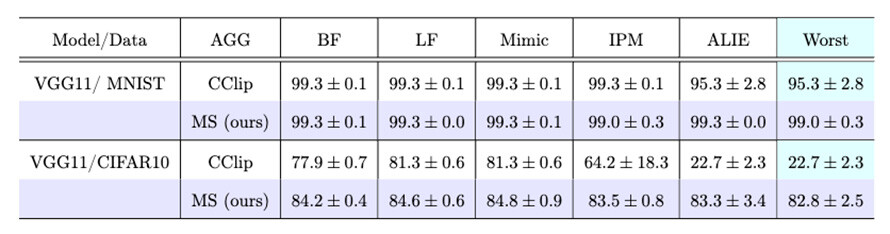 図5 各学習アルゴリズム(行)の各5つの異常挙動(列)に対する学習精度の測定結果
図5 各学習アルゴリズム(行)の各5つの異常挙動(列)に対する学習精度の測定結果
Worst列は、5つの異常挙動の中で最も学習精度が低かった結果を記載
4. 役割
NTT:ビザンチン耐性のあるアルゴリズムの考案
NTTデータ数理システム:主に考案手法の数理的およびシミュレーションにおける正確さの検証実施
5. 今後の取り組み
NTTおよびNTTデータ数理システムは、情報の保護と活用を両立する技術として期待される連合学習技術の開発を通じて、組織横断的に分散蓄積されるデータを用いたAI等の利活用の促進に貢献するとともに、共同実験などを通じて連合学習技術の研究を邁進していきます。また、将来的にはNTTが研究するLLM tsuzumiの学習への適用やNTTが推進するIOWN PETs※5機能として実用化することを目指します。
〈参考・用語解説〉
※1T. Murata, K. Niwa, T. Fukami, and I. Tyou, "Simple Minimax Optimal Byzantine Robust Algorithm for Nonconvex Objectives with Uniform Gradient Heterogeneity," ICLR 2024
[URL] https://openreview.net/forum?id=1ii8idH4tH![]()
※2連合学習とは?Federated Learningの基礎知識をわかりやすく解説![]()
(https://www.msiism.jp/article/federated-learning.html)
※3S. P. Karimireddy, L. He, and M. Jaggi, "Byzantine-Robust Learning on Heterogeneous Datasets via Bucketing," ICLR 2022. [URL] https://openreview.net/forum?id=jXKKDEi5vJt![]()
※4仮定した目的関数のクラスにおいて、提案手法がミニマックス最適性を満たすことを証明。注釈※1参照
※5IOWN PETs:https://www.rd.ntt/sil/project/iown-pets/iown-pets.html![]()
本件に関する報道機関からのお問い合わせ先
日本電信電話株式会社
サービスイノベーション総合研究所
企画部広報担当
nttrd-pr@ml.ntt.com
株式会社 NTTデータ数理システム
営業企画部広報担当
pr-info@ml.msi.co.jp
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










