

2021年3月 2日
日本電信電話株式会社
AI・機械学習分野の難関国際会議 NeurIPS の匿名化技術コンペティションで優勝
~パーソナルデータを安全かつ使いやすく匿名化する新たな手法の実現へ~
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:澤田 純、以下「NTT」)は、2020年12月6日~12日(米国太平洋時間)にオンライン形式にて開催された、AI・機械学習分野の難関国際会議NeurIPS(Neural Information Processing Systems)2020の匿名化技術を競うコンペティション “Hide-and-seek privacy challenge(※1)” (以降、HS Challenge)に濱田浩気主任研究員、長谷川聡研究員がチームとして参加し、優勝しました(注1)。HS Challengeでは、パーソナルデータを安全かつ使いやすく匿名化する技術として近年注目されている「合成データ生成技術」をテーマとして、時系列に記載された診療データを匿名化するタスクと、匿名化したデータを再識別(個人特定)するタスクに分けて参加チームが対戦形式で競います。NTTではかねてから合成データ生成技術を用いた匿名化の研究開発に取り組んでおり、その知見やノウハウを活かし、匿名化と再識別の両方のタスクで1位となりました。今後は国内外の個人情報保護・プライバシー保護関連法規制に適合する匿名化・プライバシー保護技術の開発、およびAIによる同技術の自動処理化を実現し、NTTが推進するIOWN(※2)の匿名化・プライバシー保護機能として実用化することを目指します。
1.NeurIPS2020の匿名化技術コンペティションについて
NeurIPSはAI・機械学習分野の難関国際会議として知られていますが、論文発表のほかAI・機械学習に関する技術力を競うコンペティションが毎年行われています。NeurIPS2020では、公募により前年同様16のコンペティションが採択・開催されました。その一つであるHS Challengeは、医療・ヘルスケアデータの利活用を促進する安全なデータ匿名化方法の創出を目指し、参加チームは先ず “Hider” となって所与のデータ(時系列に記載された2万人以上の患者の臨床データ)を匿名化し、次に “Seeker” となって各参加チーム(Hiders)によって生成された匿名化データを再識別する、対戦形式で競います(図1)。匿名化データは、合成データと呼ばれる元の複数人のデータから生成される擬似的なデータです。合成データを生成する加工技法としてGAN(Generative Adversarial Networks)と呼ばれる機械学習が有名ですが、基本的に匿名性は考慮されておりません。そこで最近では誰のデータを用いて合成データを生成したのか特定する攻撃(=メンバーシップ推定)を防ぐ合成データ生成技術も研究が進められています。このメンバーシップ推定は、匿名性の評価尺度の一つとして知られています。HS Challengeでは、所与のデータから一定割合のデータを抽出し、メンバーシップ推定が困難となるよう合成データを生成します。誰のデータが利用されたかすら分からないような合成データであれば、匿名性は十分守られていると言えるでしょう。このように匿名性を考慮して加工された合成データを我々は「匿名合成データ」と呼んでいます。
一方パーソナルデータの利活用においては、匿名性やプライバシーを守りつつ「使いやすい」データに加工することが必要です。この使いやすさの尺度に「有用性」があります。有用性とは、元のデータから所望の分析を行った結果と匿名化データから同様の分析を行った結果との差異を表したものです。匿名性を高める加工技法として、例えば年齢のデータを年代に変換したり、年齢を少しずらす(ノイズを付加する)ことがありますが、これにより分析結果も一般に変わってきます。これらの加工により分析結果の差異が大きくなるほど有用性が低くなります。HS Challengeでは、有用性の評価尺度としてRNN(回帰型ニューラルネットワーク)の予測モデルおよび推定モデルの学習が用いられました。元のデータからの学習結果と匿名化データからの学習結果の差異が所定の基準値以内になる必要があり、満たさないと失格となります。すなわち、有用性の基準を満たしつつ、他の参加チームにメンバーシップ推定されないよう匿名合成データを生成することが求められます。各参加チームは匿名化のタスクにおいて、最大でチーム人数までの匿名合成データを生成して提出できます。実際は匿名合成データを生成するプログラムを作成して提出します。そして再識別のタスクでは、各参加チームの匿名合成データをメンバーシップ推定するプログラムを作成して提出します。現在まで、HS Challengeの参加チームの情報や結果詳細は明らかになっておりませんが、有用性の基準を満たす匿名合成データを生成できた参加チームはほとんどいなかったことが予想されます。またプログラムを提出して評価対象として残った参加チームは10ほどに絞られ、その多くが機械学習を専門とする海外の大学の研究室や公的研究機関と推定されます。
2.NTTの技術の概要
先ず従来の匿名化を図2に例示します。名前は削除され、年齢は年代に一般化(抽象化)され、入院年月日は年月までに開示制限されています。このように名前の削除以外にも加工を行う理由は、個々のデータからは個人を特定できないとしても、それらのデータを組み合わせて特定個人を推定できるリスクがあるためです。そこでどの程度の加工を行えばよいのか、基準や加工後のデータの匿名性の評価が必要になります。我が国の個人情報保護法では匿名加工情報作成の基準が定められています。
一方、例えば年齢を年代に一般化すれば年齢毎に分類した分析ができません。そこで図3のように年齢を別の値に変換したり(維持置換撹乱、ノイズ付加)、性別や入院年月日を他の人のデータと入れ替える(スワッピング)など確率的な操作(ランダム化)による加工技法も知られています。このような確率的な操作を行い、誰のデータでもない擬似的なデータを生成する技法が匿名合成データ生成です。勿論ただ擬似的なデータを生成すればよいわけでなく、高い有用性と匿名性の保証が求められます。
NTTでは匿名加工情報を作成するための研究開発(※3)を通じ、様々な加工技法、匿名性評価技法、有用性評価技法を考案・開発してきました。その中でも、一般化に加えランダム化した加工データの匿名性も数学的に評価できる「Pk-匿名化」技術(※4)や、維持置換撹乱やノイズ付加した匿名化データから「ベイズ推定技術」を用いて有用性を向上させた合成データを生成する技術(※4)、そして各属性の平均や分散共分散行列が元のデータとほぼ等しい合成データを生成する技術(※5)等を独自に開発してきました。また、一般社団法人情報処理学会 コンピュータセキュリティ研究会の下部組織(PWS組織委員会)が主催する、2015年から毎年開催されている匿名化技術のコンペティション「PWSCUP」(※6)の参加や運営を通じて、匿名化の加工技法、匿名性評価技法、有用性評価技法の効果的な活用に関する知見やノウハウを培ってきました。特に2020年度のPWSCUPのルールはHS Challengeに類似する点が多々あり、HS Challengeのコンペティションに大いに役立ちました。
HS Challengeで我々は、先ず所与のデータに対する有効な攻撃方法を考え、その攻撃方法に対して耐性のある匿名合成データ生成方法を検討しました。攻撃方法については、これまでの匿名性評価技法の研究で培った、元のデータと匿名合成データとの「L2ノルム」(ユークリッド距離)に基づく推定が有効であることを突き止めました。さらに、系列データの長さも考慮することでより推定精度を向上させた攻撃手法を考案し、最も高い攻撃成功率をあげ、攻撃タスクで1位となりました。
一方匿名合成データ生成においては、スワッピングやノイズ付加を用いた確率的な操作と、平均や分散共分散行列が元のデータとほぼ等しくなる匿名合成データ生成手法の2種類を検討しましたが、これだけでは有用性基準を満たさなかったため、想定される様々な攻撃を回避しつつ有用性を向上させる学習モデルを構築しました。結果、スワッピングやノイズ付加を用いた確率的な操作をベースとした手法が、匿名化タスクで1位となりました(後者の手法は3位)。
3.今後の予定
匿名合成データ生成技術は、所定の匿名性基準と有用性基準を満たす匿名化データを機械学習等により効果的に生成することができ、時系列データなど従来の匿名化技術では適用が難しいとされていたものにも有効性が実証されるなど注目を集めています。一方、これまでNTTでは主に、安全で使いやすい匿名加工情報の作成を支援するソフトウェアの研究開発に注力してきました。今後は海外のプライバシー保護関連法規制への対応も検討していきます。さらには、HS Challengeでは所与のデータに対して有効な匿名化技術を人間が試行錯誤しながら判断しましたが、今後はよりデータの利活用を推進するため、AIが所与のデータや利用用途に応じて最適な匿名合成データを生成できる「自己最適匿名化技術」の開発も行ってまいります。そしてNTTが推進するIOWNの匿名化・プライバシー保護機能として自己最適匿名化技術を適用することで、円滑なパーソナルデータの利活用の実現を目指します。
なお2021年3月12日(金)に行われるPWS組織委員会主催のオンラインイベント「PWS2021 Meetup」(※7)にて、HS Challengeの概要説明及び参加報告を行う予定です。
注1コンペティションは延長され、2021年1月中旬に参加者へ結果通知が届きました。2021年2月末現在、運営側からの結果の公表は確認できておりません。
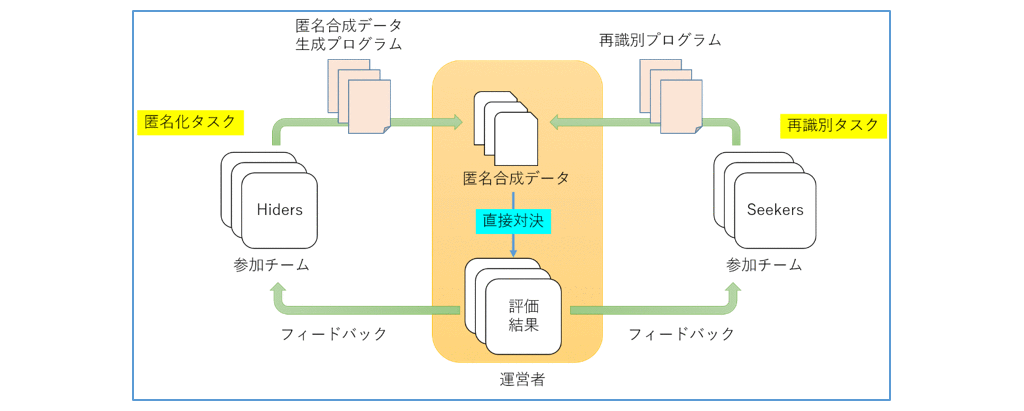 図1 Neur IPS2020匿名化技術コンペティション “Hide-and-seek privacy challenge” の全体像
図1 Neur IPS2020匿名化技術コンペティション “Hide-and-seek privacy challenge” の全体像
(https://www.vanderschaar-lab.com/privacy-challenge/![]()
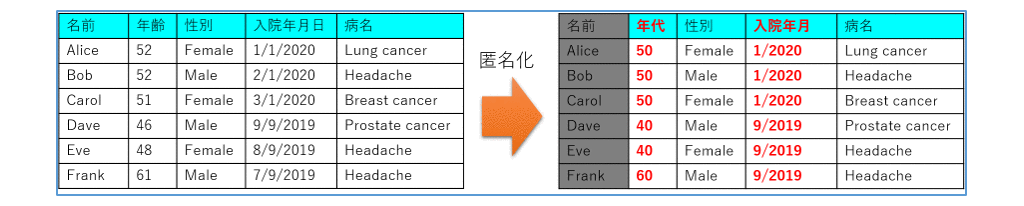 図2 従来の匿名化のイメージ
図2 従来の匿名化のイメージ
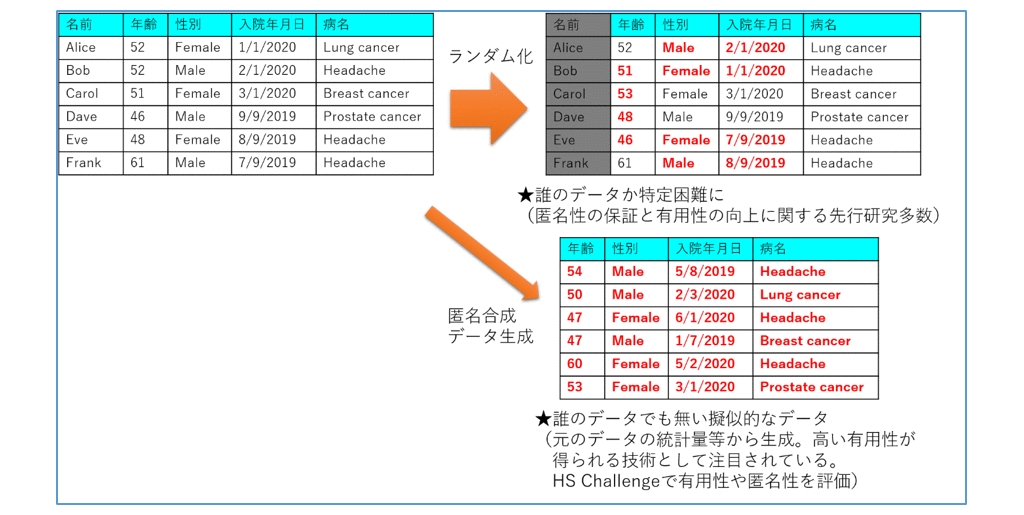 図3 ランダム化による匿名化と匿名合成データ生成のイメージ
図3 ランダム化による匿名化と匿名合成データ生成のイメージ
※1Hide-and-seek privacy challenge
https://www.vanderschaar-lab.com/privacy-challenge/![]()
※2IOWN構想の実現に向けた技術開発ロードマップ
https://group.ntt/jp/newsrelease/2020/04/16/200416a.html
※3安全かつ有用な「匿名加工情報」の作成を支援するソフトウェアを開発
~データの特性や利用目的に応じた最適な加工方法の選択・評価環境を実現~
https://www.ntt.co.jp/news2017/1709/170911a.html
※4ビッグデータ時代における新たなパーソナルデータ匿名化システムを開発
~高度にプライバシー保護したままに、データの利用価値を高いままとする~
http://www.ntt.co.jp/news2014/1402/140207b.html
※5岡田ら:統計値を用いたプライバシ保護擬似データ生成手法, コンピュータセキュリティシンポジウム2017論文集,
https://ipsj.ixsq.nii.ac.jp/ej/index.php?active_action=repository_view_main_item_detail&page_id=13&block_id=8&item_id=187369&item_no=1![]()
※6プライバシーワークショップ(PWS)
https://www.iwsec.org/pws/![]()
※7第6回プライバシーワークショップ (PWS2020)
https://www.iwsec.org/pws/2020/index.html![]()
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。




NTT STORY
NTTとともに未来を考えるWEBメディアです。










