

2024年5月 7日
日本電信電話株式会社
世界初、AIモデルの再学習コストを大幅に削減可能な過去の学習過程を再利用する「学習転移」を実現
~NTT版LLM「tsuzumi」など基盤モデルの更新・差し替えを容易に~
発表のポイント:
- 深層学習において、過去の学習過程をモデル間で再利用する全く新たな仕組みとして「学習転移」技術を実現しました。
- 本技術は、深層学習におけるパラメータ空間の高い対称性を活用し、実際に学習することなく低コストな変換により数秒~数分程度で一定の精度を実現できるため、モデルの再学習コストを抜本的に削減できることを示しました。
- これにより、NTTが研究開発を進める大規模言語モデル(LLM)「tsuzumi(*1)」をはじめとした多様な基盤モデル(*2)の運用コスト削減・消費電力の削減や、多数のAIで議論することで多様な解の創出をめざしたAIコンステレーション(*3)の構想具現化など、次世代のAI技術開発に貢献します。
日本電信電話株式会社(本社:東京都千代田区、代表取締役社長:島田 明、以下「NTT」)は、深層学習において過去の学習過程をモデル間で再利用する全く新たな仕組みとして「学習転移」技術を実現しました。本技術は、ニューラルネットワークのパラメータ空間における高い対称性を活用し、過去の学習過程のパラメータ列を適切に変換することにより、新たなモデルの学習結果を低コストで求めることを可能にします。これにより、生成AIなど大規模な基盤モデルを用途毎に追加学習(以下、チューニング)して利用する場合に不可欠な、基盤モデルの定期的な更新に伴う再チューニングコストを大幅に削減でき、生成AIの運用容易化や適用領域拡大、消費電力の削減に貢献することが期待されます。
なお、本成果は2024年5月7日から11日まで、オーストリア・ウイーンで開催される機械学習分野における最難関国際会議International Conference on Learning Representations (ICLR) 2024(*4)において発表されます。
1. 背景
近年、生成AIとして多様かつ大規模な基盤モデルが利用可能となり、各企業や組織内の要件に対応するため、個々のデータセットでの追加学習により基盤モデルをチューニングして活用することが一般的となっています。しかし、このチューニングは基盤モデルの更新時や異なる基盤モデルへの変更時に再学習が必要となり、多大な計算コストが生じることが課題となっています。例えば、基礎性能の改善や著作権・プライバシー問題など脆弱性への対応により基盤モデル自体が更新されると、それをチューニングして得られていたモデルすべてに対して再度チューニングを実施する必要があります。また、市中で多様な基盤モデルが利用可能となってきていますが、性能向上やコスト削減のために基盤モデルを変更しようとする際には、移行先の基盤モデルで再度チューニングを行う必要があります。
生成AIを活用していく上で、これらチューニングコストは無視できないものであり、将来の生成AIの普及に対して大きな障壁となることが予想されています。
2. 研究成果の概要
一般に深層学習では、与えられた訓練用のデータセットに対して、ニューラルネットワークモデルのパラメータを逐次的に最適化することで学習が行われます。学習中のパラメータ変化に関する履歴はモデルの学習過程と呼ばれ、学習の初期値やランダム性に大きく影響されることが知られています。一方で、初期値やランダム性の異なるモデル間の学習過程がどのように相違・類似しているかは解明されておらず、活用されてきませんでした。
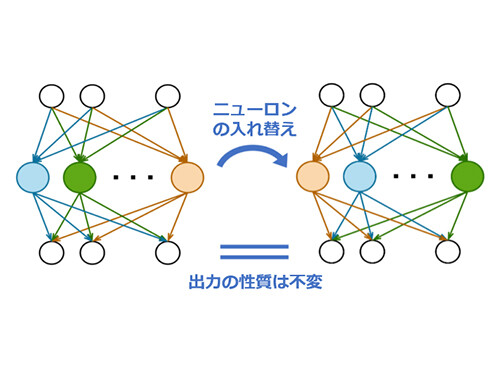
NTTでは、ニューラルネットワークのパラメータ空間にある高い対称性に着目し、とくに置換変換と呼ばれるニューロンの入れ替えに関する対称性(図1)の下で、異なるモデル間の学習過程同士を近似的に同一視できることを発見しました。この発見に基づき、過去の学習過程を適切な置換対称性(*5)によって変換することで、新たなモデルの学習過程として再利用できる「学習転移」技術を世界で初めて提唱および実証しました(図2)。
-
図1 置換変換による対称性
-
図2 学習転移の概要
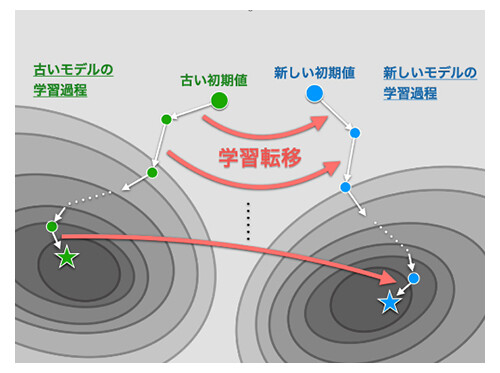
学習転移では、高コストな学習を行うことなく、低コストな変換のみにより一定の精度を達成することができます。さらに学習転移後に追加の学習を行うことで、目標精度に早く収束することも示しました(図3)。
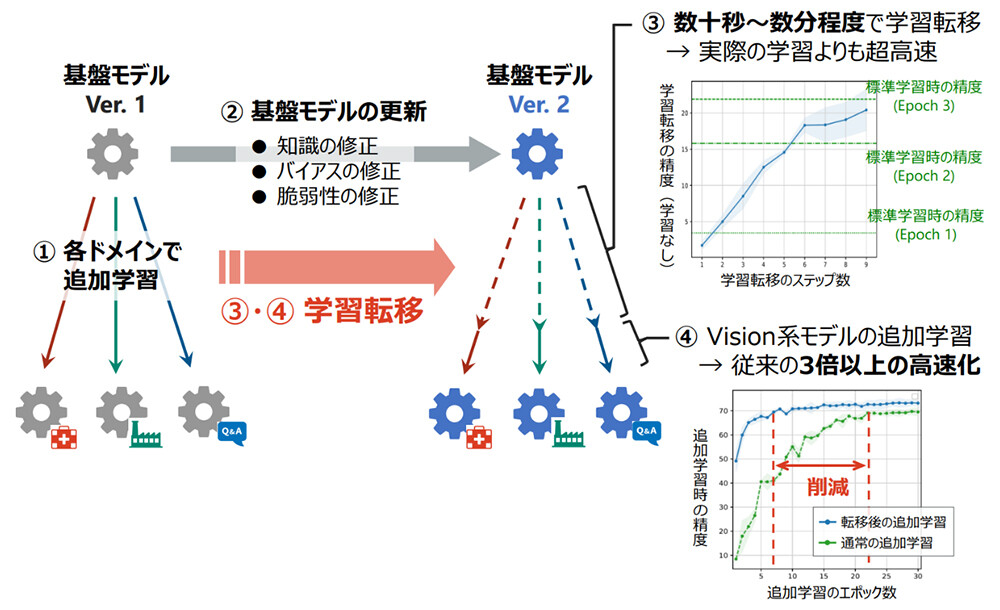 図3 基盤モデル更新時の学習高速化
図3 基盤モデル更新時の学習高速化
3. 技術のポイント
ポイント① 学習転移の定式化
学習転移は、2つのパラメータ初期値が与えられたときに、一方の初期値に対する学習過程(以下、ソース)を変換したときにもう一方の初期値の学習過程(以下、ターゲット)との距離を最小化するような置換変換を求める、最適化問題として定式化されました。このように2つの学習過程間の変換を最適化するという枠組み自体が、本研究により世界で初めて提案されたものになります。
ポイント② 高速なアルゴリズムの導出
上記の最適化問題に現れるターゲットの学習過程は、そもそも学習転移によって求めたかったものであり事前には未知であるため、そのままでは実際の計算機上で扱うことはできませんでした。そこで学習過程の各ステップが勾配で近似できるという仮定を置くことで、実際に計算機で扱える非線形最適化問題を導出しました。また非線形性のために、そのままでは効率的に解くことができませんでしたが、学習過程の部分的な転移と線形最適化とを交互に行うことにより、高速に解くことが可能となりました。
ポイント③ 理論的分析
2層ニューラルネットワークの数理モデルにおいて、ネットワークサイズが大きくなればなるほど、最適な置換変換が高い確率で存在し、ソースの初期学習過程を変換することでターゲットの初期学習過程にいくらでも近づけられることを証明しました。この結果は、ニューラルネットワークが大規模になるほど、実際に学習転移が可能となることを理論的に示しています。
4. 今後の予定
本成果は、深層学習における新たな学習手法の基礎理論を確立し、その応用として基盤モデル更新・変更時のチューニングコストを大幅に低減できる可能性を明らかにしました。これにより、NTTが研究開発を進める大規模言語モデル(LLM)「tsuzumi」をはじめとした多様な基盤モデルの運用コスト削減・環境負荷軽減や、多数のAIで議論することで多様な解の創出をめざしたAIコンステレーションの構想具現化など、次世代のAI技術開発に貢献します。
発表について:
本成果は、2024年5月7~11日に開催される機械学習分野における最難関国際会議ICLR 2024(The Twelfth International Conference on Learning Representations)にて、下記のタイトル及び著者で発表されます。
タイトル: Transferring Learning Trajectories of Neural Networks
著者: 千々和 大輝(コンピュータ&データサイエンス研究所)
URL: https://openreview.net/forum?id=bWNJFD1l8M![]()
用語解説
(*1)tsuzumi
NTT版大規模言語モデル。日本語の処理性能を重視し、独自の大量のテキストデータを使って学習された言語モデル。詳細は、報道発表をご参照ください。
URL: https://www.rd.ntt/research/LLM_tsuzumi.html![]()
(*2)基盤モデル
大量のデータを用いて学習され、様々なドメイン特化モデルを作成する際にベースとなるAIモデル。
(*3)AIコンステレーション
LLMなど多様なAIモデルやルールを環境として与えることで、AI同士が相互に議論・訂正を行い、多様な視点から解を創出する大規模AI連携技術。詳細は、報道発表をご参照ください。
URL: https://group.ntt/jp/newsrelease/2023/11/13/pdf/231113ba.pdf
(*4)ICLR 2024
機械学習に関するトップレベルの国際会議。
URL: https://iclr.cc/Conferences/2024![]()
(*5)置換対称性
ニューロンの入れ替えによりパラメータが変わっても、全体の出力は変わらないという性質のこと。
本件に関する報道機関からのお問い合わせ先
日本電信電話株式会社
サービスイノベーション総合研究所
企画部広報担当
nttrd-pr@ml.ntt.com
ニュースリリースに記載している情報は、発表日時点のものです。
現時点では、発表日時点での情報と異なる場合がありますので、あらかじめご了承いただくとともに、ご注意をお願いいたします。
NTT STORY
NTTとともに未来を考えるWEBメディアです。










